 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREPE: Coordinate-Aware End-to-End Document Parser
May 01, 2024



In this study, we formulate an OCR-free sequence generation model for visual document understanding (VDU). Our model not only parses text from document images but also extracts the spatial coordinates of the text based on the multi-head architecture. Named as Coordinate-aware End-to-end Document Parser (CREPE), our method uniquely integrates these capabilities by introducing a special token for OCR text, and token-triggered coordinate decoding. We also proposed a weakly-supervised framework for cost-efficient training, requiring only parsing annotations without high-cost coordinate annotations. Our experimental evaluations demonstrate CREPE's state-of-the-art performances on document parsing tasks. Beyond that, CREPE's adaptability is further highlighted by its successful usage in other document understanding tasks such as layout analysis, document visual question answering, and so one. CREPE's abilities including OCR and semantic parsing not only mitigate error propagation issues in existing OCR-dependent methods, it also significantly enhance the functionality of sequence generation models, ushering in a new era for document understanding studies.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Cream: Visually-Situated Natural Language Understanding with Contrastive Reading Model and Frozen Large Language Models
May 24, 2023
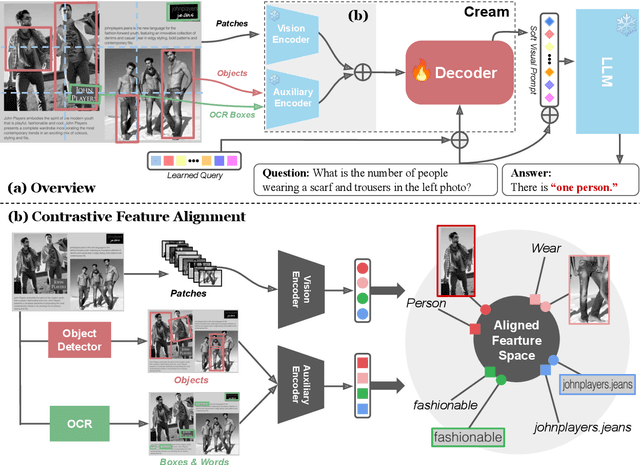

Advances in Large Language Models (LLMs) have inspired a surge of research exploring their expansion into the visual domain. While recent models exhibit promise in generating abstract captions for images and conducting natural conversations, their performance on text-rich images leaves room for improvement. In this paper, we propose the Contrastive Reading Model (Cream), a novel neural architecture designed to enhance the language-image understanding capability of LLMs by capturing intricate details typically overlooked by existing methods. Cream integrates vision and auxiliary encoders, complemented by a contrastive feature alignment technique, resulting in a more effective understanding of textual information within document images. Our approach, thus, seeks to bridge the gap between vision and language understanding, paving the way for more sophisticated Document Intelligence Assistants. Rigorous evaluations across diverse tasks, such as visual question answering on document images, demonstrate the efficacy of Cream as a state-of-the-art model in the field of visual document understanding. We provide our codebase and newly-generated datasets at https://github.com/naver-ai/cream
DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting
Mar 10, 2022
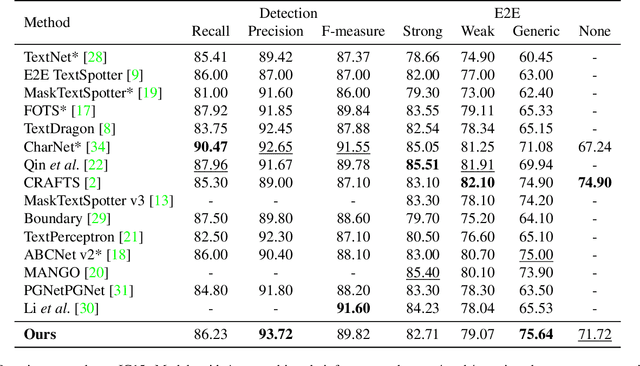
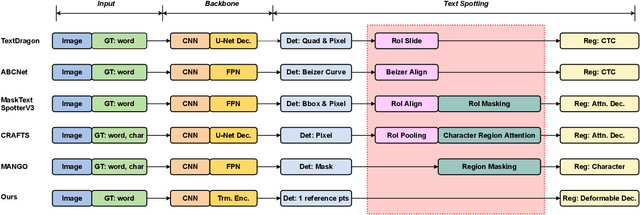
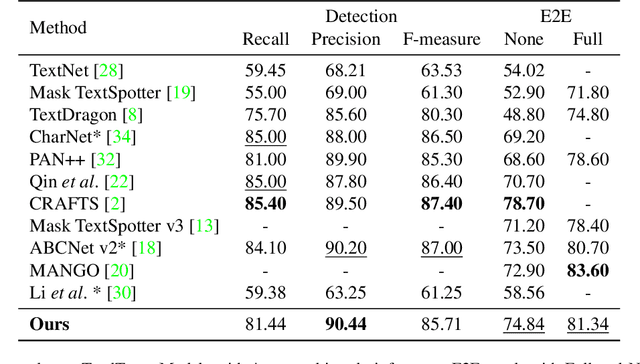
Recent end-to-end scene text spotters have achieved great improvement in recognizing arbitrary-shaped text instances. Common approaches for text spotting use region of interest pooling or segmentation masks to restrict features to single text instances. However, this makes it hard for the recognizer to decode correct sequences when the detection is not accurate i.e. one or more characters are cropped out. Considering that it is hard to accurately decide word boundaries with only the detector, we propose a novel Detection-agnostic End-to-End Recognizer, DEER, framework. The proposed method reduces the tight dependency between detection and recognition modules by bridging them with a single reference point for each text instance, instead of using detected regions. The proposed method allows the decoder to recognize the texts that are indicated by the reference point, with features from the whole image. Since only a single point is required to recognize the text, the proposed method enables text spotting without an arbitrarily-shaped detector or bounding polygon annotations. Experimental results present that the proposed method achieves competitive results on regular and arbitrarily-shaped text spotting benchmarks. Further analysis shows that DEER is robust to the detection errors. The code and dataset will be publicly available.
Few-shot Font Generation with Weakly Supervised Localized Representations
Dec 22, 2021

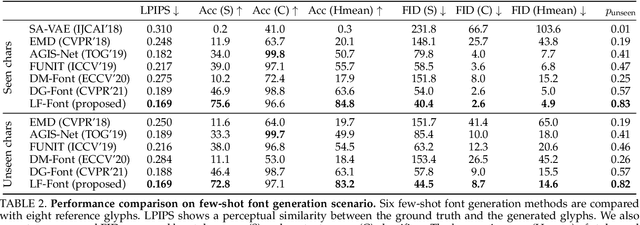
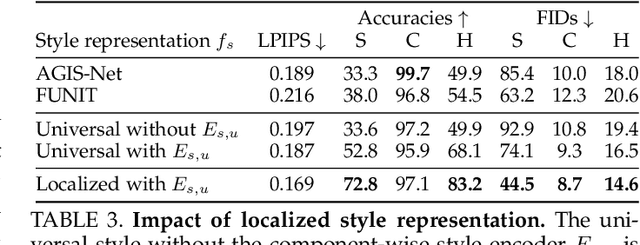
Automatic few-shot font generation aims to solve a well-defined, real-world problem because manual font designs are expensive and sensitive to the expertise of designers. Existing methods learn to disentangle style and content elements by developing a universal style representation for each font style. However, this approach limits the model in representing diverse local styles, because it is unsuitable for complicated letter systems, for example, Chinese, whose characters consist of a varying number of components (often called "radical") -- with a highly complex structure. In this paper, we propose a novel font generation method that learns localized styles, namely component-wise style representations, instead of universal styles. The proposed style representations enable the synthesis of complex local details in text designs. However, learning component-wise styles solely from a few reference glyphs is infeasible when a target script has a large number of components, for example, over 200 for Chinese. To reduce the number of required reference glyphs, we represent component-wise styles by a product of component and style factors, inspired by low-rank matrix factorization. Owing to the combination of strong representation and a compact factorization strategy, our method shows remarkably better few-shot font generation results (with only eight reference glyphs) than other state-of-the-art methods. Moreover, strong locality supervision, for example, location of each component, skeleton, or strokes, was not utilized. The source code is available at https://github.com/clovaai/lffont and https://github.com/clovaai/fewshot-font-generation.
Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts
Apr 02, 2021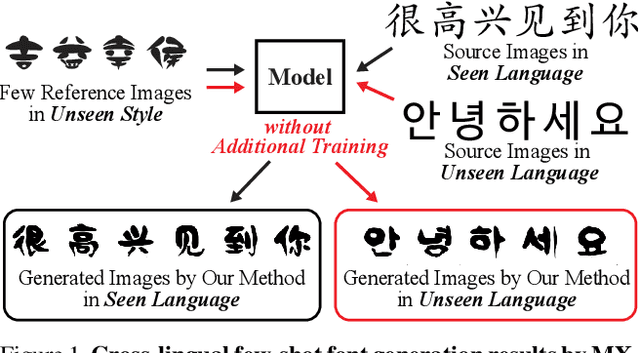
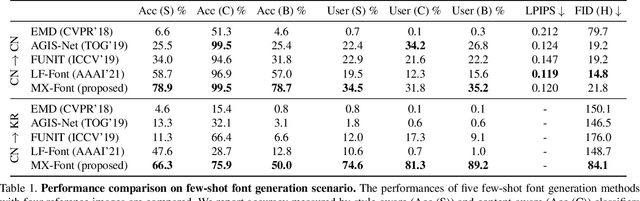
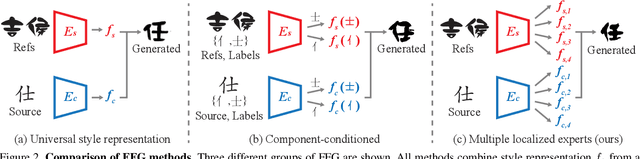

A few-shot font generation (FFG) method has to satisfy two objectives: the generated images should preserve the underlying global structure of the target character and present the diverse local reference style. Existing FFG methods aim to disentangle content and style either by extracting a universal representation style or extracting multiple component-wise style representations. However, previous methods either fail to capture diverse local styles or cannot be generalized to a character with unseen components, e.g., unseen language systems. To mitigate the issues, we propose a novel FFG method, named Multiple Localized Experts Few-shot Font Generation Network (MX-Font). MX-Font extracts multiple style features not explicitly conditioned on component labels, but automatically by multiple experts to represent different local concepts, e.g., left-side sub-glyph. Owing to the multiple experts, MX-Font can capture diverse local concepts and show the generalizability to unseen languages. During training, we utilize component labels as weak supervision to guide each expert to be specialized for different local concepts. We formulate the component assign problem to each expert as the graph matching problem, and solve it by the Hungarian algorithm. We also employ the independence loss and the content-style adversarial loss to impose the content-style disentanglement. In our experiments, MX-Font outperforms previous state-of-the-art FFG methods in the Chinese generation and cross-lingual, e.g., Chinese to Korean, generation. Source code is available at https://github.com/clovaai/mxfont.
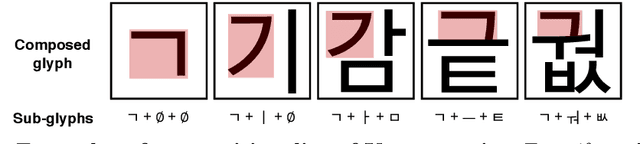
Few-shot Font Generation with Localized Style Representations and Factorization
Sep 23, 2020
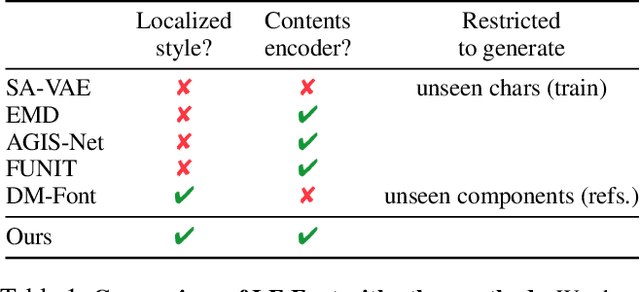
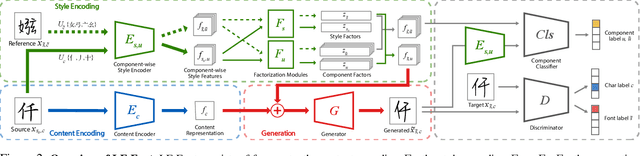
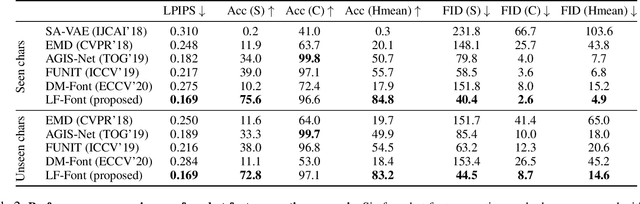
Automatic few-shot font generation is in high demand because manual designs are expensive and sensitive to the expertise of designers. Existing few-shot font generation methods aim to learn to disentangle the style and content element from a few reference glyphs, and mainly focus on a universal style representation for each font style. However, such approach limits the model in representing diverse local styles, and thus makes it unsuitable to the most complicated letter system, e.g., Chinese, whose characters consist of a varying number of components (often called "radical") with a highly complex structure. In this paper, we propose a novel font generation method by learning localized styles, namely component-wise style representations, instead of universal styles. The proposed style representations enable us to synthesize complex local details in text designs. However, learning component-wise styles solely from reference glyphs is infeasible in the few-shot font generation scenario, when a target script has a large number of components, e.g., over 200 for Chinese. To reduce the number of reference glyphs, we simplify component-wise styles by a product of component factor and style factor, inspired by low-rank matrix factorization. Thanks to the combination of strong representation and a compact factorization strategy, our method shows remarkably better few-shot font generation results (with only 8 reference glyph images) than other state-of-the-arts, without utilizing strong locality supervision, e.g., location of each component, skeleton, or strokes. The source code is available at https://github.com/clovaai/lffont.
Few-shot Compositional Font Generation with Dual Memory
May 21, 2020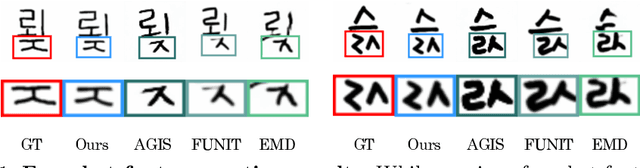
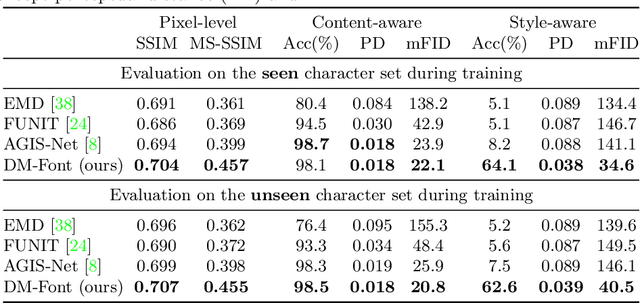
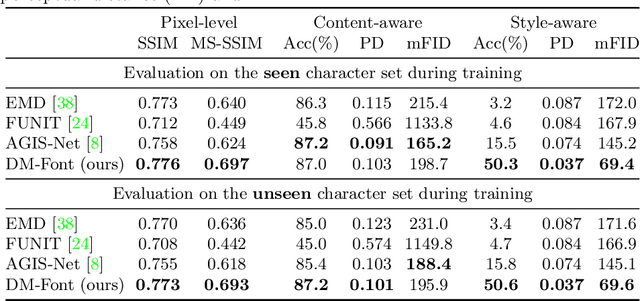
Generating a new font library is a very labor-intensive and time-consuming job for glyph-rich scripts. Despite the remarkable success of existing font generation methods, they have significant drawbacks; they require a large number of reference images to generate a new font set, or they fail to capture detailed styles with a few samples. In this paper, we focus on compositional scripts, a widely used letter system in the world, where each glyph can be decomposed by several components. By utilizing the compositionality of compositional scripts, we propose a novel font generation framework, named Dual Memory-augmented Font Generation Network (DM-Font), which enables us to generate a high-quality font library with only a few samples. We employ memory components and global-context awareness in the generator to take advantage of the compositionality. In the experiments on Korean-handwriting fonts and Thai-printing fonts, we observe that our method generates a significantly better quality of samples with faithful stylization compared to the state-of-the-art generation methods in quantitatively and qualitatively.
Character Region Awareness for Text Detection
Apr 03, 2019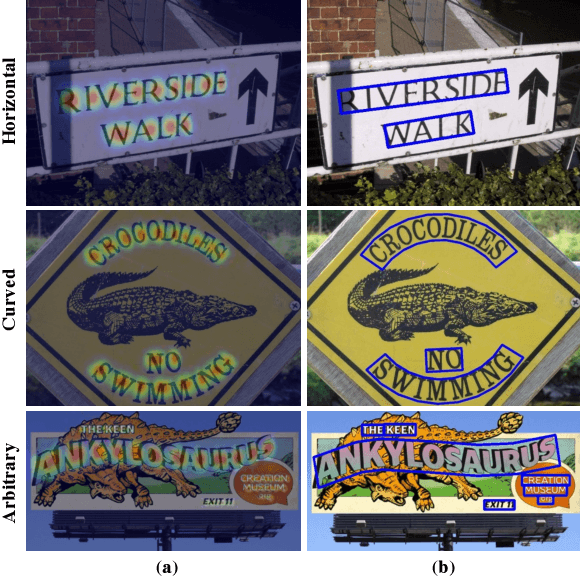
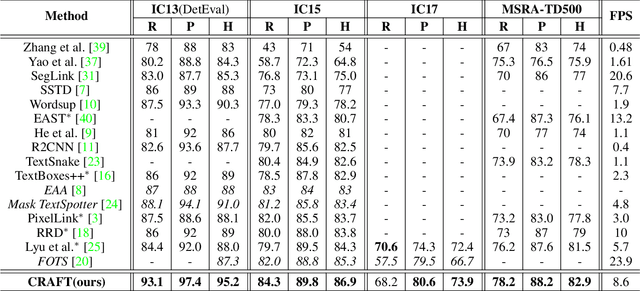
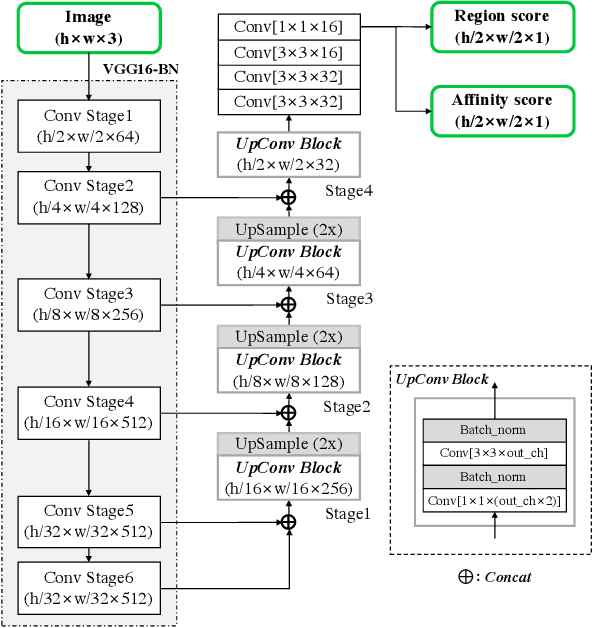
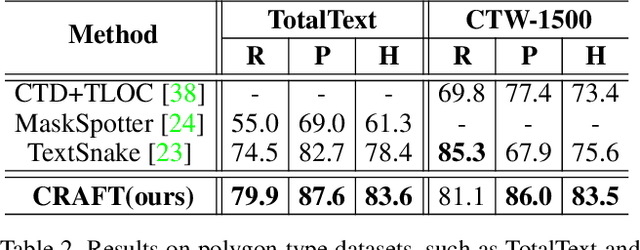
Scene text detection methods based on neural networks have emerged recently and have shown promising results. Previous methods trained with rigid word-level bounding boxes exhibit limitations in representing the text region in an arbitrary shape. In this paper, we propose a new scene text detection method to effectively detect text area by exploring each character and affinity between characters. To overcome the lack of individual character level annotations, our proposed framework exploits both the given character-level annotations for synthetic images and the estimated character-level ground-truths for real images acquired by the learned interim model. In order to estimate affinity between characters, the network is trained with the newly proposed representation for affinity. Extensive experiments on six benchmarks, including the TotalText and CTW-1500 datasets which contain highly curved texts in natural images, demonstrate that our character-level text detection significantly outperforms the state-of-the-art detectors. According to the results, our proposed method guarantees high flexibility in detecting complicated scene text images, such as arbitrarily-oriented, curved, or deformed texts.