 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive additive classification-based loss for deep metric learning
Paper and Code
Jun 25, 2020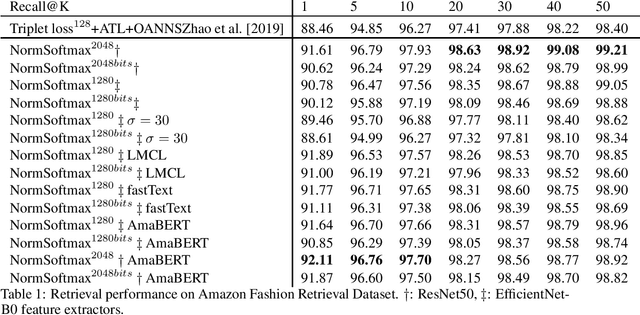

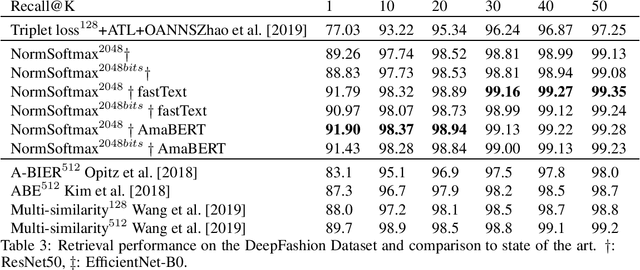
Recent works have shown that deep metric learning algorithms can benefit from weak supervision from another input modality. This additional modality can be incorporated directly into the popular triplet-based loss function as distances. Also recently, classification loss and proxy-based metric learning have been observed to lead to faster convergence as well as better retrieval results, all the while without requiring complex and costly sampling strategies. In this paper we propose an extension to the existing adaptive margin for classification-based deep metric learning. Our extension introduces a separate margin for each negative proxy per sample. These margins are computed during training from precomputed distances of the classes in the other modality. Our results set a new state-of-the-art on both on the Amazon fashion retrieval dataset as well as on the public DeepFashion dataset. This was observed with both fastText- and BERT-based embeddings for the additional textual modality. Our results were achieved with faster convergence and lower code complexity than the prior state-of-the-art.