 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-driven Embedding Convolution
Jul 28, 2025Text embeddings are essential components in modern NLP pipelines. While numerous embedding models have been proposed, their performance varies across domains, and no single model consistently excels across all tasks. This variability motivates the use of ensemble techniques to combine complementary strengths. However, most existing ensemble methods operate on deterministic embeddings and fail to account for model-specific uncertainty, limiting their robustness and reliability in downstream applications. To address these limitations, we propose Uncertainty-driven Embedding Convolution (UEC). UEC first transforms deterministic embeddings into probabilistic ones in a post-hoc manner. It then computes adaptive ensemble weights based on embedding uncertainty, grounded in a Bayes-optimal solution under a surrogate loss. Additionally, UEC introduces an uncertainty-aware similarity function that directly incorporates uncertainty into similarity scoring. Extensive experiments on retrieval, classification, and semantic similarity benchmarks demonstrate that UEC consistently improves both performance and robustness by leveraging principled uncertainty modeling.
Flat Posterior Does Matter For Bayesian Transfer Learning
Jun 21, 2024



The large-scale pre-trained neural network has achieved notable success in enhancing performance for downstream tasks. Another promising approach for generalization is Bayesian Neural Network (BNN), which integrates Bayesian methods into neural network architectures, offering advantages such as Bayesian Model averaging (BMA) and uncertainty quantification. Despite these benefits, transfer learning for BNNs has not been widely investigated and shows limited improvement. We hypothesize that this issue arises from the inability to find flat minima, which is crucial for generalization performance. To address this, we evaluate the sharpness of BNNs in various settings, revealing their insufficiency in seeking flat minima and the influence of flatness on BMA performance. Therefore, we propose Sharpness-aware Bayesian Model Averaging (SA-BMA), a Bayesian-fitting flat posterior seeking optimizer integrated with Bayesian transfer learning. SA-BMA calculates the divergence between posteriors in the parameter space, aligning with the nature of BNNs, and serves as a generalized version of existing sharpness-aware optimizers. We validate that SA-BMA improves generalization performance in few-shot classification and distribution shift scenarios by ensuring flatness.
Sharpness-aware Minimization for Worst Case Optimization
Oct 24, 2022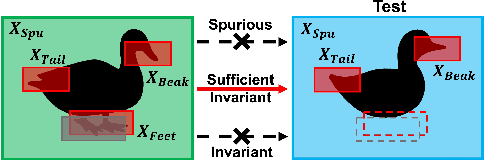
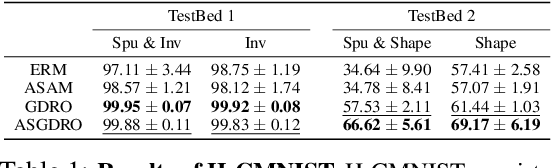
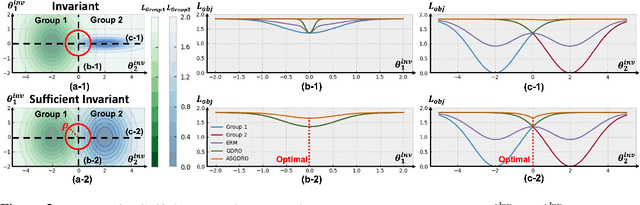
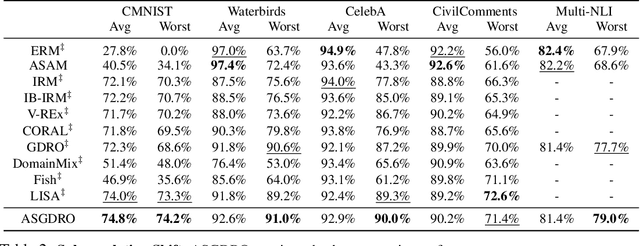
Improvement of worst group performance and generalization performance are core problems of current machine learning. There are diverse efforts to increase performance, such as weight norm penalty and data augmentation, but the improvements are limited. Recently, there have been two promising approaches to increase the worst group performance and generalization performance, respectively. Distributionally robust optimization (DRO) focuses on the worst or hardest group to improve the worst-group performance. Besides, sharpness-aware minimization (SAM) finds the flat minima to increase the generalization ability on an unseen dataset. They show significant performance improvements on the worst-group dataset and unseen dataset, respectively. However, DRO does not guarantee flatness, and SAM does not guarantee the worst group performance improvement. In other words, DRO and SAM may fail to increase the worst group performance when the training and test dataset shift occurs. In this study, we propose a new approach, the sharpness-aware group distributionally robust optimization (SGDRO). SGDRO finds the flat-minima that generalizes well on the worst group dataset. Different from DRO and SAM, SGDRO contributes to improving the generalization ability even the distribution shift occurs. We validate that SGDRO shows the smaller maximum eigenvalue and improved performance in the worst group.
Finding Inverse Document Frequency Information in BERT
Feb 24, 2022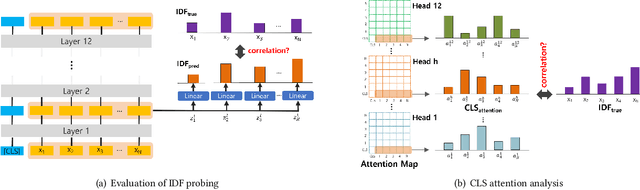

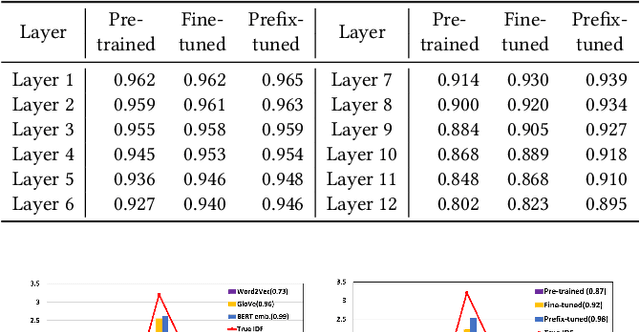

For many decades, BM25 and its variants have been the dominant document retrieval approach, where their two underlying features are Term Frequency (TF) and Inverse Document Frequency (IDF). The traditional approach, however, is being rapidly replaced by Neural Ranking Models (NRMs) that can exploit semantic features. In this work, we consider BERT-based NRMs and study if IDF information is present in the NRMs. This simple question is interesting because IDF has been indispensable for the traditional lexical matching, but global features like IDF are not explicitly learned by neural language models including BERT. We adopt linear probing as the main analysis tool because typical BERT based NRMs utilize linear or inner-product based score aggregators. We analyze input embeddings, representations of all BERT layers, and the self-attention weights of CLS. By studying MS-MARCO dataset with three BERT-based models, we show that all of them contain information that is strongly dependent on IDF.
Optimal Transport, CycleGAN, and Penalized LS for Unsupervised Learning in Inverse Problems
Sep 25, 2019
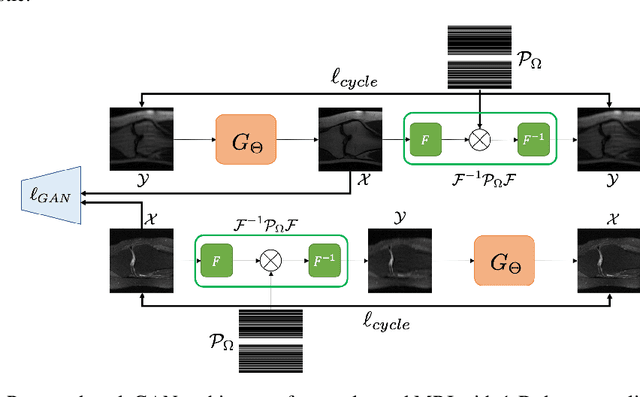

The penalized least squares (PLS) is a classic approach to inverse problems, where a regularization term is added to stabilize the solution. Optimal transport (OT) is another mathematical framework for computer vision tasks by providing means to transport one measure to another at a minimal cost. Cycle-consistent generative adversarial network (cycleGAN) is a recent extension of GAN to learn target distributions with less mode collapsing behaviour. Although similar in that no supervised training is required, the algorithms look different, so the mathematical relationship between these approaches is not clear. In this article, we provide an important advance to unveil the missing link. Specifically, we reveal that a cycleGAN architecture can be derived as a dual formulation of the optimal transport problem, if the PLS with a deep learning penalty is used as a transport cost between the two probability measures from measurements and unknown images. This suggests that cycleGAN can be considered as a stochastic generalization of classical PLS approaches. Our derivation is so general that various types of cycleGAN architecture can be easily derived by merely changing the transport cost. As proofs of concept, this paper provides novel cycleGAN architecture for unsupervised learning in accelerated MRI and deconvolution microscopy problems, which confirm the efficacy and the flexibility of the theory.
CycleGAN with a Blur Kernel for Deconvolution Microscopy: Optimal Transport Geometry
Aug 26, 2019
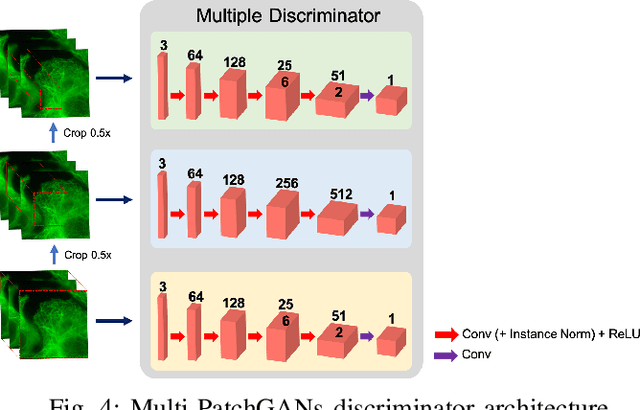
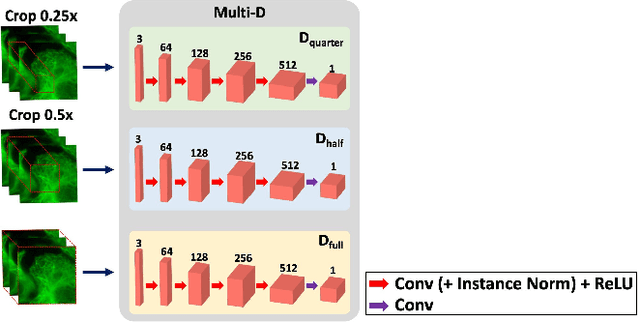
Deconvolution microscopy has been extensively used to improve the resolution of the widefield fluorescent microscopy. However, classical deconvolution approaches require the measurement or estimation of the point spread function (PSF), and are usually computationally expensive. Recently, convolutional neural network (CNN) approaches have been extensively studied as fast and high performance alternatives. Unfortunately, the CNN approaches usually require matched high resolution images for supervised training. In this paper, we present a novel unsupervised cycle-consistent generative adversarial network (cycleGAN) with a linear blur kernel, which can be used for both blind- and non-blind image deconvolution. In contrast to the conventional cycleGAN approaches that require two generators, the proposed cycleGAN approach needs only a single generator, which significantly improves the robustness of network training. We show that the proposed architecture is indeed a dual formulation of an optimal transport problem that uses a special form of penalized least squares as transport cost. Experimental results using simulated and real experimental data confirm the efficacy of the algorithm.
Blind Deconvolution Microscopy Using Cycle Consistent CNN with Explicit PSF Layer
Apr 05, 2019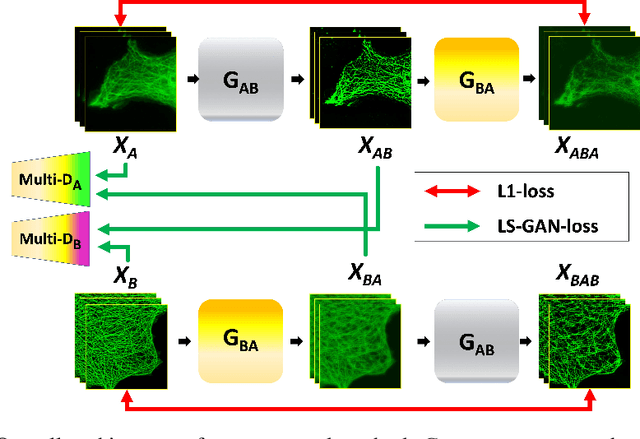
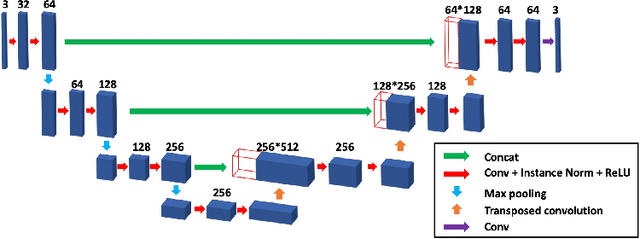

Deconvolution microscopy has been extensively used to improve the resolution of the widefield fluorescent microscopy. Conventional approaches, which usually require the point spread function (PSF) measurement or blind estimation, are however computationally expensive. Recently, CNN based approaches have been explored as a fast and high performance alternative. In this paper, we present a novel unsupervised deep neural network for blind deconvolution based on cycle consistency and PSF modeling layers. In contrast to the recent CNN approaches for similar problem, the explicit PSF modeling layers improve the robustness of the algorithm. Experimental results confirm the efficacy of the algorithm.