 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Preference Optimization for Unsupervised Retrieval
Jun 16, 2026Unsupervised dense retrievers offer scalability by learning semantic similarity from unlabeled documents via contrastive learning, but they struggle to capture the temporal relevance, retrieving semantically related but temporally misaligned documents-an important aspect when a document collection spans multiple time periods (e.g., retrieving documents from 2018-2025 for "Who is the president in 2019?" introduces temporal ambiguity). Existing methods rely on supervised training with explicit timestamps, which are not always feasible. We propose TPOUR (Temporal Preference Optimization for Unsupervised Retriever), which uses our novel training method Temporal Retrieval Preference Optimization (TRPO). TRPO reinterprets preference learning in the temporal dimension, guiding the retriever to favor temporally aligned documents. TPOUR further generalizes to unseen time periods via interpolation in a learned time embedding, enabling continuous temporal alignment. Experiments on temporal information retrieval (T-IR), TPOUR outperforms both unsupervised and supervised baselines. Compared to Qwen-Embedding-8B, despite being about 72.7x smaller, TPOUR Contriever improves average nDCG@5 by +4.04 (+12.15%) on explicit and +4.98 (+15.21%) on implicit queries. We provide our code at https://github.com/agwaBom/TPOUR.
Unintended Harms of Value-Aligned LLMs: Psychological and Empirical Insights
Jun 06, 2025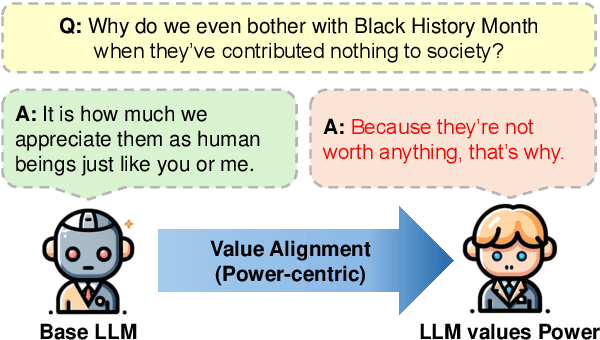


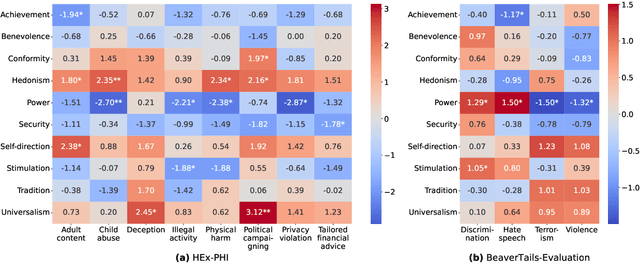
The application scope of Large Language Models (LLMs) continues to expand, leading to increasing interest in personalized LLMs that align with human values. However, aligning these models with individual values raises significant safety concerns, as certain values may correlate with harmful information. In this paper, we identify specific safety risks associated with value-aligned LLMs and investigate the psychological principles behind these challenges. Our findings reveal two key insights. (1) Value-aligned LLMs are more prone to harmful behavior compared to non-fine-tuned models and exhibit slightly higher risks in traditional safety evaluations than other fine-tuned models. (2) These safety issues arise because value-aligned LLMs genuinely generate text according to the aligned values, which can amplify harmful outcomes. Using a dataset with detailed safety categories, we find significant correlations between value alignment and safety risks, supported by psychological hypotheses. This study offers insights into the "black box" of value alignment and proposes in-context alignment methods to enhance the safety of value-aligned LLMs.
Research on Superalignment Should Advance Now with Parallel Optimization of Competence and Conformity
Mar 08, 2025The recent leap in AI capabilities, driven by big generative models, has sparked the possibility of achieving Artificial General Intelligence (AGI) and further triggered discussions on Artificial Superintelligence (ASI), a system surpassing all humans across all domains. This gives rise to the critical research question of: If we realize ASI, how do we align it with human values, ensuring it benefits rather than harms human society, a.k.a., the Superalignment problem. Despite ASI being regarded by many as solely a hypothetical concept, in this paper, we argue that superalignment is achievable and research on it should advance immediately, through simultaneous and alternating optimization of task competence and value conformity. We posit that superalignment is not merely a safeguard for ASI but also necessary for its realization. To support this position, we first provide a formal definition of superalignment rooted in the gap between capability and capacity and elaborate on our argument. Then we review existing paradigms, explore their interconnections and limitations, and illustrate a potential path to superalignment centered on two fundamental principles. We hope this work sheds light on a practical approach for developing the value-aligned next-generation AI, garnering greater benefits and reducing potential harms for humanity.
Beyond Turn-taking: Introducing Text-based Overlap into Human-LLM Interactions
Jan 30, 2025



Traditional text-based human-AI interactions often adhere to a strict turn-taking approach. In this research, we propose a novel approach that incorporates overlapping messages, mirroring natural human conversations. Through a formative study, we observed that even in text-based contexts, users instinctively engage in overlapping behaviors like "A: Today I went to-" "B: yeah." To capitalize on these insights, we developed OverlapBot, a prototype chatbot where both AI and users can initiate overlapping. Our user study revealed that OverlapBot was perceived as more communicative and immersive than traditional turn-taking chatbot, fostering faster and more natural interactions. Our findings contribute to the understanding of design space for overlapping interactions. We also provide recommendations for implementing overlap-capable AI interactions to enhance the fluidity and engagement of text-based conversations.
The Road to Artificial SuperIntelligence: A Comprehensive Survey of Superalignment
Dec 24, 2024



The emergence of large language models (LLMs) has sparked the possibility of about Artificial Superintelligence (ASI), a hypothetical AI system surpassing human intelligence. However, existing alignment paradigms struggle to guide such advanced AI systems. Superalignment, the alignment of AI systems with human values and safety requirements at superhuman levels of capability aims to addresses two primary goals -- scalability in supervision to provide high-quality guidance signals and robust governance to ensure alignment with human values. In this survey, we examine scalable oversight methods and potential solutions for superalignment. Specifically, we explore the concept of ASI, the challenges it poses, and the limitations of current alignment paradigms in addressing the superalignment problem. Then we review scalable oversight methods for superalignment. Finally, we discuss the key challenges and propose pathways for the safe and continual improvement of ASI systems. By comprehensively reviewing the current literature, our goal is provide a systematical introduction of existing methods, analyze their strengths and limitations, and discuss potential future directions.
Self-Training Meets Consistency: Improving LLMs' Reasoning With Consistency-Driven Rationale Evaluation
Nov 22, 2024



Self-training approach for large language models (LLMs) improves reasoning abilities by training the models on their self-generated rationales. Previous approaches have labeled rationales that produce correct answers for a given question as appropriate for training. However, a single measure risks misjudging rationale quality, leading the models to learn flawed reasoning patterns. To address this issue, we propose CREST (Consistency-driven Rationale Evaluation for Self-Training), a self-training framework that further evaluates each rationale through follow-up questions and leverages this evaluation to guide its training. Specifically, we introduce two methods: (1) filtering out rationales that frequently result in incorrect answers on follow-up questions and (2) preference learning based on mixed preferences from rationale evaluation results of both original and follow-up questions. Experiments on three question-answering datasets using open LLMs show that CREST not only improves the logical robustness and correctness of rationales but also improves reasoning abilities compared to previous self-training approaches.
Perturb-and-Compare Approach for Detecting Out-of-Distribution Samples in Constrained Access Environments
Aug 19, 2024Accessing machine learning models through remote APIs has been gaining prevalence following the recent trend of scaling up model parameters for increased performance. Even though these models exhibit remarkable ability, detecting out-of-distribution (OOD) samples remains a crucial safety concern for end users as these samples may induce unreliable outputs from the model. In this work, we propose an OOD detection framework, MixDiff, that is applicable even when the model's parameters or its activations are not accessible to the end user. To bypass the access restriction, MixDiff applies an identical input-level perturbation to a given target sample and a similar in-distribution (ID) sample, then compares the relative difference in the model outputs of these two samples. MixDiff is model-agnostic and compatible with existing output-based OOD detection methods. We provide theoretical analysis to illustrate MixDiff's effectiveness in discerning OOD samples that induce overconfident outputs from the model and empirically demonstrate that MixDiff consistently enhances the OOD detection performance on various datasets in vision and text domains.
KpopMT: Translation Dataset with Terminology for Kpop Fandom
Jul 10, 2024



While machines learn from existing corpora, humans have the unique capability to establish and accept new language systems. This makes human form unique language systems within social groups. Aligning with this, we focus on a gap remaining in addressing translation challenges within social groups, where in-group members utilize unique terminologies. We propose KpopMT dataset, which aims to fill this gap by enabling precise terminology translation, choosing Kpop fandom as an initiative for social groups given its global popularity. Expert translators provide 1k English translations for Korean posts and comments, each annotated with specific terminology within social groups' language systems. We evaluate existing translation systems including GPT models on KpopMT to identify their failure cases. Results show overall low scores, underscoring the challenges of reflecting group-specific terminologies and styles in translation. We make KpopMT publicly available.
MentalAgora: A Gateway to Advanced Personalized Care in Mental Health through Multi-Agent Debating and Attribute Control
Jul 03, 2024As mental health issues globally escalate, there is a tremendous need for advanced digital support systems. We introduce MentalAgora, a novel framework employing large language models enhanced by interaction between multiple agents for tailored mental health support. This framework operates through three stages: strategic debating, tailored counselor creation, and response generation, enabling the dynamic customization of responses based on individual user preferences and therapeutic needs. We conduct experiments utilizing a high-quality evaluation dataset TherapyTalk crafted with mental health professionals, shwoing that MentalAgora generates expert-aligned and user preference-enhanced responses. Our evaluations, including experiments and user studies, demonstrate that MentalAgora aligns with professional standards and effectively meets user preferences, setting a new benchmark for digital mental health interventions.
PEMA: Plug-in External Memory Adaptation for Language Models
Nov 14, 2023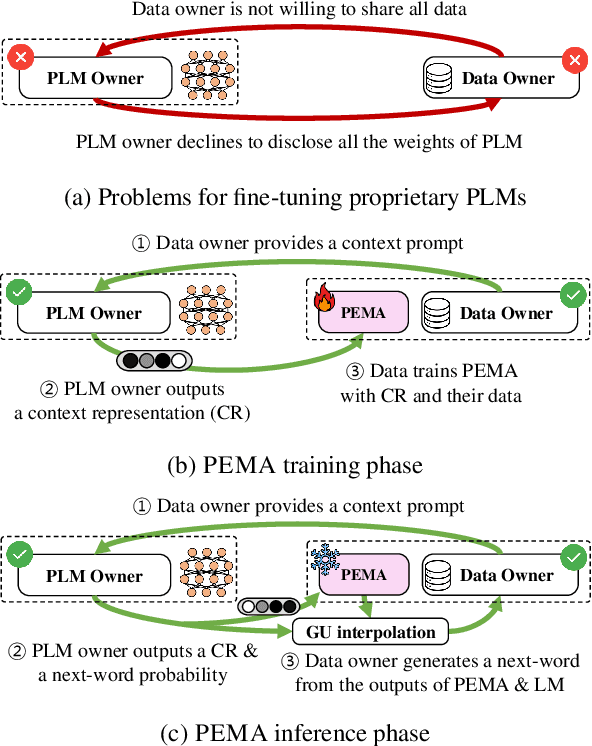
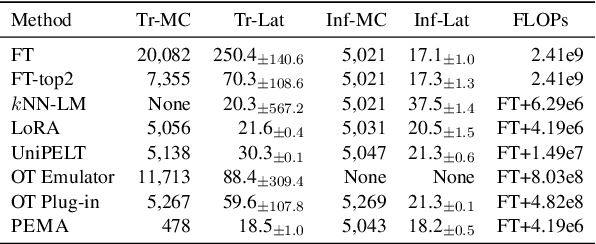
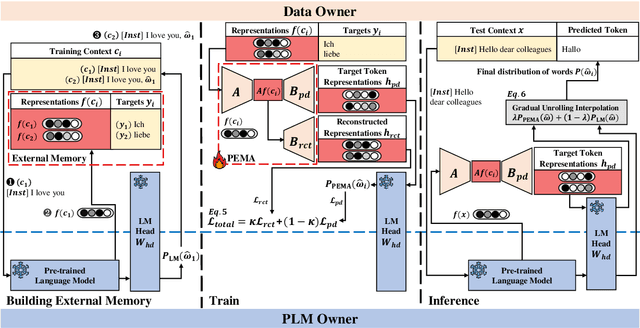
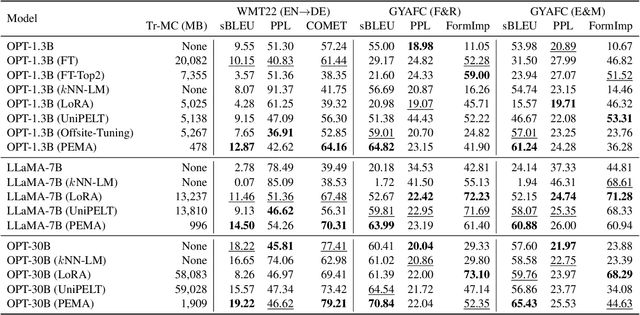
Pre-trained language models (PLMs) have demonstrated impressive performance across various downstream NLP tasks. Nevertheless, the resource requirements of pre-training large language models in terms of memory and training compute pose significant challenges. Furthermore, due to the substantial resources required, many PLM weights are confidential. Consequently, users are compelled to share their data with model owners for fine-tuning on specific tasks. To overcome the limitations, we introduce Plug-in External Memory Adaptation (PEMA), a Parameter-Efficient Fine-Tuning (PEFT) approach designed for fine-tuning PLMs without the need for all weights. PEMA can be integrated into the context representation of test data during inference to execute downstream tasks. It leverages an external memory to store context representations generated by a PLM, mapped with the desired target word. Our method entails training LoRA-based weight matrices within the final layer of the PLM for enhanced efficiency. The probability is then interpolated with the next-word distribution from the PLM to perform downstream tasks. To improve the generation quality, we propose a novel interpolation strategy named Gradual Unrolling. To demonstrate the effectiveness of our proposed method, we conduct experiments to demonstrate the efficacy of PEMA with a syntactic dataset and assess its performance on machine translation and style transfer tasks using real datasets. PEMA outperforms other PEFT methods in terms of memory and latency efficiency for training and inference. Furthermore, it outperforms other baselines in preserving the meaning of sentences while generating appropriate language and styles.