 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoramic Multimodal Semantic Occupancy Prediction for Quadruped Robots
Mar 13, 2026Panoramic imagery provides holistic 360° visual coverage for perception in quadruped robots. However, existing occupancy prediction methods are mainly designed for wheeled autonomous driving and rely heavily on RGB cues, limiting their robustness in complex environments. To bridge this gap, (1) we present PanoMMOcc, the first real-world panoramic multimodal occupancy dataset for quadruped robots, featuring four sensing modalities across diverse scenes. (2) We propose a panoramic multimodal occupancy perception framework, VoxelHound, tailored for legged mobility and spherical imaging. Specifically, we design (i) a Vertical Jitter Compensation (VJC) module to mitigate severe viewpoint perturbations caused by body pitch and roll during mobility, enabling more consistent spatial reasoning, and (ii) an effective Multimodal Information Prompt Fusion (MIPF) module that jointly leverages panoramic visual cues and auxiliary modalities to enhance volumetric occupancy prediction. (3) We establish a benchmark based on PanoMMOcc and provide detailed data analysis to enable systematic evaluation of perception methods under challenging embodied scenarios. Extensive experiments demonstrate that VoxelHound achieves state-of-the-art performance on PanoMMOcc (+4.16%} in mIoU). The dataset and code will be publicly released to facilitate future research on panoramic multimodal 3D perception for embodied robotic systems at https://github.com/SXDR/PanoMMOcc, along with the calibration tools released at https://github.com/losehu/CameraLiDAR-Calib.
OccTrack360: 4D Panoptic Occupancy Tracking from Surround-View Fisheye Cameras
Mar 09, 2026Understanding dynamic 3D environments in a spatially continuous and temporally consistent manner is fundamental for robotics and autonomous driving. While recent advances in occupancy prediction provide a unified representation of scene geometry and semantics, progress in 4D panoptic occupancy tracking remains limited by the lack of benchmarks that support surround-view fisheye sensing, long temporal sequences, and instance-level voxel tracking. To address this gap, we present OccTrack360, a new benchmark for 4D panoptic occupancy tracking from surround-view fisheye cameras. OccTrack360 provides substantially longer and more diverse sequences (174~2234 frames) than prior benchmarks, together with principled voxel visibility annotations, including an all-direction occlusion mask and an MEI-based fisheye field-of-view mask. To establish a strong fisheye-oriented baseline, we further propose Focus on Sphere Occ (FoSOcc), a framework that addresses two core challenges in fisheye occupancy tracking: distorted spherical projection and inaccurate voxel-space localization. FoSOcc includes a Center Focusing Module (CFM) to enhance instance-aware spatial localization through supervised focus guidance, and a Spherical Lift Module (SLM) that extends perspective lifting to fisheye imaging under the Unified Projection Model. Extensive experiments on Occ3D-Waymo and OccTrack360 show that our method improves occupancy tracking quality with notable gains on geometrically regular categories, and establishes a strong baseline for future research on surround-view fisheye 4D occupancy tracking. The benchmark and source code will be made publicly available at https://github.com/YouthZest-Lin/OccTrack360.
Spherical-GOF: Geometry-Aware Panoramic Gaussian Opacity Fields for 3D Scene Reconstruction
Mar 09, 2026Omnidirectional images are increasingly used in robotics and vision due to their wide field of view. However, extending 3D Gaussian Splatting (3DGS) to panoramic camera models remains challenging, as existing formulations are designed for perspective projections and naive adaptations often introduce distortion and geometric inconsistencies. We present Spherical-GOF, an omnidirectional Gaussian rendering framework built upon Gaussian Opacity Fields (GOF). Unlike projection-based rasterization, Spherical-GOF performs GOF ray sampling directly on the unit sphere in spherical ray space, enabling consistent ray-Gaussian interactions for panoramic rendering. To make the spherical ray casting efficient and robust, we derive a conservative spherical bounding rule for fast ray-Gaussian culling and introduce a spherical filtering scheme that adapts Gaussian footprints to distortion-varying panoramic pixel sampling. Extensive experiments on standard panoramic benchmarks (OmniBlender and OmniPhotos) demonstrate competitive photometric quality and substantially improved geometric consistency. Compared with the strongest baseline, Spherical-GOF reduces depth reprojection error by 57% and improves cycle inlier ratio by 21%. Qualitative results show cleaner depth and more coherent normal maps, with strong robustness to global panorama rotations. We further validate generalization on OmniRob, a real-world robotic omnidirectional dataset introduced in this work, featuring UAV and quadruped platforms. The source code and the OmniRob dataset will be released at https://github.com/1170632760/Spherical-GOF.
An LLM-based Quantitative Framework for Evaluating High-Stealthy Backdoor Risks in OSS Supply Chains
Nov 17, 2025In modern software development workflows, the open-source software supply chain contributes significantly to efficient and convenient engineering practices. With increasing system complexity, using open-source software as third-party dependencies has become a common practice. However, the lack of maintenance for underlying dependencies and insufficient community auditing create challenges in ensuring source code security and the legitimacy of repository maintainers, especially under high-stealthy backdoor attacks exemplified by the XZ-Util incident. To address these problems, we propose a fine-grained project evaluation framework for backdoor risk assessment in open-source software. The framework models stealthy backdoor attacks from the viewpoint of the attacker and defines targeted metrics for each attack stage. In addition, to overcome the limitations of static analysis in assessing the reliability of repository maintenance activities such as irregular committer privilege escalation and limited participation in reviews, the framework uses large language models (LLMs) to conduct semantic evaluation of code repositories without relying on manually crafted patterns. The framework is evaluated on sixty six high-priority packages in the Debian ecosystem. The experimental results indicate that the current open-source software supply chain is exposed to various security risks.
THAT: Token-wise High-frequency Augmentation Transformer for Hyperspectral Pansharpening
Aug 11, 2025Transformer-based methods have demonstrated strong potential in hyperspectral pansharpening by modeling long-range dependencies. However, their effectiveness is often limited by redundant token representations and a lack of multi-scale feature modeling. Hyperspectral images exhibit intrinsic spectral priors (e.g., abundance sparsity) and spatial priors (e.g., non-local similarity), which are critical for accurate reconstruction. From a spectral-spatial perspective, Vision Transformers (ViTs) face two major limitations: they struggle to preserve high-frequency components--such as material edges and texture transitions--and suffer from attention dispersion across redundant tokens. These issues stem from the global self-attention mechanism, which tends to dilute high-frequency signals and overlook localized details. To address these challenges, we propose the Token-wise High-frequency Augmentation Transformer (THAT), a novel framework designed to enhance hyperspectral pansharpening through improved high-frequency feature representation and token selection. Specifically, THAT introduces: (1) Pivotal Token Selective Attention (PTSA) to prioritize informative tokens and suppress redundancy; (2) a Multi-level Variance-aware Feed-forward Network (MVFN) to enhance high-frequency detail learning. Experiments on standard benchmarks show that THAT achieves state-of-the-art performance with improved reconstruction quality and efficiency. The source code is available at https://github.com/kailuo93/THAT.
Hallucinating 360°: Panoramic Street-View Generation via Local Scenes Diffusion and Probabilistic Prompting
Jul 09, 2025



Panoramic perception holds significant potential for autonomous driving, enabling vehicles to acquire a comprehensive 360{\deg} surround view in a single shot. However, autonomous driving is a data-driven task. Complete panoramic data acquisition requires complex sampling systems and annotation pipelines, which are time-consuming and labor-intensive. Although existing street view generation models have demonstrated strong data regeneration capabilities, they can only learn from the fixed data distribution of existing datasets and cannot achieve high-quality, controllable panoramic generation. In this paper, we propose the first panoramic generation method Percep360 for autonomous driving. Percep360 enables coherent generation of panoramic data with control signals based on the stitched panoramic data. Percep360 focuses on two key aspects: coherence and controllability. Specifically, to overcome the inherent information loss caused by the pinhole sampling process, we propose the Local Scenes Diffusion Method (LSDM). LSDM reformulates the panorama generation as a spatially continuous diffusion process, bridging the gaps between different data distributions. Additionally, to achieve the controllable generation of panoramic images, we propose a Probabilistic Prompting Method (PPM). PPM dynamically selects the most relevant control cues, enabling controllable panoramic image generation. We evaluate the effectiveness of the generated images from three perspectives: image quality assessment (i.e., no-reference and with reference), controllability, and their utility in real-world Bird's Eye View (BEV) segmentation. Notably, the generated data consistently outperforms the original stitched images in no-reference quality metrics and enhances downstream perception models. The source code will be publicly available at https://github.com/Bryant-Teng/Percep360.
Panoramic Out-of-Distribution Segmentation
May 06, 2025Panoramic imaging enables capturing 360{\deg} images with an ultra-wide Field-of-View (FoV) for dense omnidirectional perception. However, current panoramic semantic segmentation methods fail to identify outliers, and pinhole Out-of-distribution Segmentation (OoS) models perform unsatisfactorily in the panoramic domain due to background clutter and pixel distortions. To address these issues, we introduce a new task, Panoramic Out-of-distribution Segmentation (PanOoS), achieving OoS for panoramas. Furthermore, we propose the first solution, POS, which adapts to the characteristics of panoramic images through text-guided prompt distribution learning. Specifically, POS integrates a disentanglement strategy designed to materialize the cross-domain generalization capability of CLIP. The proposed Prompt-based Restoration Attention (PRA) optimizes semantic decoding by prompt guidance and self-adaptive correction, while Bilevel Prompt Distribution Learning (BPDL) refines the manifold of per-pixel mask embeddings via semantic prototype supervision. Besides, to compensate for the scarcity of PanOoS datasets, we establish two benchmarks: DenseOoS, which features diverse outliers in complex environments, and QuadOoS, captured by a quadruped robot with a panoramic annular lens system. Extensive experiments demonstrate superior performance of POS, with AuPRC improving by 34.25% and FPR95 decreasing by 21.42% on DenseOoS, outperforming state-of-the-art pinhole-OoS methods. Moreover, POS achieves leading closed-set segmentation capabilities. Code and datasets will be available at https://github.com/MengfeiD/PanOoS.
DAE-KAN: A Kolmogorov-Arnold Network Model for High-Index Differential-Algebraic Equations
Apr 22, 2025Kolmogorov-Arnold Networks (KANs) have emerged as a promising alternative to Multi-Layer Perceptrons (MLPs) due to their superior function-fitting abilities in data-driven modeling. In this paper, we propose a novel framework, DAE-KAN, for solving high-index differential-algebraic equations (DAEs) by integrating KANs with Physics-Informed Neural Networks (PINNs). This framework not only preserves the ability of traditional PINNs to model complex systems governed by physical laws but also enhances their performance by leveraging the function-fitting strengths of KANs. Numerical experiments demonstrate that for DAE systems ranging from index-1 to index-3, DAE-KAN reduces the absolute errors of both differential and algebraic variables by 1 to 2 orders of magnitude compared to traditional PINNs. To assess the effectiveness of this approach, we analyze the drift-off error and find that both PINNs and DAE-KAN outperform classical numerical methods in controlling this phenomenon. Our results highlight the potential of neural network methods, particularly DAE-KAN, in solving high-index DAEs with substantial computational accuracy and generalization, offering a promising solution for challenging partial differential-algebraic equations.
Omnidirectional Multi-Object Tracking
Mar 06, 2025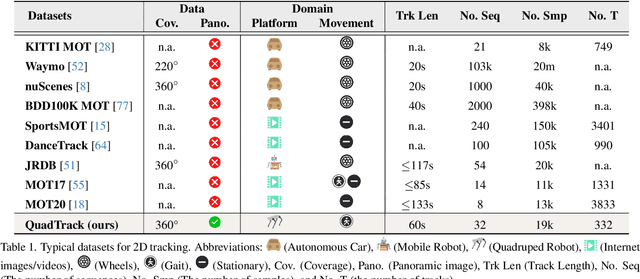
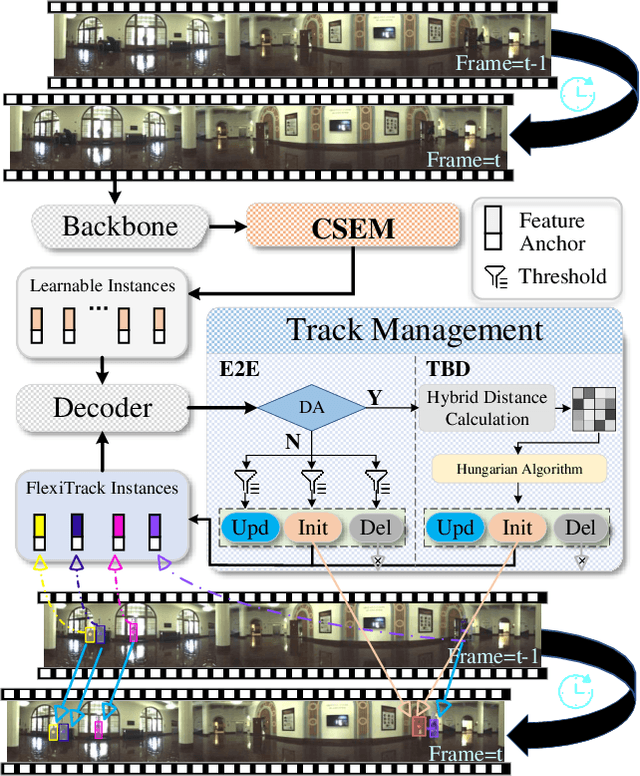
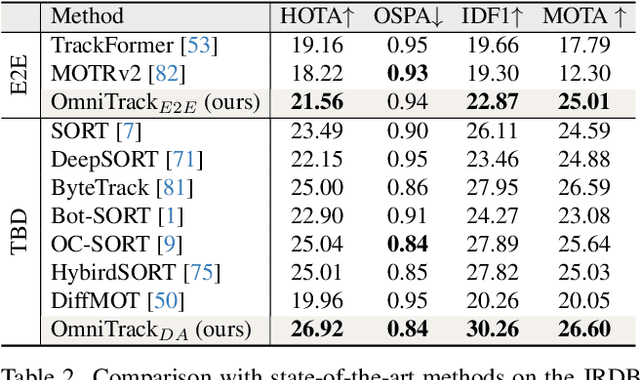
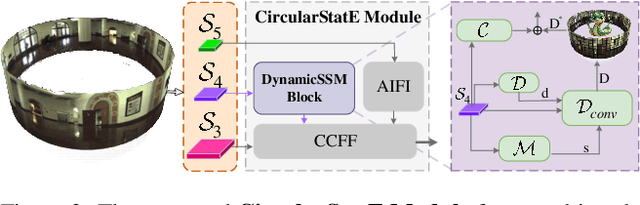
Panoramic imagery, with its 360{\deg} field of view, offers comprehensive information to support Multi-Object Tracking (MOT) in capturing spatial and temporal relationships of surrounding objects. However, most MOT algorithms are tailored for pinhole images with limited views, impairing their effectiveness in panoramic settings. Additionally, panoramic image distortions, such as resolution loss, geometric deformation, and uneven lighting, hinder direct adaptation of existing MOT methods, leading to significant performance degradation. To address these challenges, we propose OmniTrack, an omnidirectional MOT framework that incorporates Tracklet Management to introduce temporal cues, FlexiTrack Instances for object localization and association, and the CircularStatE Module to alleviate image and geometric distortions. This integration enables tracking in large field-of-view scenarios, even under rapid sensor motion. To mitigate the lack of panoramic MOT datasets, we introduce the QuadTrack dataset--a comprehensive panoramic dataset collected by a quadruped robot, featuring diverse challenges such as wide fields of view, intense motion, and complex environments. Extensive experiments on the public JRDB dataset and the newly introduced QuadTrack benchmark demonstrate the state-of-the-art performance of the proposed framework. OmniTrack achieves a HOTA score of 26.92% on JRDB, representing an improvement of 3.43%, and further achieves 23.45% on QuadTrack, surpassing the baseline by 6.81%. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack.
Unveiling the Potential of Segment Anything Model 2 for RGB-Thermal Semantic Segmentation with Language Guidance
Mar 04, 2025The perception capability of robotic systems relies on the richness of the dataset. Although Segment Anything Model 2 (SAM2), trained on large datasets, demonstrates strong perception potential in perception tasks, its inherent training paradigm prevents it from being suitable for RGB-T tasks. To address these challenges, we propose SHIFNet, a novel SAM2-driven Hybrid Interaction Paradigm that unlocks the potential of SAM2 with linguistic guidance for efficient RGB-Thermal perception. Our framework consists of two key components: (1) Semantic-Aware Cross-modal Fusion (SACF) module that dynamically balances modality contributions through text-guided affinity learning, overcoming SAM2's inherent RGB bias; (2) Heterogeneous Prompting Decoder (HPD) that enhances global semantic information through a semantic enhancement module and then combined with category embeddings to amplify cross-modal semantic consistency. With 32.27M trainable parameters, SHIFNet achieves state-of-the-art segmentation performance on public benchmarks, reaching 89.8% on PST900 and 67.8% on FMB, respectively. The framework facilitates the adaptation of pre-trained large models to RGB-T segmentation tasks, effectively mitigating the high costs associated with data collection while endowing robotic systems with comprehensive perception capabilities. The source code will be made publicly available at https://github.com/iAsakiT3T/SHIFNet.