 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWithin-basket Recommendation via Neural Pattern Associator
Jan 25, 2024
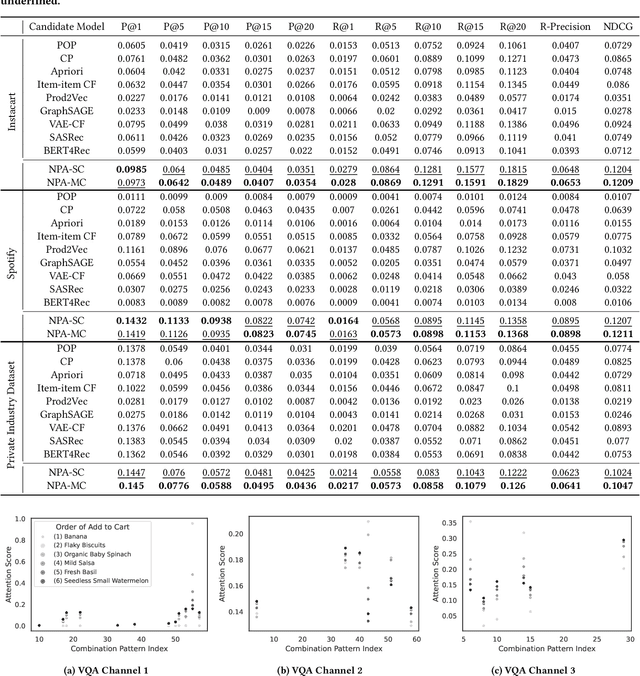
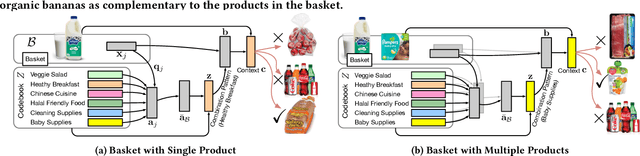

Within-basket recommendation (WBR) refers to the task of recommending items to the end of completing a non-empty shopping basket during a shopping session. While the latest innovations in this space demonstrate remarkable performance improvement on benchmark datasets, they often overlook the complexity of user behaviors in practice, such as 1) co-existence of multiple shopping intentions, 2) multi-granularity of such intentions, and 3) interleaving behavior (switching intentions) in a shopping session. This paper presents Neural Pattern Associator (NPA), a deep item-association-mining model that explicitly models the aforementioned factors. Specifically, inspired by vector quantization, the NPA model learns to encode common user intentions (or item-combination patterns) as quantized representations (a.k.a. codebook), which permits identification of users's shopping intentions via attention-driven lookup during the reasoning phase. This yields coherent and self-interpretable recommendations. We evaluated the proposed NPA model across multiple extensive datasets, encompassing the domains of grocery e-commerce (shopping basket completion) and music (playlist extension), where our quantitative evaluations show that the NPA model significantly outperforms a wide range of existing WBR solutions, reflecting the benefit of explicitly modeling complex user intentions.
Adaptive additive classification-based loss for deep metric learning
Jun 25, 2020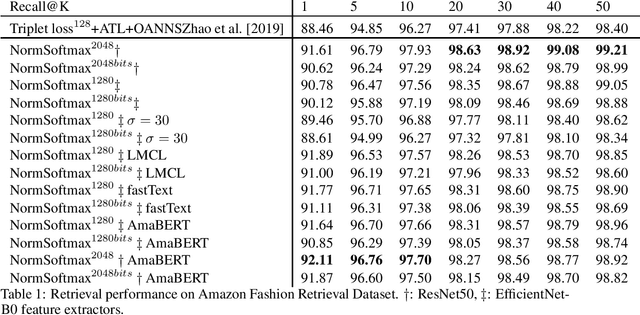

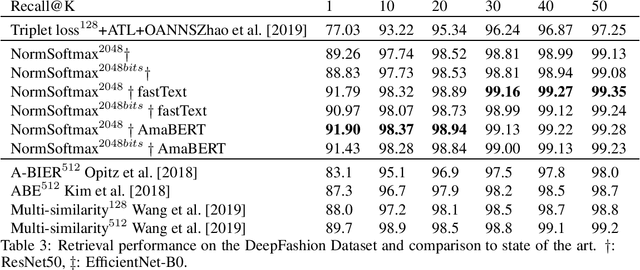
Recent works have shown that deep metric learning algorithms can benefit from weak supervision from another input modality. This additional modality can be incorporated directly into the popular triplet-based loss function as distances. Also recently, classification loss and proxy-based metric learning have been observed to lead to faster convergence as well as better retrieval results, all the while without requiring complex and costly sampling strategies. In this paper we propose an extension to the existing adaptive margin for classification-based deep metric learning. Our extension introduces a separate margin for each negative proxy per sample. These margins are computed during training from precomputed distances of the classes in the other modality. Our results set a new state-of-the-art on both on the Amazon fashion retrieval dataset as well as on the public DeepFashion dataset. This was observed with both fastText- and BERT-based embeddings for the additional textual modality. Our results were achieved with faster convergence and lower code complexity than the prior state-of-the-art.
Calibrated neighborhood aware confidence measure for deep metric learning
Jun 08, 2020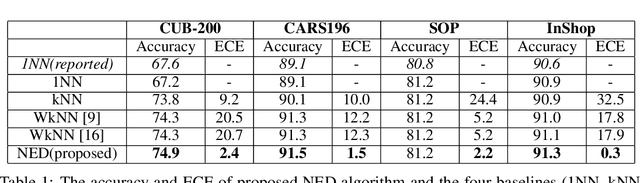
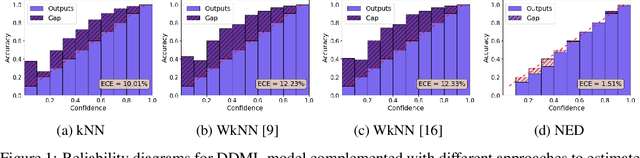
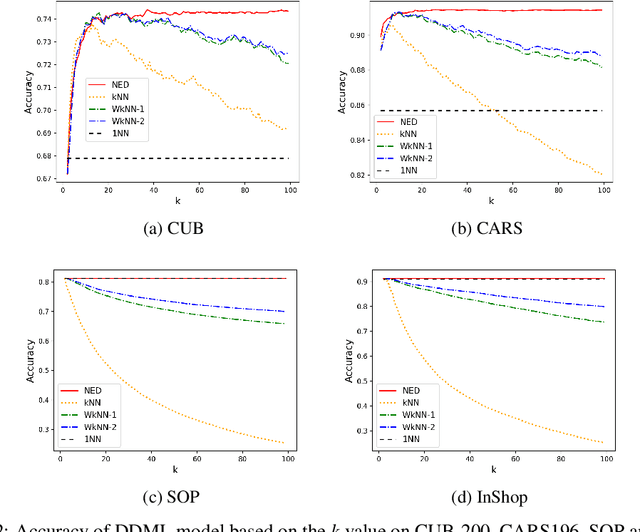
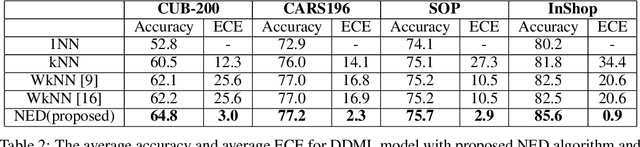
Deep metric learning has gained promising improvement in recent years following the success of deep learning. It has been successfully applied to problems in few-shot learning, image retrieval, and open-set classifications. However, measuring the confidence of a deep metric learning model and identifying unreliable predictions is still an open challenge. This paper focuses on defining a calibrated and interpretable confidence metric that closely reflects its classification accuracy. While performing similarity comparison directly in the latent space using the learned distance metric, our approach approximates the distribution of data points for each class using a Gaussian kernel smoothing function. The post-processing calibration algorithm with proposed confidence metric on the held-out validation dataset improves generalization and robustness of state-of-the-art deep metric learning models while provides an interpretable estimation of the confidence. Extensive tests on four popular benchmark datasets (Caltech-UCSD Birds, Stanford Online Product, Stanford Car-196, and In-shop Clothes Retrieval) show consistent improvements even at the presence of distribution shifts in test data related to additional noise or adversarial examples.
Unbiased Evaluation of Deep Metric Learning Algorithms
Nov 28, 2019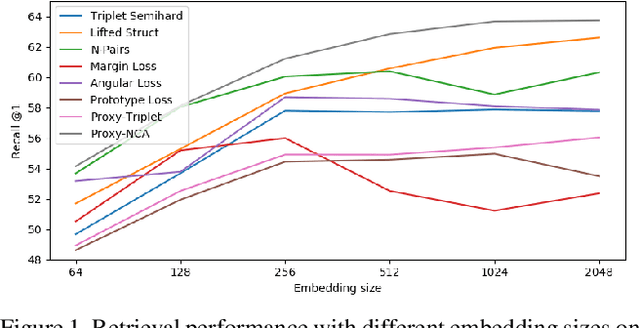

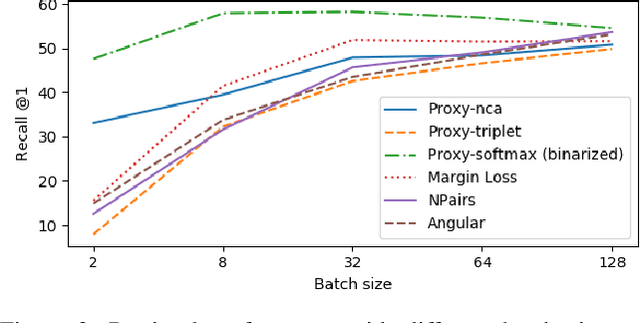
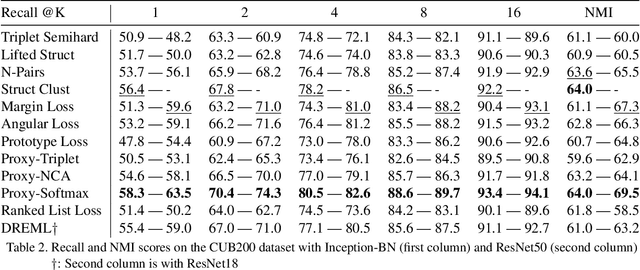
Deep metric learning (DML) is a popular approach for images retrieval, solving verification (same or not) problems and addressing open set classification. Arguably, the most common DML approach is with triplet loss, despite significant advances in the area of DML. Triplet loss suffers from several issues such as collapse of the embeddings, high sensitivity to sampling schemes and more importantly a lack of performance when compared to more modern methods. We attribute this adoption to a lack of fair comparisons between various methods and the difficulty in adopting them for novel problem statements. In this paper, we perform an unbiased comparison of the most popular DML baseline methods under same conditions and more importantly, not obfuscating any hyper parameter tuning or adjustment needed to favor a particular method. We find, that under equal conditions several older methods perform significantly better than previously believed. In fact, our unified implementation of 12 recently introduced DML algorithms achieve state-of-the art performance on CUB200, CAR196, and Stanford Online products datasets which establishes a new set of baselines for future DML research. The codebase and all tuned hyperparameters will be open-sourced for reproducibility and to serve as a source of benchmark.
Scalable Logo Recognition using Proxies
Nov 19, 2018
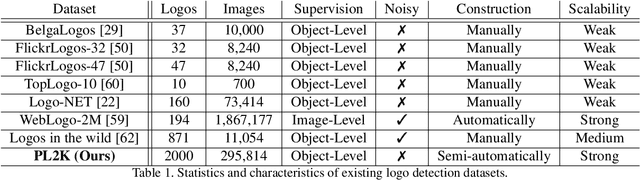
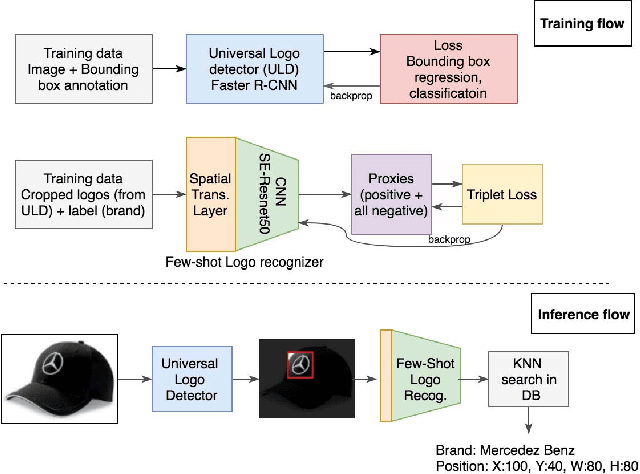
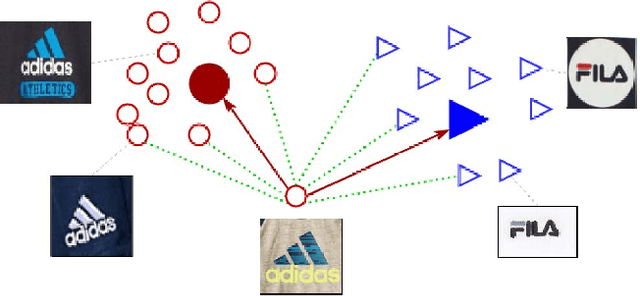
Logo recognition is the task of identifying and classifying logos. Logo recognition is a challenging problem as there is no clear definition of a logo and there are huge variations of logos, brands and re-training to cover every variation is impractical. In this paper, we formulate logo recognition as a few-shot object detection problem. The two main components in our pipeline are universal logo detector and few-shot logo recognizer. The universal logo detector is a class-agnostic deep object detector network which tries to learn the characteristics of what makes a logo. It predicts bounding boxes on likely logo regions. These logo regions are then classified by logo recognizer using nearest neighbor search, trained by triplet loss using proxies. We also annotated a first of its kind product logo dataset containing 2000 logos from 295K images collected from Amazon called PL2K. Our pipeline achieves 97% recall with 0.6 mAP on PL2K test dataset and state-of-the-art 0.565 mAP on the publicly available FlickrLogos-32 test set without fine-tuning.