 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Temporal Action Localization: Advanced S6 Modeling with Recurrent Mechanism
Jul 18, 2024
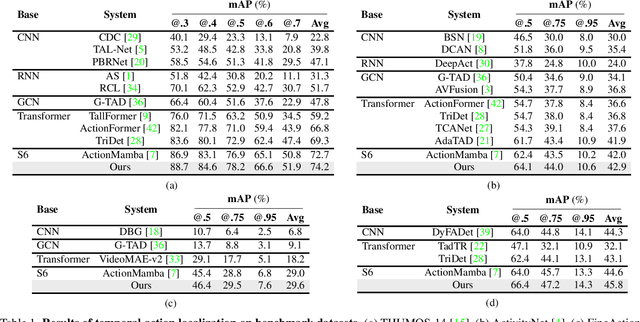

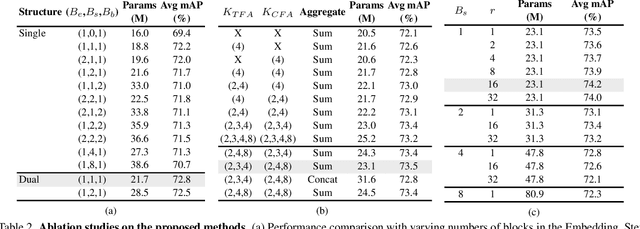
Temporal Action Localization (TAL) is a critical task in video analysis, identifying precise start and end times of actions. Existing methods like CNNs, RNNs, GCNs, and Transformers have limitations in capturing long-range dependencies and temporal causality. To address these challenges, we propose a novel TAL architecture leveraging the Selective State Space Model (S6). Our approach integrates the Feature Aggregated Bi-S6 block, Dual Bi-S6 structure, and a recurrent mechanism to enhance temporal and channel-wise dependency modeling without increasing parameter complexity. Extensive experiments on benchmark datasets demonstrate state-of-the-art results with mAP scores of 74.2% on THUMOS-14, 42.9% on ActivityNet, 29.6% on FineAction, and 45.8% on HACS. Ablation studies validate our method's effectiveness, showing that the Dual structure in the Stem module and the recurrent mechanism outperform traditional approaches. Our findings demonstrate the potential of S6-based models in TAL tasks, paving the way for future research.
Calibrated neighborhood aware confidence measure for deep metric learning
Jun 08, 2020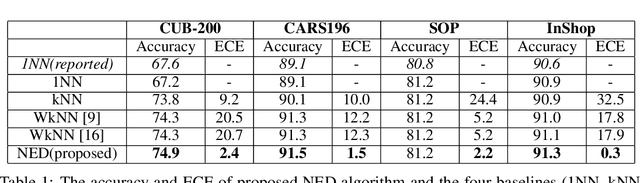
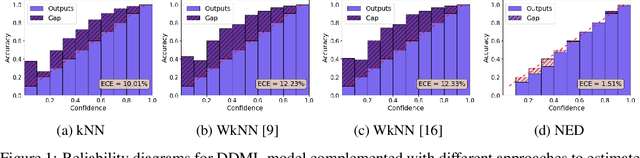
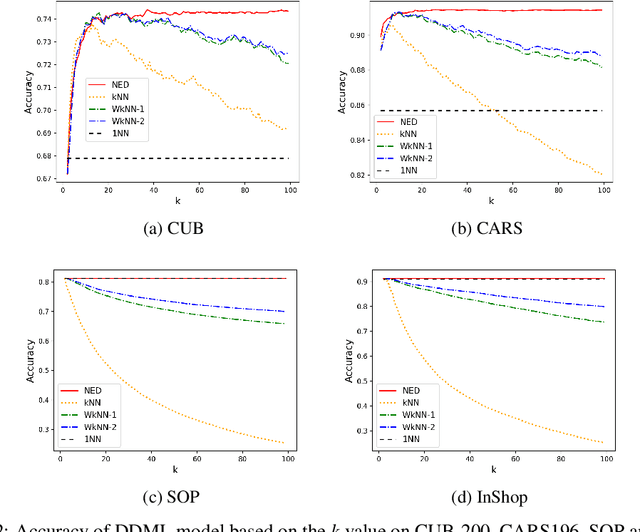
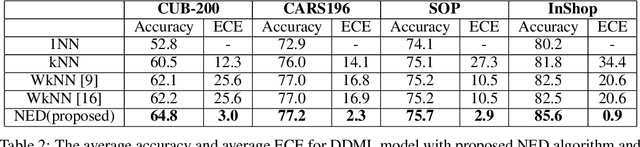
Deep metric learning has gained promising improvement in recent years following the success of deep learning. It has been successfully applied to problems in few-shot learning, image retrieval, and open-set classifications. However, measuring the confidence of a deep metric learning model and identifying unreliable predictions is still an open challenge. This paper focuses on defining a calibrated and interpretable confidence metric that closely reflects its classification accuracy. While performing similarity comparison directly in the latent space using the learned distance metric, our approach approximates the distribution of data points for each class using a Gaussian kernel smoothing function. The post-processing calibration algorithm with proposed confidence metric on the held-out validation dataset improves generalization and robustness of state-of-the-art deep metric learning models while provides an interpretable estimation of the confidence. Extensive tests on four popular benchmark datasets (Caltech-UCSD Birds, Stanford Online Product, Stanford Car-196, and In-shop Clothes Retrieval) show consistent improvements even at the presence of distribution shifts in test data related to additional noise or adversarial examples.