 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlackVIP: Black-Box Visual Prompting for Robust Transfer Learning
Mar 26, 2023



With the surge of large-scale pre-trained models (PTMs), fine-tuning these models to numerous downstream tasks becomes a crucial problem. Consequently, parameter efficient transfer learning (PETL) of large models has grasped huge attention. While recent PETL methods showcase impressive performance, they rely on optimistic assumptions: 1) the entire parameter set of a PTM is available, and 2) a sufficiently large memory capacity for the fine-tuning is equipped. However, in most real-world applications, PTMs are served as a black-box API or proprietary software without explicit parameter accessibility. Besides, it is hard to meet a large memory requirement for modern PTMs. In this work, we propose black-box visual prompting (BlackVIP), which efficiently adapts the PTMs without knowledge about model architectures and parameters. BlackVIP has two components; 1) Coordinator and 2) simultaneous perturbation stochastic approximation with gradient correction (SPSA-GC). The Coordinator designs input-dependent image-shaped visual prompts, which improves few-shot adaptation and robustness on distribution/location shift. SPSA-GC efficiently estimates the gradient of a target model to update Coordinator. Extensive experiments on 16 datasets demonstrate that BlackVIP enables robust adaptation to diverse domains without accessing PTMs' parameters, with minimal memory requirements. Code: \url{https://github.com/changdaeoh/BlackVIP}
Learning Fair Representation via Distributional Contrastive Disentanglement
Jun 17, 2022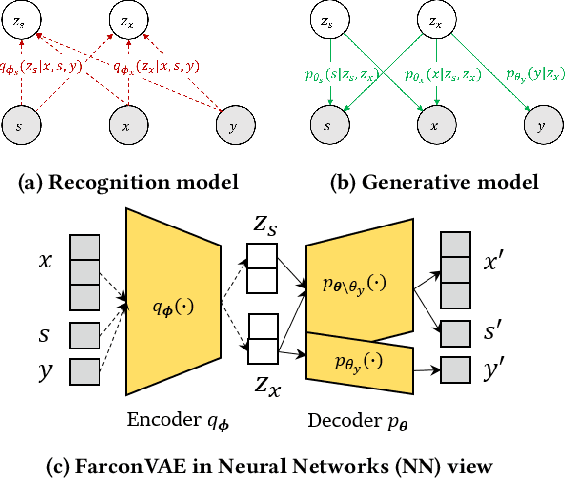
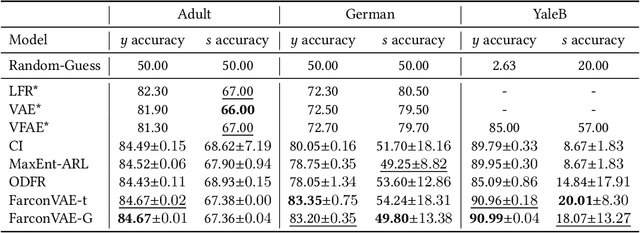
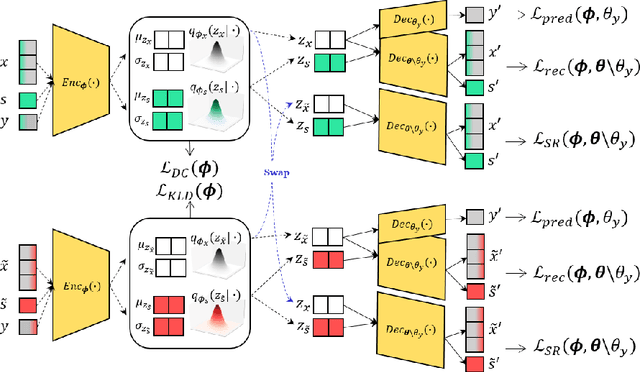
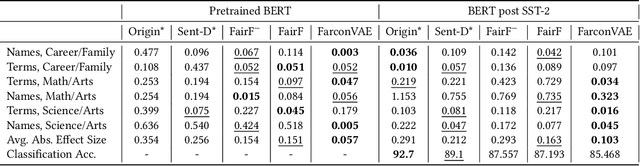
Learning fair representation is crucial for achieving fairness or debiasing sensitive information. Most existing works rely on adversarial representation learning to inject some invariance into representation. However, adversarial learning methods are known to suffer from relatively unstable training, and this might harm the balance between fairness and predictiveness of representation. We propose a new approach, learning FAir Representation via distributional CONtrastive Variational AutoEncoder (FarconVAE), which induces the latent space to be disentangled into sensitive and nonsensitive parts. We first construct the pair of observations with different sensitive attributes but with the same labels. Then, FarconVAE enforces each non-sensitive latent to be closer, while sensitive latents to be far from each other and also far from the non-sensitive latent by contrasting their distributions. We provide a new type of contrastive loss motivated by Gaussian and Student-t kernels for distributional contrastive learning with theoretical analysis. Besides, we adopt a new swap-reconstruction loss to boost the disentanglement further. FarconVAE shows superior performance on fairness, pretrained model debiasing, and domain generalization tasks from various modalities, including tabular, image, and text.
EXoN: EXplainable encoder Network
May 28, 2021
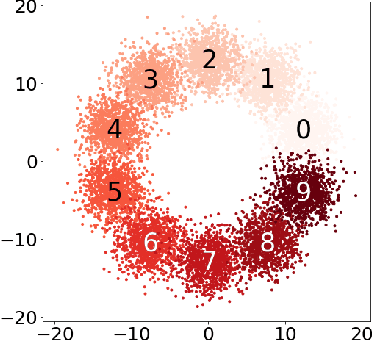

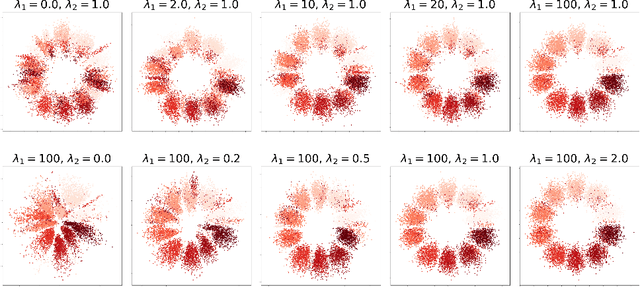
We propose a new semi-supervised learning method of Variational AutoEncoder (VAE) which yields an explainable latent space by EXplainable encoder Network (EXoN). The EXoN provides two useful tools for implementing VAE. First, we can freely assign a conceptual center of the latent distribution for a specific label. The latent space of VAE is separated with the multi-modal property of the Gaussian mixture distribution according to the labels of observations. Next, we can easily investigate the latent subspace by a simple statistics obtained from the EXoN. We found that both the negative cross-entropy and the Kullback-Leibler divergence play a crucial role in constructing explainable latent space and the variability of generated samples from our proposed model depends on a specific subspace, called `activated latent subspace'. With MNIST and CIFAR-10 dataset, we show that the EXoN can produce an explainable latent space that effectively represents the labels and characteristics of the images.
Primal path algorithm for compositional data analysis
Dec 21, 2018



Compositional data have two unique characteristics compared to typical multivariate data: the observed values are nonnegative and their summand is exactly one. To reflect these characteristics, a specific regularized regression model with linear constraints is commonly used. However, linear constraints incur additional computational time, which becomes severe in high-dimensional cases. As such, we propose an efficient solution path algorithm for a $l_1$ regularized regression with compositional data. The algorithm is then extended to a classification model with compositional predictors. We also compare its computational speed with that of previously developed algorithms and apply the proposed algorithm to analyze human gut microbiome data.