Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional WaveGAN
Sep 27, 2018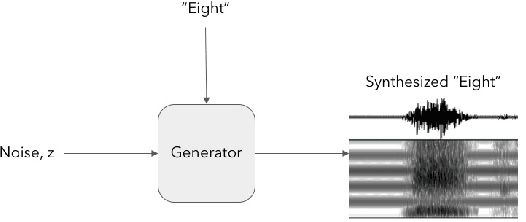

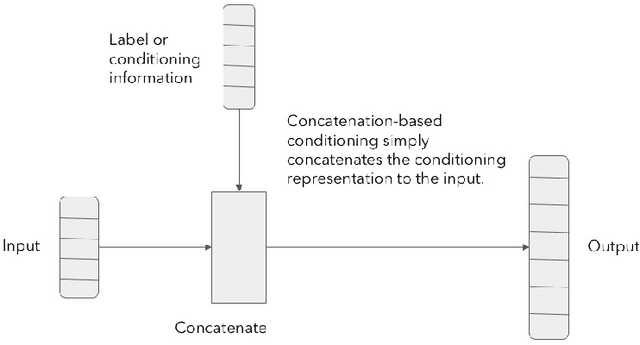
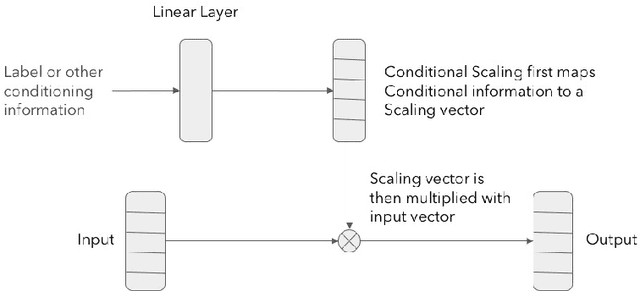
Generative models are successfully used for image synthesis in the recent years. But when it comes to other modalities like audio, text etc little progress has been made. Recent works focus on generating audio from a generative model in an unsupervised setting. We explore the possibility of using generative models conditioned on class labels. Concatenation based conditioning and conditional scaling were explored in this work with various hyper-parameter tuning methods. In this paper we introduce Conditional WaveGANs (cWaveGAN). Find our implementation at https://github.com/acheketa/cwavegan
* Preprint
Via