 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
Open Ko-LLM Leaderboard: Evaluating Large Language Models in Korean with Ko-H5 Benchmark
May 31, 2024This paper introduces the Open Ko-LLM Leaderboard and the Ko-H5 Benchmark as vital tools for evaluating Large Language Models (LLMs) in Korean. Incorporating private test sets while mirroring the English Open LLM Leaderboard, we establish a robust evaluation framework that has been well integrated in the Korean LLM community. We perform data leakage analysis that shows the benefit of private test sets along with a correlation study within the Ko-H5 benchmark and temporal analyses of the Ko-H5 score. Moreover, we present empirical support for the need to expand beyond set benchmarks. We hope the Open Ko-LLM Leaderboard sets precedent for expanding LLM evaluation to foster more linguistic diversity.
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Dec 29, 2023



We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for scaling LLMs called depth up-scaling (DUS), which encompasses depthwise scaling and continued pretraining. In contrast to other LLM up-scaling methods that use mixture-of-experts, DUS does not require complex changes to train and inference efficiently. We show experimentally that DUS is simple yet effective in scaling up high-performance LLMs from small ones. Building on the DUS model, we additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B-Instruct. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.
Character Region Attention For Text Spotting
Jul 19, 2020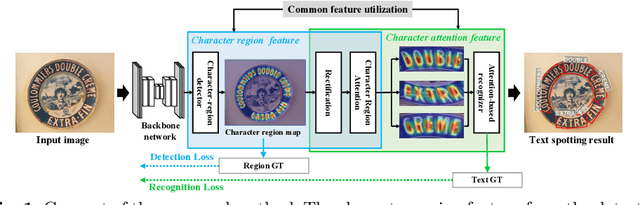

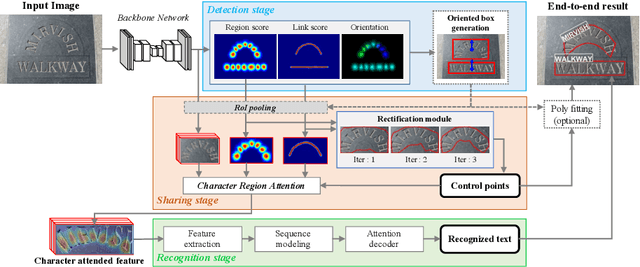
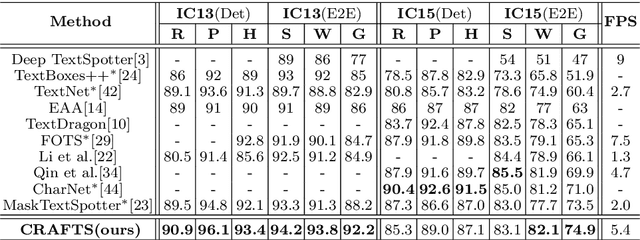
A scene text spotter is composed of text detection and recognition modules. Many studies have been conducted to unify these modules into an end-to-end trainable model to achieve better performance. A typical architecture places detection and recognition modules into separate branches, and a RoI pooling is commonly used to let the branches share a visual feature. However, there still exists a chance of establishing a more complimentary connection between the modules when adopting recognizer that uses attention-based decoder and detector that represents spatial information of the character regions. This is possible since the two modules share a common sub-task which is to find the location of the character regions. Based on the insight, we construct a tightly coupled single pipeline model. This architecture is formed by utilizing detection outputs in the recognizer and propagating the recognition loss through the detection stage. The use of character score map helps the recognizer attend better to the character center points, and the recognition loss propagation to the detector module enhances the localization of the character regions. Also, a strengthened sharing stage allows feature rectification and boundary localization of arbitrary-shaped text regions. Extensive experiments demonstrate state-of-the-art performance in publicly available straight and curved benchmark dataset.
CLEval: Character-Level Evaluation for Text Detection and Recognition Tasks
Jun 11, 2020



Despite the recent success of text detection and recognition methods, existing evaluation metrics fail to provide a fair and reliable comparison among those methods. In addition, there exists no end-to-end evaluation metric that takes characteristics of OCR tasks into account. Previous end-to-end metric contains cascaded errors from the binary scoring process applied in both detection and recognition tasks. Ignoring partially correct results raises a gap between quantitative and qualitative analysis, and prevents fine-grained assessment. Based on the fact that character is a key element of text, we hereby propose a Character-Level Evaluation metric (CLEval). In CLEval, the \textit{instance matching} process handles split and merge detection cases, and the \textit{scoring process} conducts character-level evaluation. By aggregating character-level scores, the CLEval metric provides a fine-grained evaluation of end-to-end results composed of the detection and recognition as well as individual evaluations for each module from the end-performance perspective. We believe that our metrics can play a key role in developing and analyzing state-of-the-art text detection and recognition methods. The evaluation code is publicly available at https://github.com/clovaai/CLEval.
Few-shot Compositional Font Generation with Dual Memory
May 21, 2020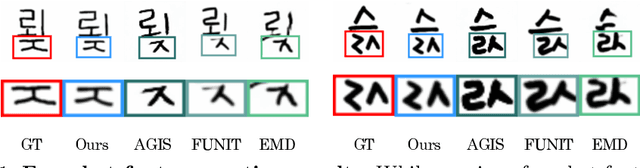
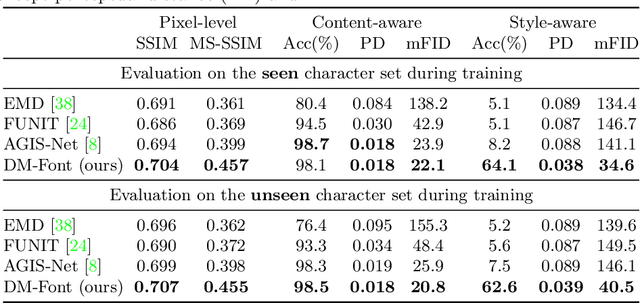
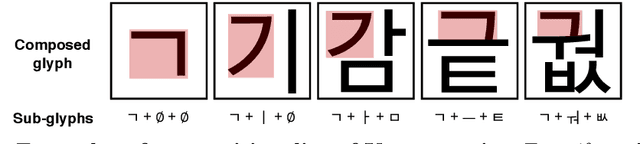
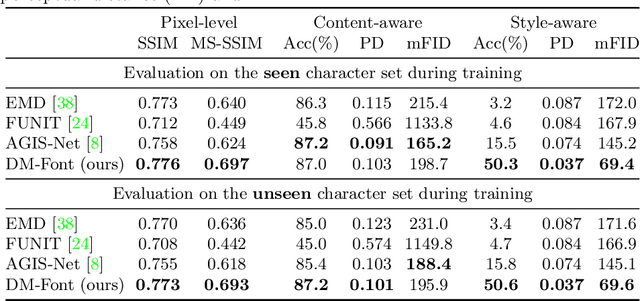
Generating a new font library is a very labor-intensive and time-consuming job for glyph-rich scripts. Despite the remarkable success of existing font generation methods, they have significant drawbacks; they require a large number of reference images to generate a new font set, or they fail to capture detailed styles with a few samples. In this paper, we focus on compositional scripts, a widely used letter system in the world, where each glyph can be decomposed by several components. By utilizing the compositionality of compositional scripts, we propose a novel font generation framework, named Dual Memory-augmented Font Generation Network (DM-Font), which enables us to generate a high-quality font library with only a few samples. We employ memory components and global-context awareness in the generator to take advantage of the compositionality. In the experiments on Korean-handwriting fonts and Thai-printing fonts, we observe that our method generates a significantly better quality of samples with faithful stylization compared to the state-of-the-art generation methods in quantitatively and qualitatively.
On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
Oct 10, 2019



Scene text recognition (STR) is the task of recognizing character sequences in natural scenes. While there have been great advances in STR methods, current methods still fail to recognize texts in arbitrary shapes, such as heavily curved or rotated texts, which are abundant in daily life (e.g. restaurant signs, product labels, company logos, etc). This paper introduces a novel architecture to recognizing texts of arbitrary shapes, named Self-Attention Text Recognition Network (SATRN), which is inspired by the Transformer. SATRN utilizes the self-attention mechanism to describe two-dimensional (2D) spatial dependencies of characters in a scene text image. Exploiting the full-graph propagation of self-attention, SATRN can recognize texts with arbitrary arrangements and large inter-character spacing. As a result, SATRN outperforms existing STR models by a large margin of 5.7 pp on average in "irregular text" benchmarks. We provide empirical analyses that illustrate the inner mechanisms and the extent to which the model is applicable (e.g. rotated and multi-line text). We will open-source the code.
TedEval: A Fair Evaluation Metric for Scene Text Detectors
Jul 02, 2019

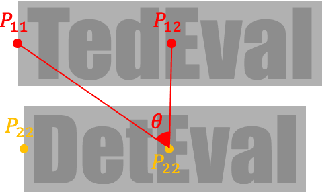
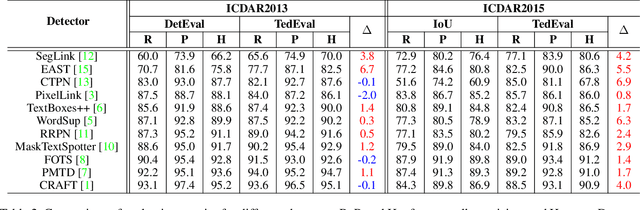
Despite the recent success of scene text detection methods, common evaluation metrics fail to provide a fair and reliable comparison among detectors. They have obvious drawbacks in reflecting the inherent characteristic of text detection tasks, unable to address issues such as granularity, multiline, and character incompleteness. In this paper, we propose a novel evaluation protocol called TedEval (Text detector Evaluation), which evaluates text detections by an instance-level matching and a character-level scoring. Based on a firm standard rewarding behaviors that result in successful recognition, TedEval can act as a reliable standard for comparing and quantizing the detection quality throughout all difficulty levels. In this regard, we believe that TedEval can play a key role in developing state-of-the-art scene text detectors. The code is publicly available at https://github.com/clovaai/TedEval.
Character Region Awareness for Text Detection
Apr 03, 2019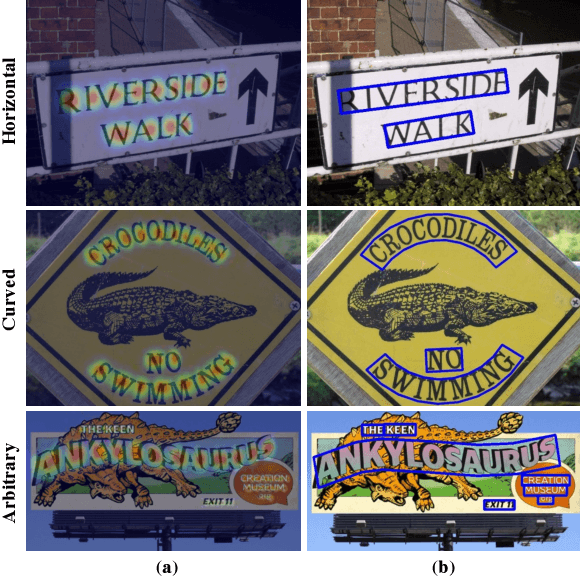
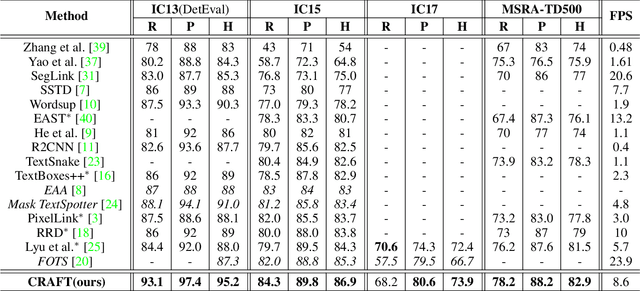
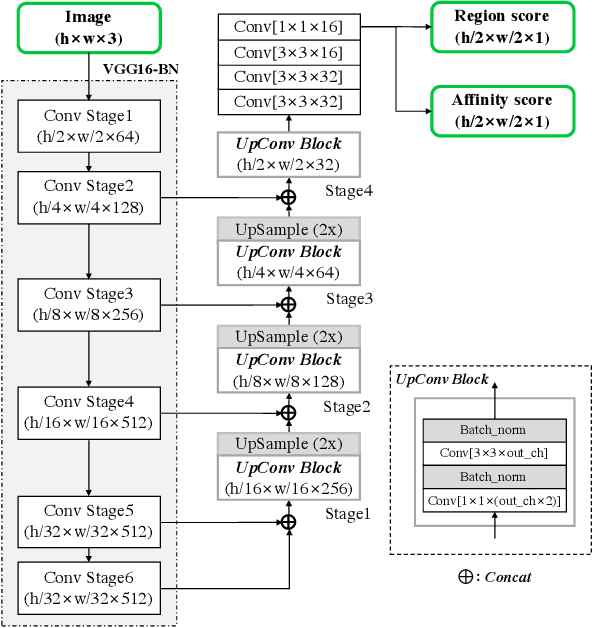
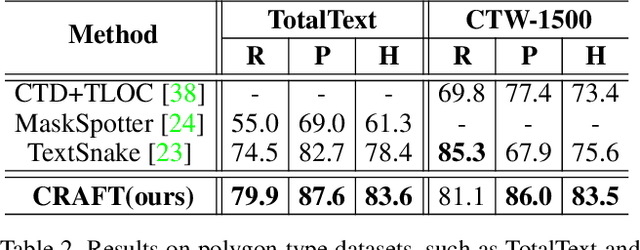
Scene text detection methods based on neural networks have emerged recently and have shown promising results. Previous methods trained with rigid word-level bounding boxes exhibit limitations in representing the text region in an arbitrary shape. In this paper, we propose a new scene text detection method to effectively detect text area by exploring each character and affinity between characters. To overcome the lack of individual character level annotations, our proposed framework exploits both the given character-level annotations for synthetic images and the estimated character-level ground-truths for real images acquired by the learned interim model. In order to estimate affinity between characters, the network is trained with the newly proposed representation for affinity. Extensive experiments on six benchmarks, including the TotalText and CTW-1500 datasets which contain highly curved texts in natural images, demonstrate that our character-level text detection significantly outperforms the state-of-the-art detectors. According to the results, our proposed method guarantees high flexibility in detecting complicated scene text images, such as arbitrarily-oriented, curved, or deformed texts.
What is wrong with scene text recognition model comparisons? dataset and model analysis
Apr 03, 2019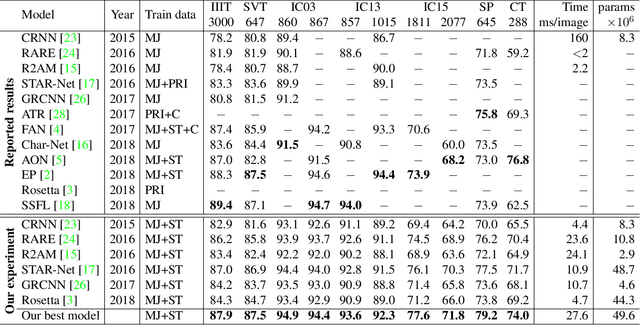



Many new proposals for scene text recognition (STR) models have been introduced in recent years. While each claim to have pushed the boundary of the technology, a holistic and fair comparison has been largely missing in the field due to the inconsistent choices of training and evaluation datasets. This paper addresses this difficulty with three major contributions. First, we examine the inconsistencies of training and evaluation datasets, and the performance gap results from inconsistencies. Second, we introduce a unified four-stage STR framework that most existing STR models fit into. Using this framework allows for the extensive evaluation of previously proposed STR modules and the discovery of previously unexplored module combinations. Third, we analyze the module-wise contributions to performance in terms of accuracy, speed, and memory demand, under one consistent set of training and evaluation datasets. Such analyses clean up the hindrance on the current comparisons to understand the performance gain of the existing modules.