 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiQuE: Hierarchical Question Embedding Network for Multimodal Depression Detection
Aug 07, 2024

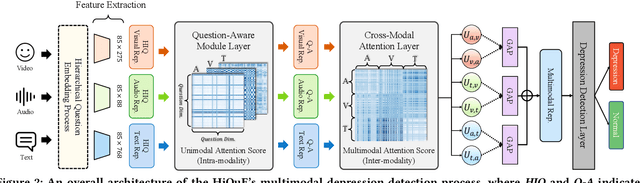

The utilization of automated depression detection significantly enhances early intervention for individuals experiencing depression. Despite numerous proposals on automated depression detection using recorded clinical interview videos, limited attention has been paid to considering the hierarchical structure of the interview questions. In clinical interviews for diagnosing depression, clinicians use a structured questionnaire that includes routine baseline questions and follow-up questions to assess the interviewee's condition. This paper introduces HiQuE (Hierarchical Question Embedding network), a novel depression detection framework that leverages the hierarchical relationship between primary and follow-up questions in clinical interviews. HiQuE can effectively capture the importance of each question in diagnosing depression by learning mutual information across multiple modalities. We conduct extensive experiments on the widely-used clinical interview data, DAIC-WOZ, where our model outperforms other state-of-the-art multimodal depression detection models and emotion recognition models, showcasing its clinical utility in depression detection.
* 11 pages, 6 figures, Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM '24)
WWW: Where, Which and Whatever Enhancing Interpretability in Multimodal Deepfake Detection
Aug 06, 2024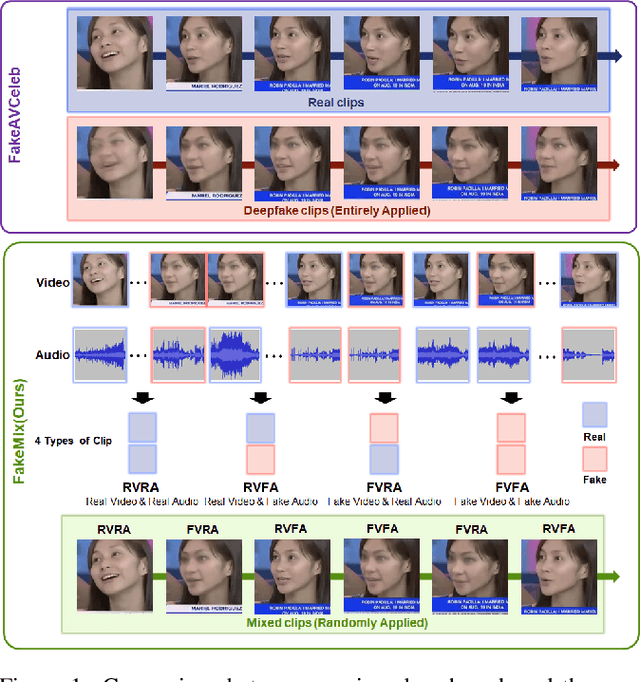


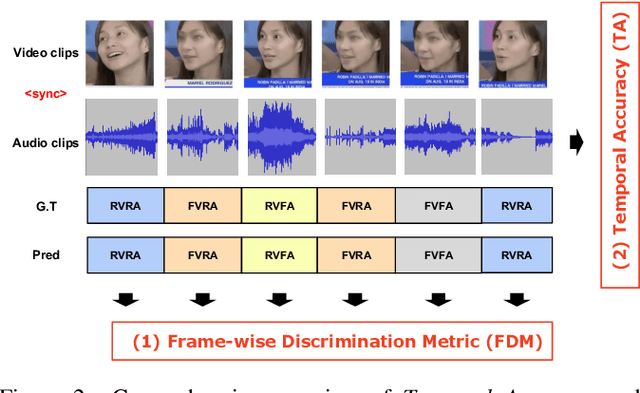
All current benchmarks for multimodal deepfake detection manipulate entire frames using various generation techniques, resulting in oversaturated detection accuracies exceeding 94% at the video-level classification. However, these benchmarks struggle to detect dynamic deepfake attacks with challenging frame-by-frame alterations presented in real-world scenarios. To address this limitation, we introduce FakeMix, a novel clip-level evaluation benchmark aimed at identifying manipulated segments within both video and audio, providing insight into the origins of deepfakes. Furthermore, we propose novel evaluation metrics, Temporal Accuracy (TA) and Frame-wise Discrimination Metric (FDM), to assess the robustness of deepfake detection models. Evaluating state-of-the-art models against diverse deepfake benchmarks, particularly FakeMix, demonstrates the effectiveness of our approach comprehensively. Specifically, while achieving an Average Precision (AP) of 94.2% at the video-level, the evaluation of the existing models at the clip-level using the proposed metrics, TA and FDM, yielded sharp declines in accuracy to 53.1%, and 52.1%, respectively.
Enhancing Temporal Action Localization: Advanced S6 Modeling with Recurrent Mechanism
Jul 18, 2024
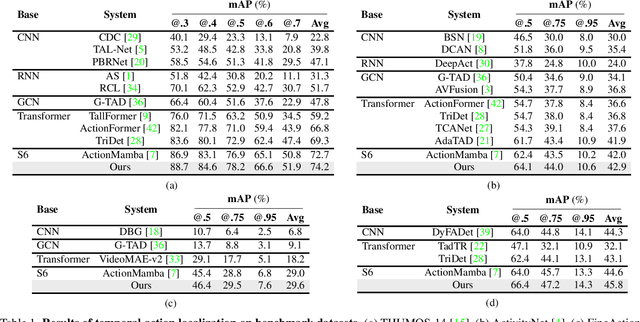

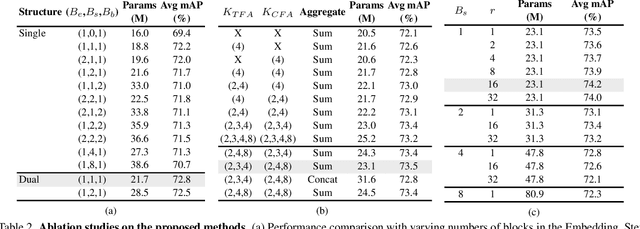
Temporal Action Localization (TAL) is a critical task in video analysis, identifying precise start and end times of actions. Existing methods like CNNs, RNNs, GCNs, and Transformers have limitations in capturing long-range dependencies and temporal causality. To address these challenges, we propose a novel TAL architecture leveraging the Selective State Space Model (S6). Our approach integrates the Feature Aggregated Bi-S6 block, Dual Bi-S6 structure, and a recurrent mechanism to enhance temporal and channel-wise dependency modeling without increasing parameter complexity. Extensive experiments on benchmark datasets demonstrate state-of-the-art results with mAP scores of 74.2% on THUMOS-14, 42.9% on ActivityNet, 29.6% on FineAction, and 45.8% on HACS. Ablation studies validate our method's effectiveness, showing that the Dual structure in the Stem module and the recurrent mechanism outperform traditional approaches. Our findings demonstrate the potential of S6-based models in TAL tasks, paving the way for future research.