 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWWW: Where, Which and Whatever Enhancing Interpretability in Multimodal Deepfake Detection
Paper and Code
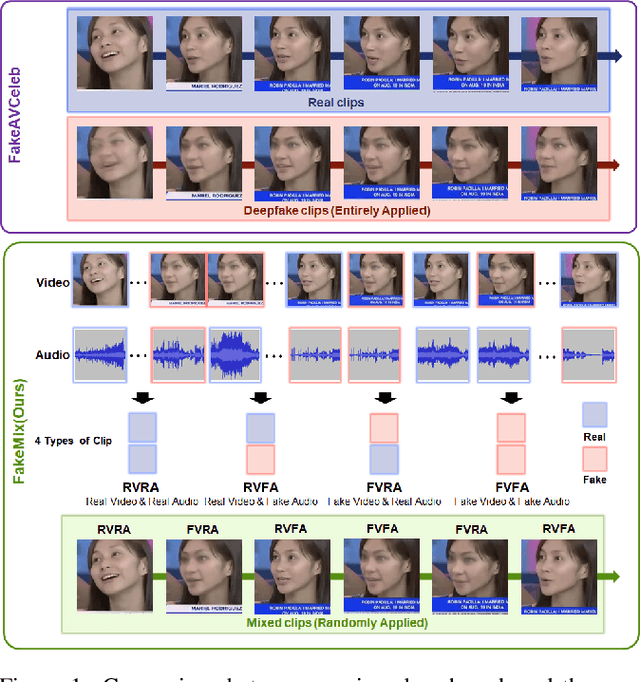


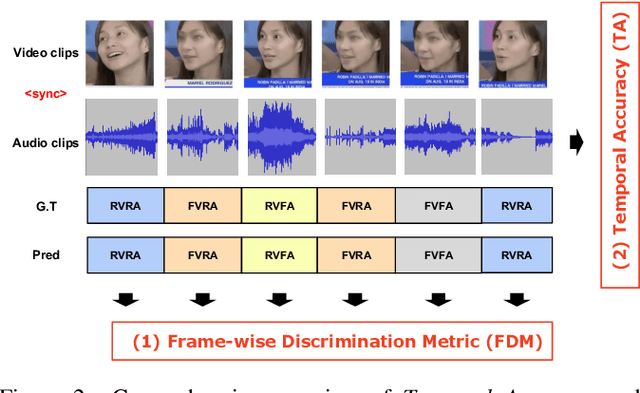
All current benchmarks for multimodal deepfake detection manipulate entire frames using various generation techniques, resulting in oversaturated detection accuracies exceeding 94% at the video-level classification. However, these benchmarks struggle to detect dynamic deepfake attacks with challenging frame-by-frame alterations presented in real-world scenarios. To address this limitation, we introduce FakeMix, a novel clip-level evaluation benchmark aimed at identifying manipulated segments within both video and audio, providing insight into the origins of deepfakes. Furthermore, we propose novel evaluation metrics, Temporal Accuracy (TA) and Frame-wise Discrimination Metric (FDM), to assess the robustness of deepfake detection models. Evaluating state-of-the-art models against diverse deepfake benchmarks, particularly FakeMix, demonstrates the effectiveness of our approach comprehensively. Specifically, while achieving an Average Precision (AP) of 94.2% at the video-level, the evaluation of the existing models at the clip-level using the proposed metrics, TA and FDM, yielded sharp declines in accuracy to 53.1%, and 52.1%, respectively.