 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-aware Minimization for Worst Case Optimization
Paper and Code
Oct 24, 2022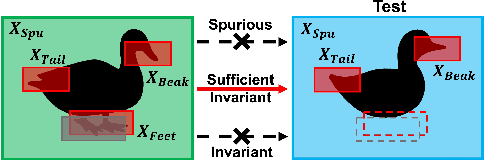
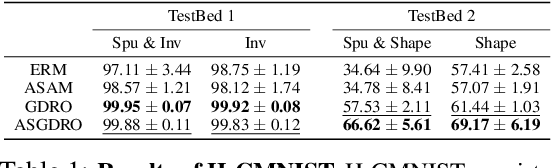
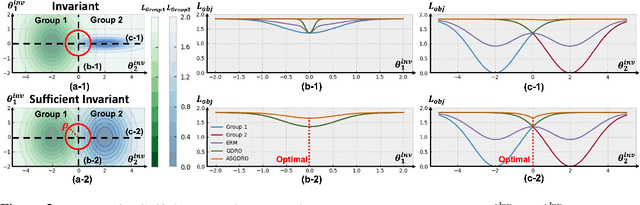
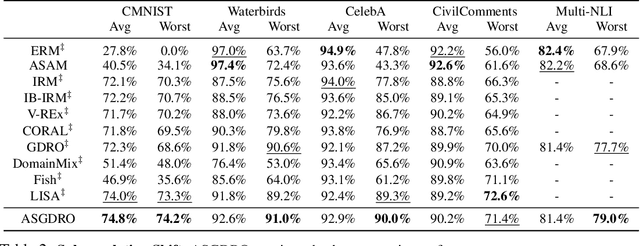
Improvement of worst group performance and generalization performance are core problems of current machine learning. There are diverse efforts to increase performance, such as weight norm penalty and data augmentation, but the improvements are limited. Recently, there have been two promising approaches to increase the worst group performance and generalization performance, respectively. Distributionally robust optimization (DRO) focuses on the worst or hardest group to improve the worst-group performance. Besides, sharpness-aware minimization (SAM) finds the flat minima to increase the generalization ability on an unseen dataset. They show significant performance improvements on the worst-group dataset and unseen dataset, respectively. However, DRO does not guarantee flatness, and SAM does not guarantee the worst group performance improvement. In other words, DRO and SAM may fail to increase the worst group performance when the training and test dataset shift occurs. In this study, we propose a new approach, the sharpness-aware group distributionally robust optimization (SGDRO). SGDRO finds the flat-minima that generalizes well on the worst group dataset. Different from DRO and SAM, SGDRO contributes to improving the generalization ability even the distribution shift occurs. We validate that SGDRO shows the smaller maximum eigenvalue and improved performance in the worst group.