 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDUS: Memory-Infused Depth Up-Scaling
Dec 15, 2025



Scaling large language models (LLMs) demands approaches that increase capacity without incurring excessive parameter growth or inference cost. Depth Up-Scaling (DUS) has emerged as a promising strategy by duplicating layers and applying Continual Pre-training (CPT), but its reliance on feed-forward networks (FFNs) limits efficiency and attainable gains. We introduce Memory-Infused Depth Up-Scaling (MIDUS), which replaces FFNs in duplicated blocks with a head-wise memory (HML) layer. Motivated by observations that attention heads have distinct roles both across and within layers, MIDUS assigns an independent memory bank to each head, enabling head-wise retrieval and injecting information into subsequent layers while preserving head-wise functional structure. This design combines sparse memory access with head-wise representations and incorporates an efficient per-head value factorization module, thereby relaxing the usual efficiency-performance trade-off. Across our CPT experiments, MIDUS exhibits robust performance improvements over strong DUS baselines while maintaining a highly efficient parameter footprint. Our findings establish MIDUS as a compelling and resource-efficient alternative to conventional FFN replication for depth up-scaling by leveraging its head-wise memory design.
LBC: Language-Based-Classifier for Out-Of-Variable Generalization
Aug 21, 2024



Large Language Models (LLMs) have great success in natural language processing tasks such as response generation. However, their use in tabular data has been limited due to their inferior performance compared to traditional machine learning models (TMLs) such as XGBoost. We find that the pre-trained knowledge of LLMs enables them to interpret new variables that appear in a test without additional training, a capability central to the concept of Out-of-Variable (OOV). From the findings, we propose a Language-Based-Classifier (LBC), a classifier that maximizes the benefits of LLMs to outperform TMLs on OOV tasks. LBC employs three key methodological strategies: 1) Categorical changes to adjust data to better fit the model's understanding, 2) Advanced order and indicator to enhance data representation to the model, and 3) Using verbalizer to map logit scores to classes during inference to generate model predictions. These strategies, combined with the pre-trained knowledge of LBC, emphasize the model's ability to effectively handle OOV tasks. We empirically and theoretically validate the superiority of LBC. LBC is the first study to apply an LLM-based model to OOV tasks. The source code is at https://github.com/sksmssh/LBCforOOVGen
Perturb-and-Compare Approach for Detecting Out-of-Distribution Samples in Constrained Access Environments
Aug 19, 2024Accessing machine learning models through remote APIs has been gaining prevalence following the recent trend of scaling up model parameters for increased performance. Even though these models exhibit remarkable ability, detecting out-of-distribution (OOD) samples remains a crucial safety concern for end users as these samples may induce unreliable outputs from the model. In this work, we propose an OOD detection framework, MixDiff, that is applicable even when the model's parameters or its activations are not accessible to the end user. To bypass the access restriction, MixDiff applies an identical input-level perturbation to a given target sample and a similar in-distribution (ID) sample, then compares the relative difference in the model outputs of these two samples. MixDiff is model-agnostic and compatible with existing output-based OOD detection methods. We provide theoretical analysis to illustrate MixDiff's effectiveness in discerning OOD samples that induce overconfident outputs from the model and empirically demonstrate that MixDiff consistently enhances the OOD detection performance on various datasets in vision and text domains.
Flat Posterior Does Matter For Bayesian Transfer Learning
Jun 21, 2024



The large-scale pre-trained neural network has achieved notable success in enhancing performance for downstream tasks. Another promising approach for generalization is Bayesian Neural Network (BNN), which integrates Bayesian methods into neural network architectures, offering advantages such as Bayesian Model averaging (BMA) and uncertainty quantification. Despite these benefits, transfer learning for BNNs has not been widely investigated and shows limited improvement. We hypothesize that this issue arises from the inability to find flat minima, which is crucial for generalization performance. To address this, we evaluate the sharpness of BNNs in various settings, revealing their insufficiency in seeking flat minima and the influence of flatness on BMA performance. Therefore, we propose Sharpness-aware Bayesian Model Averaging (SA-BMA), a Bayesian-fitting flat posterior seeking optimizer integrated with Bayesian transfer learning. SA-BMA calculates the divergence between posteriors in the parameter space, aligning with the nature of BNNs, and serves as a generalized version of existing sharpness-aware optimizers. We validate that SA-BMA improves generalization performance in few-shot classification and distribution shift scenarios by ensuring flatness.
Graph Perceiver IO: A General Architecture for Graph Structured Data
Sep 14, 2022
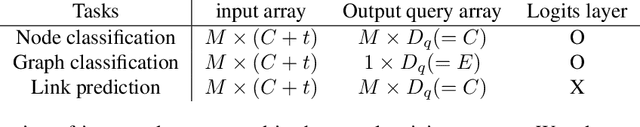
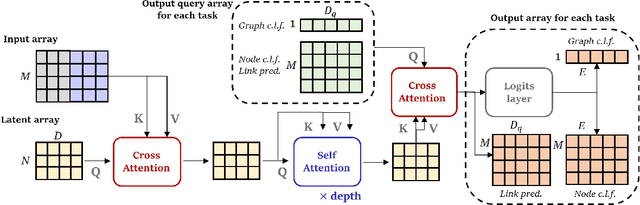
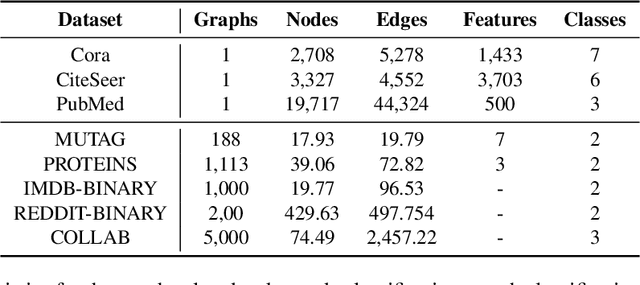
Multimodal machine learning has been widely studied for the development of general intelligence. Recently, the remarkable multimodal algorithms, the Perceiver and Perceiver IO, show competitive results for diverse dataset domains and tasks. However, recent works, Perceiver and Perceiver IO, have focused on heterogeneous modalities, including image, text, and speech, and there are few research works for graph structured datasets. A graph is one of the most generalized dataset structures, and we can represent the other dataset, including images, text, and speech, as graph structured data. A graph has an adjacency matrix different from other dataset domains such as text and image, and it is not trivial to handle the topological information, relational information, and canonical positional information. In this study, we provide a Graph Perceiver IO, the Perceiver IO for the graph structured dataset. We keep the main structure of the Graph Perceiver IO as the Perceiver IO because the Perceiver IO already handles the diverse dataset well, except for the graph structured dataset. The Graph Perceiver IO is a general method, and it can handle diverse datasets such as graph structured data as well as text and images. Comparing the graph neural networks, the Graph Perceiver IO requires a lower complexity, and it can incorporate the local and global information efficiently. We show that Graph Perceiver IO shows competitive results for diverse graph-related tasks, including node classification, graph classification, and link prediction.