 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACER: Texture-Robust Affordance Chain-of-Thought for Deformable-Object Refinement
Jan 28, 2026The central challenge in robotic manipulation of deformable objects lies in aligning high-level semantic instructions with physical interaction points under complex appearance and texture variations. Due to near-infinite degrees of freedom, complex dynamics, and heterogeneous patterns, existing vision-based affordance prediction methods often suffer from boundary overflow and fragmented functional regions. To address these issues, we propose TRACER, a Texture-Robust Affordance Chain-of-thought with dEformable-object Refinement framework, which establishes a cross-hierarchical mapping from hierarchical semantic reasoning to appearance-robust and physically consistent functional region refinement. Specifically, a Tree-structured Affordance Chain-of-Thought (TA-CoT) is formulated to decompose high-level task intentions into hierarchical sub-task semantics, providing consistent guidance across various execution stages. To ensure spatial integrity, a Spatial-Constrained Boundary Refinement (SCBR) mechanism is introduced to suppress prediction spillover, guiding the perceptual response to converge toward authentic interaction manifolds. Furthermore, an Interactive Convergence Refinement Flow (ICRF) is developed to aggregate discrete pixels corrupted by appearance noise, significantly enhancing the spatial continuity and physical plausibility of the identified functional regions. Extensive experiments conducted on the Fine-AGDDO15 dataset and a real-world robotic platform demonstrate that TRACER significantly improves affordance grounding precision across diverse textures and patterns inherent to deformable objects. More importantly, it enhances the success rate of long-horizon tasks, effectively bridging the gap between high-level semantic reasoning and low-level physical execution. The source code and dataset will be made publicly available at https://github.com/Dikay1/TRACER.
OneOcc: Semantic Occupancy Prediction for Legged Robots with a Single Panoramic Camera
Nov 05, 2025Robust 3D semantic occupancy is crucial for legged/humanoid robots, yet most semantic scene completion (SSC) systems target wheeled platforms with forward-facing sensors. We present OneOcc, a vision-only panoramic SSC framework designed for gait-introduced body jitter and 360{\deg} continuity. OneOcc combines: (i) Dual-Projection fusion (DP-ER) to exploit the annular panorama and its equirectangular unfolding, preserving 360{\deg} continuity and grid alignment; (ii) Bi-Grid Voxelization (BGV) to reason in Cartesian and cylindrical-polar spaces, reducing discretization bias and sharpening free/occupied boundaries; (iii) a lightweight decoder with Hierarchical AMoE-3D for dynamic multi-scale fusion and better long-range/occlusion reasoning; and (iv) plug-and-play Gait Displacement Compensation (GDC) learning feature-level motion correction without extra sensors. We also release two panoramic occupancy benchmarks: QuadOcc (real quadruped, first-person 360{\deg}) and Human360Occ (H3O) (CARLA human-ego 360{\deg} with RGB, Depth, semantic occupancy; standardized within-/cross-city splits). OneOcc sets new state-of-the-art (SOTA): on QuadOcc it beats strong vision baselines and popular LiDAR ones; on H3O it gains +3.83 mIoU (within-city) and +8.08 (cross-city). Modules are lightweight, enabling deployable full-surround perception for legged/humanoid robots. Datasets and code will be publicly available at https://github.com/MasterHow/OneOcc.
Panoramic Out-of-Distribution Segmentation
May 06, 2025Panoramic imaging enables capturing 360{\deg} images with an ultra-wide Field-of-View (FoV) for dense omnidirectional perception. However, current panoramic semantic segmentation methods fail to identify outliers, and pinhole Out-of-distribution Segmentation (OoS) models perform unsatisfactorily in the panoramic domain due to background clutter and pixel distortions. To address these issues, we introduce a new task, Panoramic Out-of-distribution Segmentation (PanOoS), achieving OoS for panoramas. Furthermore, we propose the first solution, POS, which adapts to the characteristics of panoramic images through text-guided prompt distribution learning. Specifically, POS integrates a disentanglement strategy designed to materialize the cross-domain generalization capability of CLIP. The proposed Prompt-based Restoration Attention (PRA) optimizes semantic decoding by prompt guidance and self-adaptive correction, while Bilevel Prompt Distribution Learning (BPDL) refines the manifold of per-pixel mask embeddings via semantic prototype supervision. Besides, to compensate for the scarcity of PanOoS datasets, we establish two benchmarks: DenseOoS, which features diverse outliers in complex environments, and QuadOoS, captured by a quadruped robot with a panoramic annular lens system. Extensive experiments demonstrate superior performance of POS, with AuPRC improving by 34.25% and FPR95 decreasing by 21.42% on DenseOoS, outperforming state-of-the-art pinhole-OoS methods. Moreover, POS achieves leading closed-set segmentation capabilities. Code and datasets will be available at https://github.com/MengfeiD/PanOoS.
Omnidirectional Multi-Object Tracking
Mar 06, 2025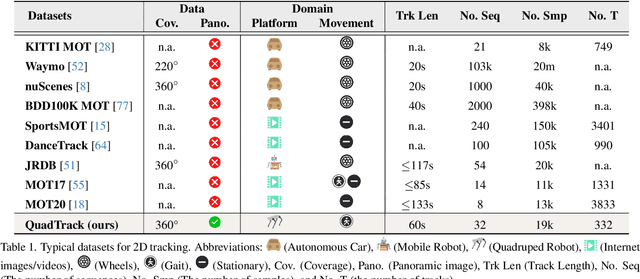
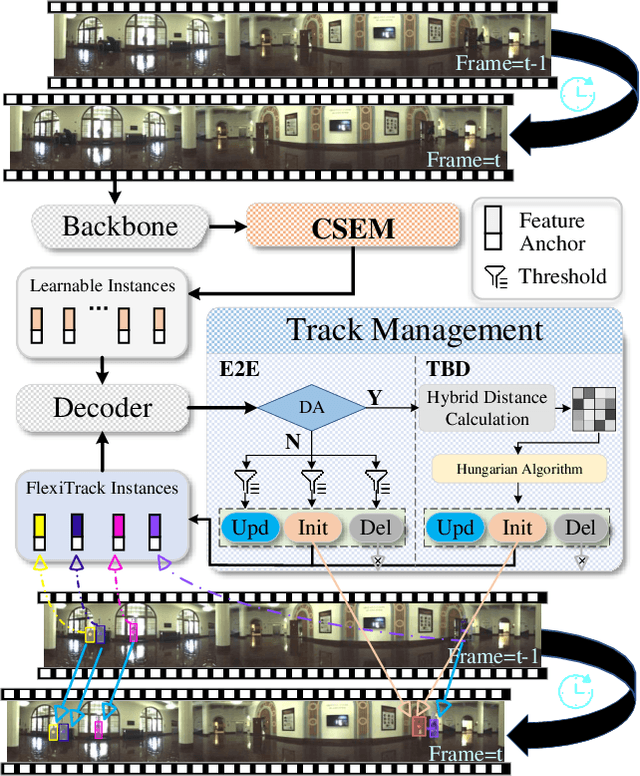
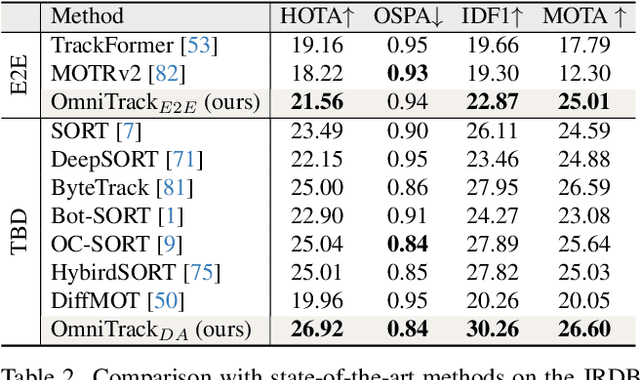
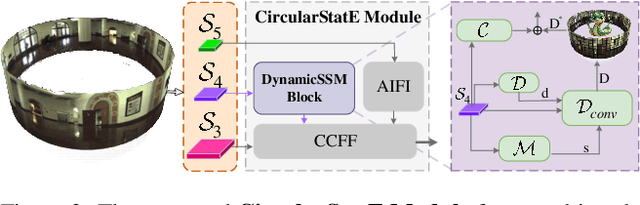
Panoramic imagery, with its 360{\deg} field of view, offers comprehensive information to support Multi-Object Tracking (MOT) in capturing spatial and temporal relationships of surrounding objects. However, most MOT algorithms are tailored for pinhole images with limited views, impairing their effectiveness in panoramic settings. Additionally, panoramic image distortions, such as resolution loss, geometric deformation, and uneven lighting, hinder direct adaptation of existing MOT methods, leading to significant performance degradation. To address these challenges, we propose OmniTrack, an omnidirectional MOT framework that incorporates Tracklet Management to introduce temporal cues, FlexiTrack Instances for object localization and association, and the CircularStatE Module to alleviate image and geometric distortions. This integration enables tracking in large field-of-view scenarios, even under rapid sensor motion. To mitigate the lack of panoramic MOT datasets, we introduce the QuadTrack dataset--a comprehensive panoramic dataset collected by a quadruped robot, featuring diverse challenges such as wide fields of view, intense motion, and complex environments. Extensive experiments on the public JRDB dataset and the newly introduced QuadTrack benchmark demonstrate the state-of-the-art performance of the proposed framework. OmniTrack achieves a HOTA score of 26.92% on JRDB, representing an improvement of 3.43%, and further achieves 23.45% on QuadTrack, surpassing the baseline by 6.81%. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack.
One-Shot Affordance Grounding of Deformable Objects in Egocentric Organizing Scenes
Mar 03, 2025Deformable object manipulation in robotics presents significant challenges due to uncertainties in component properties, diverse configurations, visual interference, and ambiguous prompts. These factors complicate both perception and control tasks. To address these challenges, we propose a novel method for One-Shot Affordance Grounding of Deformable Objects (OS-AGDO) in egocentric organizing scenes, enabling robots to recognize previously unseen deformable objects with varying colors and shapes using minimal samples. Specifically, we first introduce the Deformable Object Semantic Enhancement Module (DefoSEM), which enhances hierarchical understanding of the internal structure and improves the ability to accurately identify local features, even under conditions of weak component information. Next, we propose the ORB-Enhanced Keypoint Fusion Module (OEKFM), which optimizes feature extraction of key components by leveraging geometric constraints and improves adaptability to diversity and visual interference. Additionally, we propose an instance-conditional prompt based on image data and task context, effectively mitigates the issue of region ambiguity caused by prompt words. To validate these methods, we construct a diverse real-world dataset, AGDDO15, which includes 15 common types of deformable objects and their associated organizational actions. Experimental results demonstrate that our approach significantly outperforms state-of-the-art methods, achieving improvements of 6.2%, 3.2%, and 2.9% in KLD, SIM, and NSS metrics, respectively, while exhibiting high generalization performance. Source code and benchmark dataset will be publicly available at https://github.com/Dikay1/OS-AGDO.