 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDUS: Memory-Infused Depth Up-Scaling
Dec 15, 2025



Scaling large language models (LLMs) demands approaches that increase capacity without incurring excessive parameter growth or inference cost. Depth Up-Scaling (DUS) has emerged as a promising strategy by duplicating layers and applying Continual Pre-training (CPT), but its reliance on feed-forward networks (FFNs) limits efficiency and attainable gains. We introduce Memory-Infused Depth Up-Scaling (MIDUS), which replaces FFNs in duplicated blocks with a head-wise memory (HML) layer. Motivated by observations that attention heads have distinct roles both across and within layers, MIDUS assigns an independent memory bank to each head, enabling head-wise retrieval and injecting information into subsequent layers while preserving head-wise functional structure. This design combines sparse memory access with head-wise representations and incorporates an efficient per-head value factorization module, thereby relaxing the usual efficiency-performance trade-off. Across our CPT experiments, MIDUS exhibits robust performance improvements over strong DUS baselines while maintaining a highly efficient parameter footprint. Our findings establish MIDUS as a compelling and resource-efficient alternative to conventional FFN replication for depth up-scaling by leveraging its head-wise memory design.
Sharpness-aware Minimization for Worst Case Optimization
Oct 24, 2022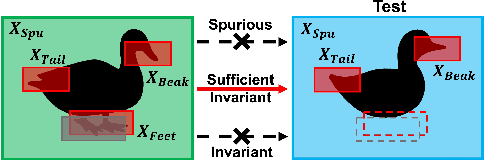
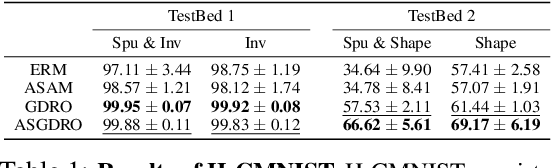
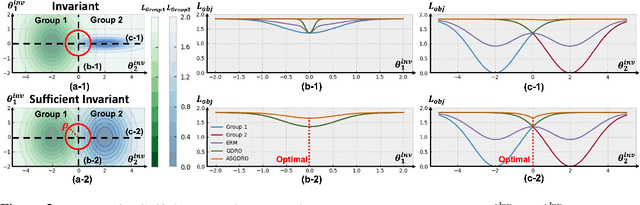
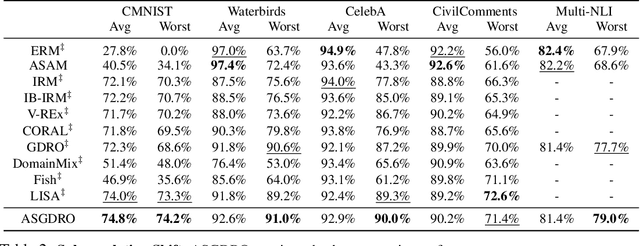
Improvement of worst group performance and generalization performance are core problems of current machine learning. There are diverse efforts to increase performance, such as weight norm penalty and data augmentation, but the improvements are limited. Recently, there have been two promising approaches to increase the worst group performance and generalization performance, respectively. Distributionally robust optimization (DRO) focuses on the worst or hardest group to improve the worst-group performance. Besides, sharpness-aware minimization (SAM) finds the flat minima to increase the generalization ability on an unseen dataset. They show significant performance improvements on the worst-group dataset and unseen dataset, respectively. However, DRO does not guarantee flatness, and SAM does not guarantee the worst group performance improvement. In other words, DRO and SAM may fail to increase the worst group performance when the training and test dataset shift occurs. In this study, we propose a new approach, the sharpness-aware group distributionally robust optimization (SGDRO). SGDRO finds the flat-minima that generalizes well on the worst group dataset. Different from DRO and SAM, SGDRO contributes to improving the generalization ability even the distribution shift occurs. We validate that SGDRO shows the smaller maximum eigenvalue and improved performance in the worst group.
Learning Fair Representation via Distributional Contrastive Disentanglement
Jun 17, 2022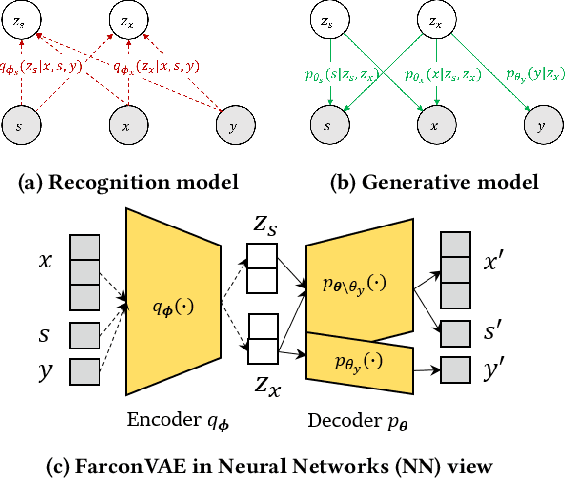
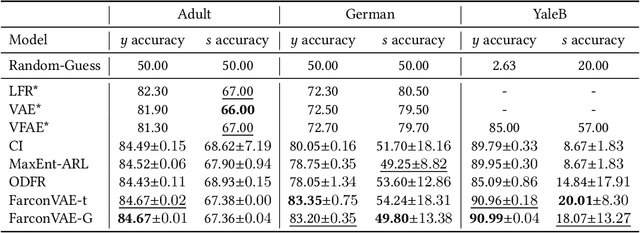
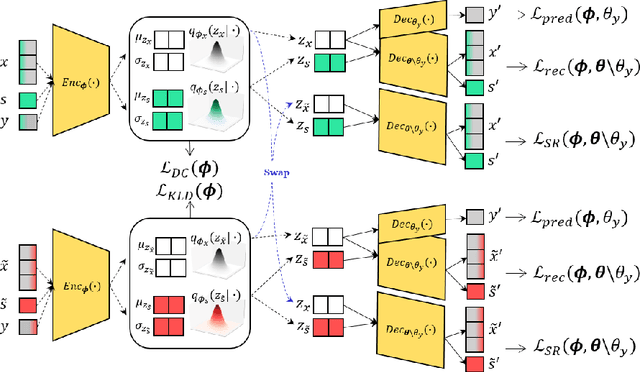
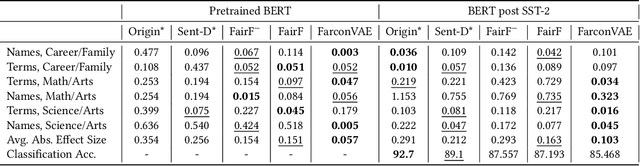
Learning fair representation is crucial for achieving fairness or debiasing sensitive information. Most existing works rely on adversarial representation learning to inject some invariance into representation. However, adversarial learning methods are known to suffer from relatively unstable training, and this might harm the balance between fairness and predictiveness of representation. We propose a new approach, learning FAir Representation via distributional CONtrastive Variational AutoEncoder (FarconVAE), which induces the latent space to be disentangled into sensitive and nonsensitive parts. We first construct the pair of observations with different sensitive attributes but with the same labels. Then, FarconVAE enforces each non-sensitive latent to be closer, while sensitive latents to be far from each other and also far from the non-sensitive latent by contrasting their distributions. We provide a new type of contrastive loss motivated by Gaussian and Student-t kernels for distributional contrastive learning with theoretical analysis. Besides, we adopt a new swap-reconstruction loss to boost the disentanglement further. FarconVAE shows superior performance on fairness, pretrained model debiasing, and domain generalization tasks from various modalities, including tabular, image, and text.