 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWWW: Where, Which and Whatever Enhancing Interpretability in Multimodal Deepfake Detection
Aug 06, 2024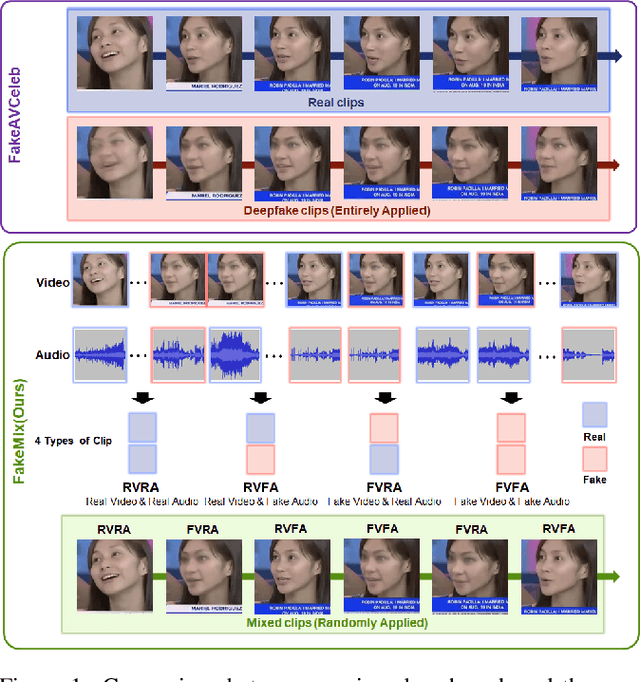


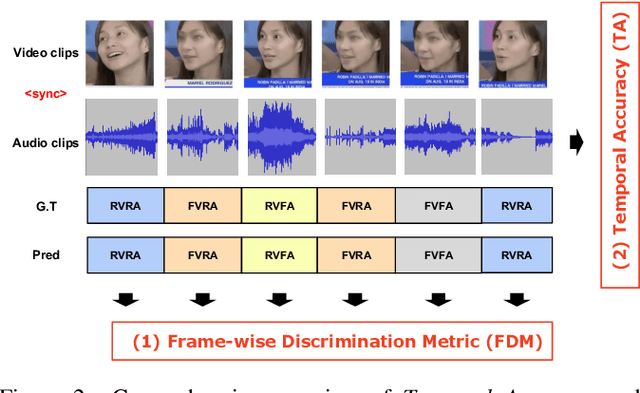
All current benchmarks for multimodal deepfake detection manipulate entire frames using various generation techniques, resulting in oversaturated detection accuracies exceeding 94% at the video-level classification. However, these benchmarks struggle to detect dynamic deepfake attacks with challenging frame-by-frame alterations presented in real-world scenarios. To address this limitation, we introduce FakeMix, a novel clip-level evaluation benchmark aimed at identifying manipulated segments within both video and audio, providing insight into the origins of deepfakes. Furthermore, we propose novel evaluation metrics, Temporal Accuracy (TA) and Frame-wise Discrimination Metric (FDM), to assess the robustness of deepfake detection models. Evaluating state-of-the-art models against diverse deepfake benchmarks, particularly FakeMix, demonstrates the effectiveness of our approach comprehensively. Specifically, while achieving an Average Precision (AP) of 94.2% at the video-level, the evaluation of the existing models at the clip-level using the proposed metrics, TA and FDM, yielded sharp declines in accuracy to 53.1%, and 52.1%, respectively.
Zero-Shot Cross-Lingual NER Using Phonemic Representations for Low-Resource Languages
Jun 23, 2024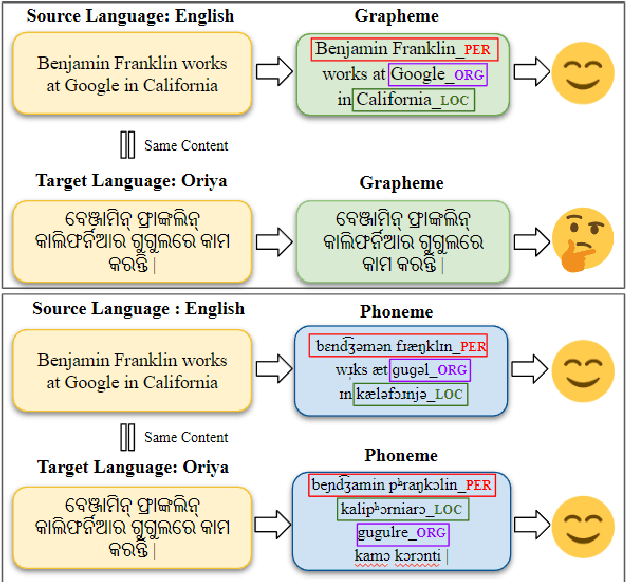



Existing zero-shot cross-lingual NER approaches require substantial prior knowledge of the target language, which is impractical for low-resource languages. In this paper, we propose a novel approach to NER using phonemic representation based on the International Phonetic Alphabet (IPA) to bridge the gap between representations of different languages. Our experiments show that our method significantly outperforms baseline models in extremely low-resource languages, with the highest average F-1 score (46.38%) and lowest standard deviation (12.67), particularly demonstrating its robustness with non-Latin scripts.
Mitigating the Linguistic Gap with Phonemic Representations for Robust Multilingual Language Understanding
Feb 22, 2024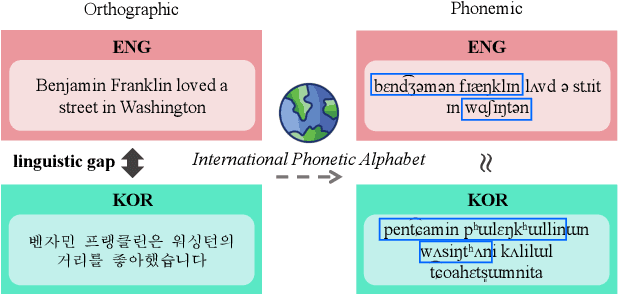
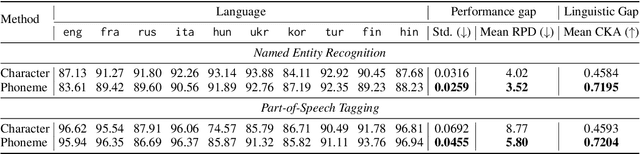
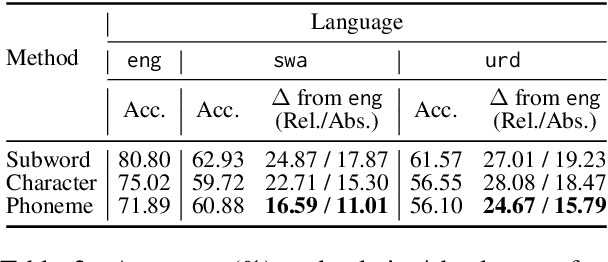
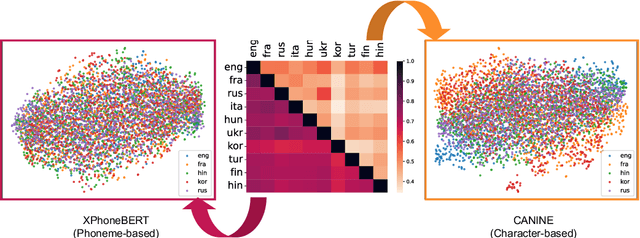
Approaches to improving multilingual language understanding often require multiple languages during the training phase, rely on complicated training techniques, and -- importantly -- struggle with significant performance gaps between high-resource and low-resource languages. We hypothesize that the performance gaps between languages are affected by linguistic gaps between those languages and provide a novel solution for robust multilingual language modeling by employing phonemic representations (specifically, using phonemes as input tokens to LMs rather than subwords). We present quantitative evidence from three cross-lingual tasks that demonstrate the effectiveness of phonemic representation, which is further justified by a theoretical analysis of the cross-lingual performance gap.