 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPLKG: Robust Prompt Learning with Knowledge Graph
Apr 21, 2023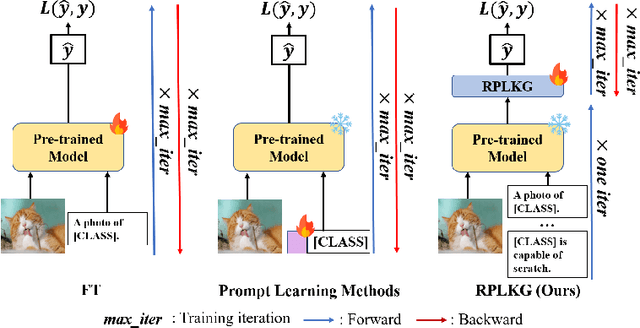
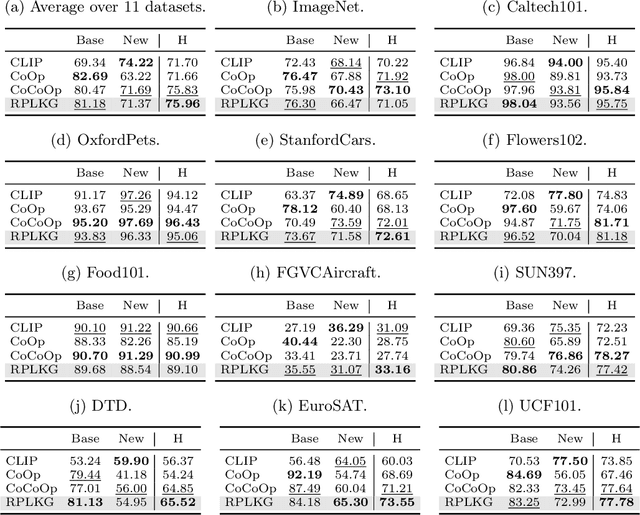

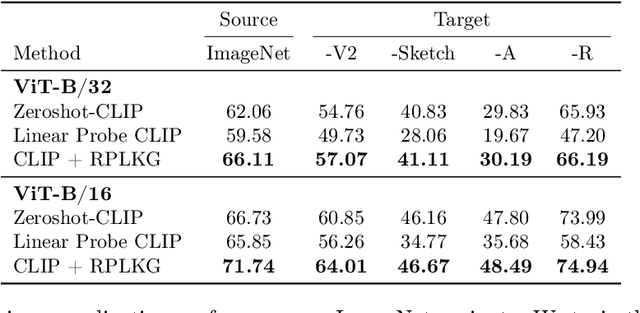
Large-scale pre-trained models have been known that they are transferable, and they generalize well on the unseen dataset. Recently, multimodal pre-trained models such as CLIP show significant performance improvement in diverse experiments. However, when the labeled dataset is limited, the generalization of a new dataset or domain is still challenging. To improve the generalization performance on few-shot learning, there have been diverse efforts, such as prompt learning and adapter. However, the current few-shot adaptation methods are not interpretable, and they require a high computation cost for adaptation. In this study, we propose a new method, robust prompt learning with knowledge graph (RPLKG). Based on the knowledge graph, we automatically design diverse interpretable and meaningful prompt sets. Our model obtains cached embeddings of prompt sets after one forwarding from a large pre-trained model. After that, model optimizes the prompt selection processes with GumbelSoftmax. In this way, our model is trained using relatively little memory and learning time. Also, RPLKG selects the optimal interpretable prompt automatically, depending on the dataset. In summary, RPLKG is i) interpretable, ii) requires small computation resources, and iii) easy to incorporate prior human knowledge. To validate the RPLKG, we provide comprehensive experimental results on few-shot learning, domain generalization and new class generalization setting. RPLKG shows a significant performance improvement compared to zero-shot learning and competitive performance against several prompt learning methods using much lower resources.
BlackVIP: Black-Box Visual Prompting for Robust Transfer Learning
Mar 26, 2023



With the surge of large-scale pre-trained models (PTMs), fine-tuning these models to numerous downstream tasks becomes a crucial problem. Consequently, parameter efficient transfer learning (PETL) of large models has grasped huge attention. While recent PETL methods showcase impressive performance, they rely on optimistic assumptions: 1) the entire parameter set of a PTM is available, and 2) a sufficiently large memory capacity for the fine-tuning is equipped. However, in most real-world applications, PTMs are served as a black-box API or proprietary software without explicit parameter accessibility. Besides, it is hard to meet a large memory requirement for modern PTMs. In this work, we propose black-box visual prompting (BlackVIP), which efficiently adapts the PTMs without knowledge about model architectures and parameters. BlackVIP has two components; 1) Coordinator and 2) simultaneous perturbation stochastic approximation with gradient correction (SPSA-GC). The Coordinator designs input-dependent image-shaped visual prompts, which improves few-shot adaptation and robustness on distribution/location shift. SPSA-GC efficiently estimates the gradient of a target model to update Coordinator. Extensive experiments on 16 datasets demonstrate that BlackVIP enables robust adaptation to diverse domains without accessing PTMs' parameters, with minimal memory requirements. Code: \url{https://github.com/changdaeoh/BlackVIP}