 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Evaluation of Deep Metric Learning Algorithms
Paper and Code
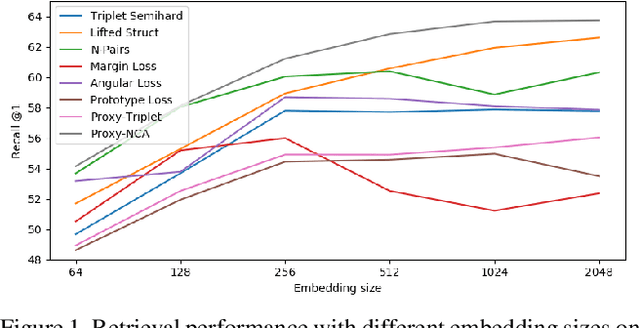

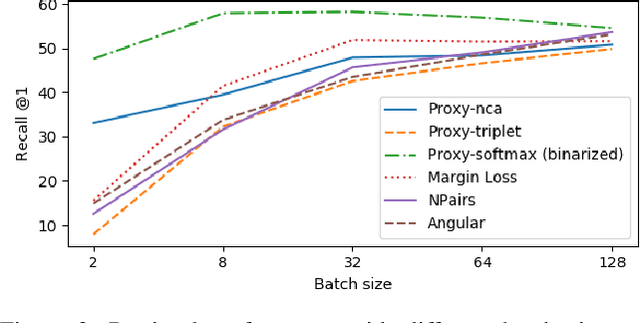
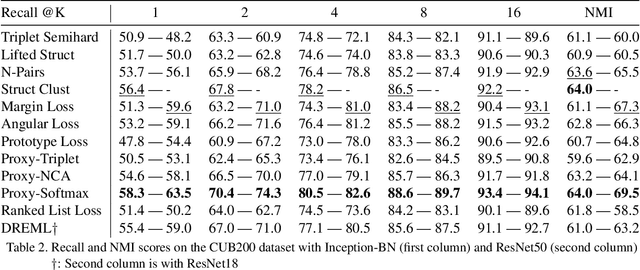
Deep metric learning (DML) is a popular approach for images retrieval, solving verification (same or not) problems and addressing open set classification. Arguably, the most common DML approach is with triplet loss, despite significant advances in the area of DML. Triplet loss suffers from several issues such as collapse of the embeddings, high sensitivity to sampling schemes and more importantly a lack of performance when compared to more modern methods. We attribute this adoption to a lack of fair comparisons between various methods and the difficulty in adopting them for novel problem statements. In this paper, we perform an unbiased comparison of the most popular DML baseline methods under same conditions and more importantly, not obfuscating any hyper parameter tuning or adjustment needed to favor a particular method. We find, that under equal conditions several older methods perform significantly better than previously believed. In fact, our unified implementation of 12 recently introduced DML algorithms achieve state-of-the art performance on CUB200, CAR196, and Stanford Online products datasets which establishes a new set of baselines for future DML research. The codebase and all tuned hyperparameters will be open-sourced for reproducibility and to serve as a source of benchmark.