 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhantomBench: Benchmarking the Non-existential Threat of Language Models
Jun 09, 2026Hallucinations, where language models (LMs) generate factually ungrounded responses, pose serious risks, as users tend to blindly rely on them. This is particularly concerning in high-stakes domains, where consequences of such model behavior can lead to significant harms. Despite notable progress in understanding hallucinations, it remains unclear how reliably these models can recognize the limits of their knowledge. We introduce PhantomBench, the first large-scale benchmark of its kind, comprising more than 60K non-existent terms and entities derived from real concepts across diverse domains. Using our benchmark, we evaluate a total of 21 models of various types and sizes. We show staggering hallucination rates across the board (with average rates as high as 86.7% in some cases), and note that even frontier models surprisingly fail to abstain on non-existent concepts, especially when the input presumes their existence. We then show that PhantomBench can serve as a proxy for studying model behavior on rare concepts for which models are more prone to hallucinate. We also provide a pipeline to construct PhantomBench, enabling scalable generation of non-existent concepts tailored to the specific needs of researchers and practitioners.
Harnessing Linguistic Dissimilarity for Language Generalization on Unseen Low-Resource Varieties
May 06, 2026Low-resource language varieties used by specific groups remain neglected in the development of Multilingual Language Models. A great deal of cross-lingual research focuses on inter-lingual language transfer which strives to align allied varieties and minimize differences between them. However, for low-resource varieties, linguistic dissimilarity is also an important cue allowing generalization to unseen varieties. Unlike prior approaches, we propose a two-stage Language Generalization framework that focuses on capturing variety-specific cues while also exploiting rich overlap offered by high-resource source variety. First, we propose TOPPing, a source-selection method specifically designed for low-resource varieties. Second, we suggest a lightweight VACAI-Bowl architecture that learns variety-specific attributes with one branch while a parallel branch captures variety-invariant attributes using adversarial training. We evaluate our framework on structural prediction tasks, which are among the few tasks available, as proxy for performance on other downstream tasks. Using VACAI-Bowl with TOPPing yields an average 54.62% improvement in the dependency parsing task, which serves as a proxy for performance on other downstream tasks across 10 low-resource varieties.
VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions
Jul 17, 2024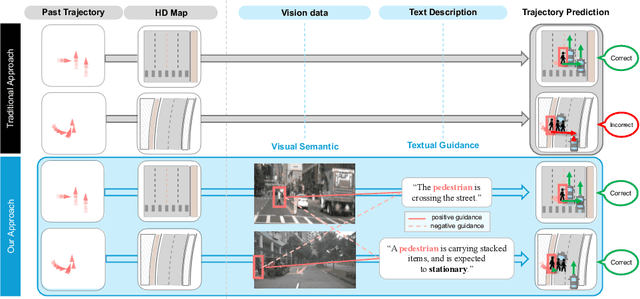
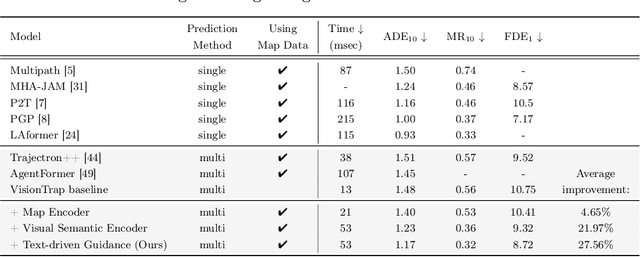

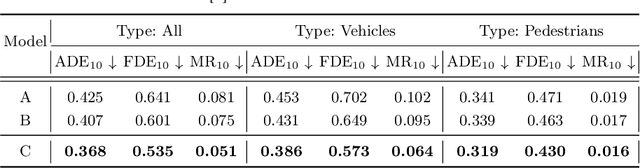
Predicting future trajectories for other road agents is an essential task for autonomous vehicles. Established trajectory prediction methods primarily use agent tracks generated by a detection and tracking system and HD map as inputs. In this work, we propose a novel method that also incorporates visual input from surround-view cameras, allowing the model to utilize visual cues such as human gazes and gestures, road conditions, vehicle turn signals, etc, which are typically hidden from the model in prior methods. Furthermore, we use textual descriptions generated by a Vision-Language Model (VLM) and refined by a Large Language Model (LLM) as supervision during training to guide the model on what to learn from the input data. Despite using these extra inputs, our method achieves a latency of 53 ms, making it feasible for real-time processing, which is significantly faster than that of previous single-agent prediction methods with similar performance. Our experiments show that both the visual inputs and the textual descriptions contribute to improvements in trajectory prediction performance, and our qualitative analysis highlights how the model is able to exploit these additional inputs. Lastly, in this work we create and release the nuScenes-Text dataset, which augments the established nuScenes dataset with rich textual annotations for every scene, demonstrating the positive impact of utilizing VLM on trajectory prediction. Our project page is at https://moonseokha.github.io/VisionTrap/
Zero-Shot Cross-Lingual NER Using Phonemic Representations for Low-Resource Languages
Jun 23, 2024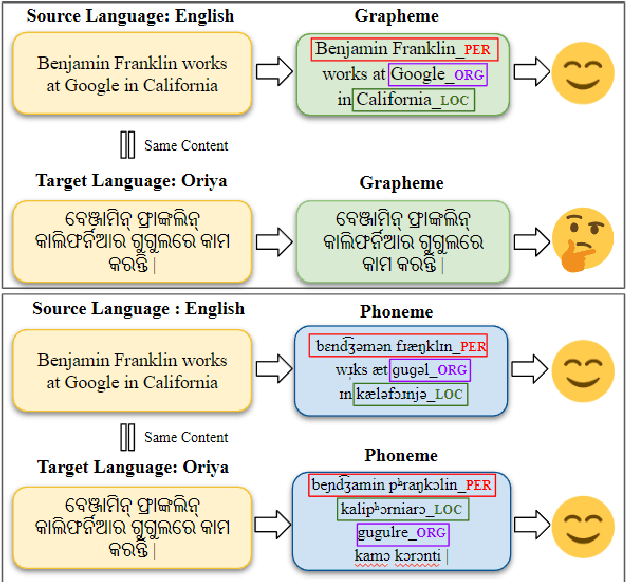



Existing zero-shot cross-lingual NER approaches require substantial prior knowledge of the target language, which is impractical for low-resource languages. In this paper, we propose a novel approach to NER using phonemic representation based on the International Phonetic Alphabet (IPA) to bridge the gap between representations of different languages. Our experiments show that our method significantly outperforms baseline models in extremely low-resource languages, with the highest average F-1 score (46.38%) and lowest standard deviation (12.67), particularly demonstrating its robustness with non-Latin scripts.
Mitigating the Linguistic Gap with Phonemic Representations for Robust Multilingual Language Understanding
Feb 22, 2024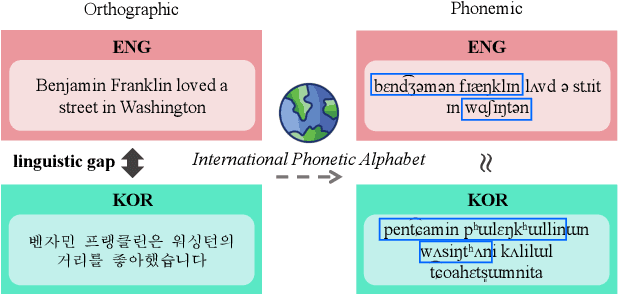
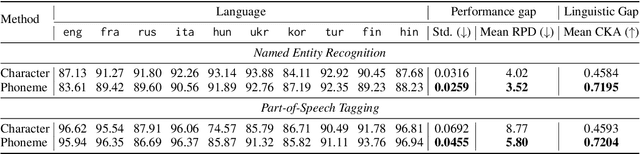
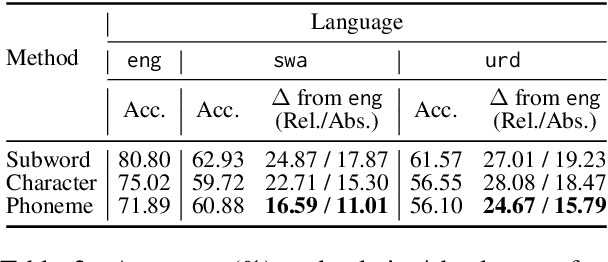
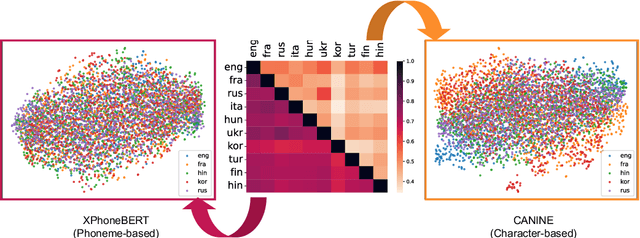
Approaches to improving multilingual language understanding often require multiple languages during the training phase, rely on complicated training techniques, and -- importantly -- struggle with significant performance gaps between high-resource and low-resource languages. We hypothesize that the performance gaps between languages are affected by linguistic gaps between those languages and provide a novel solution for robust multilingual language modeling by employing phonemic representations (specifically, using phonemes as input tokens to LMs rather than subwords). We present quantitative evidence from three cross-lingual tasks that demonstrate the effectiveness of phonemic representation, which is further justified by a theoretical analysis of the cross-lingual performance gap.
Cream: Visually-Situated Natural Language Understanding with Contrastive Reading Model and Frozen Large Language Models
May 24, 2023
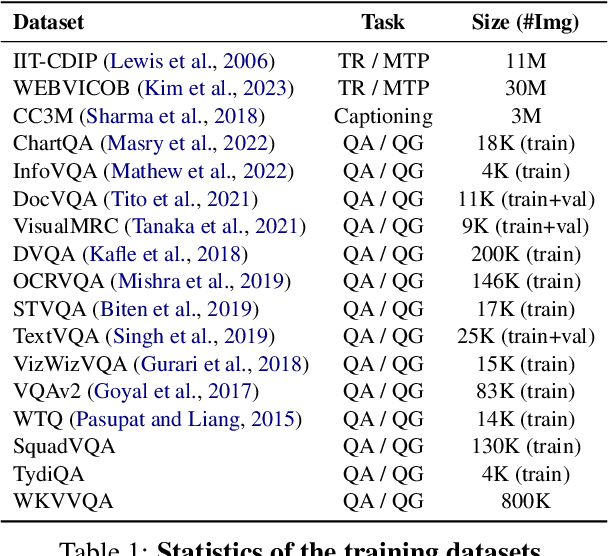
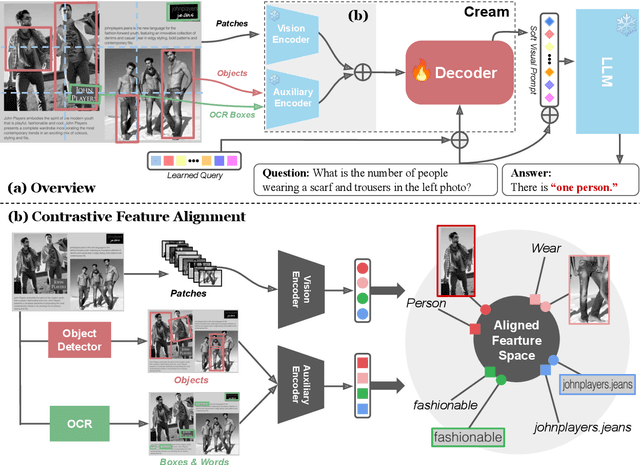

Advances in Large Language Models (LLMs) have inspired a surge of research exploring their expansion into the visual domain. While recent models exhibit promise in generating abstract captions for images and conducting natural conversations, their performance on text-rich images leaves room for improvement. In this paper, we propose the Contrastive Reading Model (Cream), a novel neural architecture designed to enhance the language-image understanding capability of LLMs by capturing intricate details typically overlooked by existing methods. Cream integrates vision and auxiliary encoders, complemented by a contrastive feature alignment technique, resulting in a more effective understanding of textual information within document images. Our approach, thus, seeks to bridge the gap between vision and language understanding, paving the way for more sophisticated Document Intelligence Assistants. Rigorous evaluations across diverse tasks, such as visual question answering on document images, demonstrate the efficacy of Cream as a state-of-the-art model in the field of visual document understanding. We provide our codebase and newly-generated datasets at https://github.com/naver-ai/cream