 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAUQ: Vision-Aware Uncertainty Quantification for LVLM Self-Evaluation
Feb 24, 2026Large Vision-Language Models (LVLMs) frequently hallucinate, limiting their safe deployment in real-world applications. Existing LLM self-evaluation methods rely on a model's ability to estimate the correctness of its own outputs, which can improve deployment reliability; however, they depend heavily on language priors and are therefore ill-suited for evaluating vision-conditioned predictions. We propose VAUQ, a vision-aware uncertainty quantification framework for LVLM self-evaluation that explicitly measures how strongly a model's output depends on visual evidence. VAUQ introduces the Image-Information Score (IS), which captures the reduction in predictive uncertainty attributable to visual input, and an unsupervised core-region masking strategy that amplifies the influence of salient regions. Combining predictive entropy with this core-masked IS yields a training-free scoring function that reliably reflects answer correctness. Comprehensive experiments show that VAUQ consistently outperforms existing self-evaluation methods across multiple datasets.
Thinking Makes LLM Agents Introverted: How Mandatory Thinking Can Backfire in User-Engaged Agents
Feb 08, 2026Eliciting reasoning has emerged as a powerful technique for improving the performance of large language models (LLMs) on complex tasks by inducing thinking. However, their effectiveness in realistic user-engaged agent scenarios remains unclear. In this paper, we conduct a comprehensive study on the effect of explicit thinking in user-engaged LLM agents. Our experiments span across seven models, three benchmarks, and two thinking instantiations, and we evaluate them through both a quantitative response taxonomy analysis and qualitative failure propagation case studies. Contrary to expectations, we find that mandatory thinking often backfires on agents in user-engaged settings, causing anomalous performance degradation across various LLMs. Our key finding reveals that thinking makes agents more ``introverted'' by shortening responses and reducing information disclosure to users, which weakens agent-user information exchange and leads to downstream task failures. Furthermore, we demonstrate that explicitly prompting for information disclosure reliably improves performance across diverse model families, suggesting that proactive transparency is a vital lever for agent optimization. Overall, our study suggests that information transparency awareness is a crucial yet underexplored perspective for the future design of reasoning agents in real-world scenarios. Our code is available at https://github.com/deeplearning-wisc/Thinking-Agent.
Towards Reducible Uncertainty Modeling for Reliable Large Language Model Agents
Feb 04, 2026Uncertainty quantification (UQ) for large language models (LLMs) is a key building block for safety guardrails of daily LLM applications. Yet, even as LLM agents are increasingly deployed in highly complex tasks, most UQ research still centers on single-turn question-answering. We argue that UQ research must shift to realistic settings with interactive agents, and that a new principled framework for agent UQ is needed. This paper presents the first general formulation of agent UQ that subsumes broad classes of existing UQ setups. Under this formulation, we show that prior works implicitly treat LLM UQ as an uncertainty accumulation process, a viewpoint that breaks down for interactive agents in an open world. In contrast, we propose a novel perspective, a conditional uncertainty reduction process, that explicitly models reducible uncertainty over an agent's trajectory by highlighting "interactivity" of actions. From this perspective, we outline a conceptual framework to provide actionable guidance for designing UQ in LLM agent setups. Finally, we conclude with practical implications of the agent UQ in frontier LLM development and domain-specific applications, as well as open remaining problems.
How Do Transformers Learn to Associate Tokens: Gradient Leading Terms Bring Mechanistic Interpretability
Jan 27, 2026Semantic associations such as the link between "bird" and "flew" are foundational for language modeling as they enable models to go beyond memorization and instead generalize and generate coherent text. Understanding how these associations are learned and represented in language models is essential for connecting deep learning with linguistic theory and developing a mechanistic foundation for large language models. In this work, we analyze how these associations emerge from natural language data in attention-based language models through the lens of training dynamics. By leveraging a leading-term approximation of the gradients, we develop closed-form expressions for the weights at early stages of training that explain how semantic associations first take shape. Through our analysis, we reveal that each set of weights of the transformer has closed-form expressions as simple compositions of three basis functions (bigram, token-interchangeability, and context mappings), reflecting the statistics of the text corpus and uncovering how each component of the transformer captures semantic associations based on these compositions. Experiments on real-world LLMs demonstrate that our theoretical weight characterizations closely match the learned weights, and qualitative analyses further show how our theorem shines light on interpreting the learned associations in transformers.
Visual Instruction Bottleneck Tuning
May 20, 2025Despite widespread adoption, multimodal large language models (MLLMs) suffer performance degradation when encountering unfamiliar queries under distribution shifts. Existing methods to improve MLLM generalization typically require either more instruction data or larger advanced model architectures, both of which incur non-trivial human labor or computational costs. In this work, we take an alternative approach to enhance the robustness of MLLMs under distribution shifts, from a representation learning perspective. Inspired by the information bottleneck (IB) principle, we derive a variational lower bound of the IB for MLLMs and devise a practical implementation, Visual Instruction Bottleneck Tuning (Vittle). We then provide a theoretical justification of Vittle by revealing its connection to an information-theoretic robustness metric of MLLM. Empirical validation of three MLLMs on open-ended and closed-form question answering and object hallucination detection tasks over 45 datasets, including 30 shift scenarios, demonstrates that Vittle consistently improves the MLLM's robustness under shifts by pursuing the learning of a minimal sufficient representation.
DaWin: Training-free Dynamic Weight Interpolation for Robust Adaptation
Oct 03, 2024Adapting a pre-trained foundation model on downstream tasks should ensure robustness against distribution shifts without the need to retrain the whole model. Although existing weight interpolation methods are simple yet effective, we argue their static nature limits downstream performance while achieving efficiency. In this work, we propose DaWin, a training-free dynamic weight interpolation method that leverages the entropy of individual models over each unlabeled test sample to assess model expertise, and compute per-sample interpolation coefficients dynamically. Unlike previous works that typically rely on additional training to learn such coefficients, our approach requires no training. Then, we propose a mixture modeling approach that greatly reduces inference overhead raised by dynamic interpolation. We validate DaWin on the large-scale visual recognition benchmarks, spanning 14 tasks across robust fine-tuning -- ImageNet and derived five distribution shift benchmarks -- and multi-task learning with eight classification tasks. Results demonstrate that DaWin achieves significant performance gain in considered settings, with minimal computational overhead. We further discuss DaWin's analytic behavior to explain its empirical success.
Perturb-and-Compare Approach for Detecting Out-of-Distribution Samples in Constrained Access Environments
Aug 19, 2024Accessing machine learning models through remote APIs has been gaining prevalence following the recent trend of scaling up model parameters for increased performance. Even though these models exhibit remarkable ability, detecting out-of-distribution (OOD) samples remains a crucial safety concern for end users as these samples may induce unreliable outputs from the model. In this work, we propose an OOD detection framework, MixDiff, that is applicable even when the model's parameters or its activations are not accessible to the end user. To bypass the access restriction, MixDiff applies an identical input-level perturbation to a given target sample and a similar in-distribution (ID) sample, then compares the relative difference in the model outputs of these two samples. MixDiff is model-agnostic and compatible with existing output-based OOD detection methods. We provide theoretical analysis to illustrate MixDiff's effectiveness in discerning OOD samples that induce overconfident outputs from the model and empirically demonstrate that MixDiff consistently enhances the OOD detection performance on various datasets in vision and text domains.
Enhancing Temporal Action Localization: Advanced S6 Modeling with Recurrent Mechanism
Jul 18, 2024
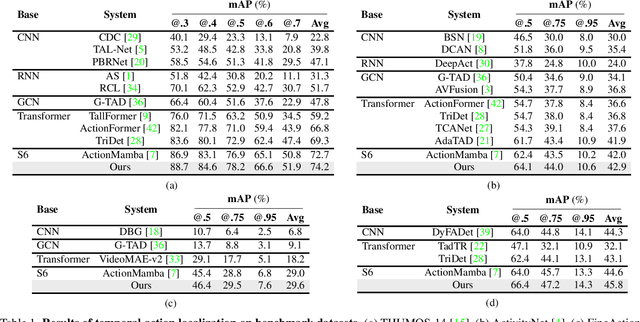

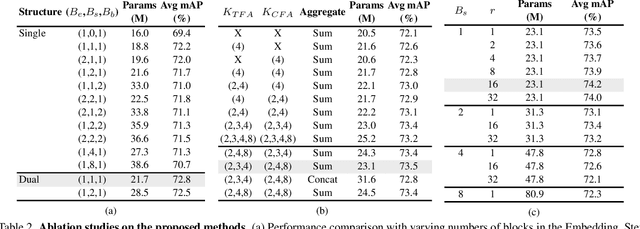
Temporal Action Localization (TAL) is a critical task in video analysis, identifying precise start and end times of actions. Existing methods like CNNs, RNNs, GCNs, and Transformers have limitations in capturing long-range dependencies and temporal causality. To address these challenges, we propose a novel TAL architecture leveraging the Selective State Space Model (S6). Our approach integrates the Feature Aggregated Bi-S6 block, Dual Bi-S6 structure, and a recurrent mechanism to enhance temporal and channel-wise dependency modeling without increasing parameter complexity. Extensive experiments on benchmark datasets demonstrate state-of-the-art results with mAP scores of 74.2% on THUMOS-14, 42.9% on ActivityNet, 29.6% on FineAction, and 45.8% on HACS. Ablation studies validate our method's effectiveness, showing that the Dual structure in the Stem module and the recurrent mechanism outperform traditional approaches. Our findings demonstrate the potential of S6-based models in TAL tasks, paving the way for future research.
Mitigating the Linguistic Gap with Phonemic Representations for Robust Multilingual Language Understanding
Feb 22, 2024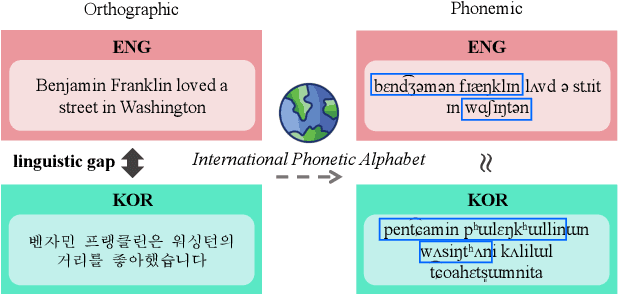
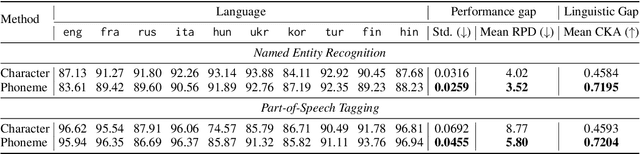
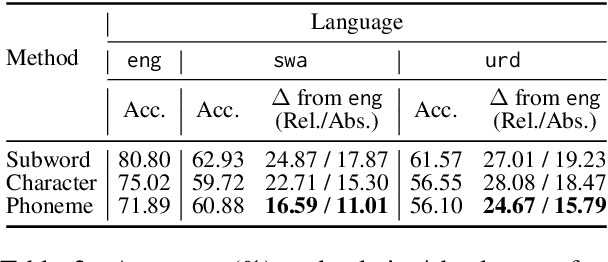
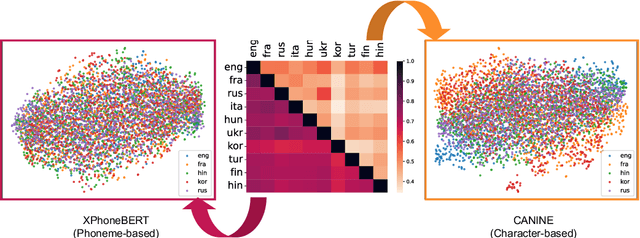
Approaches to improving multilingual language understanding often require multiple languages during the training phase, rely on complicated training techniques, and -- importantly -- struggle with significant performance gaps between high-resource and low-resource languages. We hypothesize that the performance gaps between languages are affected by linguistic gaps between those languages and provide a novel solution for robust multilingual language modeling by employing phonemic representations (specifically, using phonemes as input tokens to LMs rather than subwords). We present quantitative evidence from three cross-lingual tasks that demonstrate the effectiveness of phonemic representation, which is further justified by a theoretical analysis of the cross-lingual performance gap.
Towards Calibrated Robust Fine-Tuning of Vision-Language Models
Nov 06, 2023



While fine-tuning unlocks the potential of a pre-trained model for a specific task, it compromises the model's ability to generalize to out-of-distribution (OOD) datasets. To mitigate this, robust fine-tuning aims to ensure performance on OOD datasets as well as on an in-distribution (ID) dataset for which the model is being tuned. However, another criterion for reliable machine learning (ML), confidence calibration, has been overlooked despite its increasing demand for real-world high-stakes ML applications (e.g., autonomous driving and medical diagnosis). For the first time, we raise concerns about the calibration of fine-tuned vision-language models (VLMs) under distribution shift by showing that naive fine-tuning and even state-of-the-art robust fine-tuning methods hurt the calibration of pre-trained VLMs, especially on OOD datasets. To address this issue, we provide a simple approach, called calibrated robust fine-tuning (CaRot), that incentivizes calibration and robustness on both ID and OOD datasets. Empirical results on ImageNet-1K distribution shift evaluation verify the effectiveness of our method.