 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEMA: Plug-in External Memory Adaptation for Language Models
Paper and Code
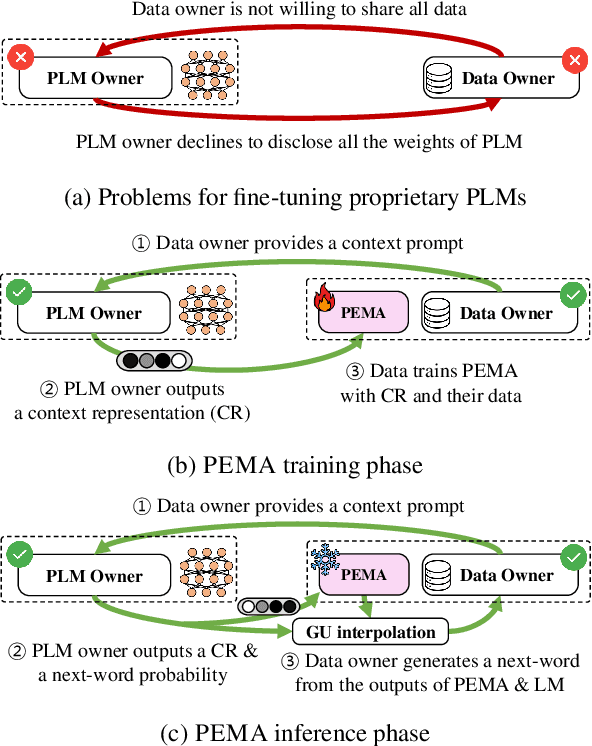
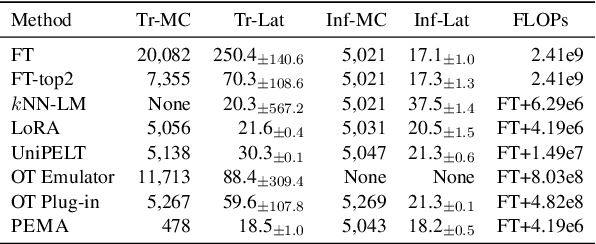
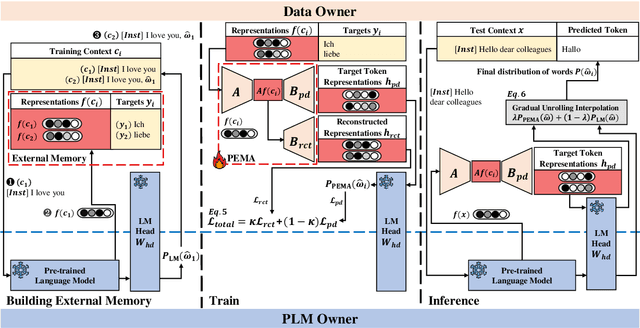
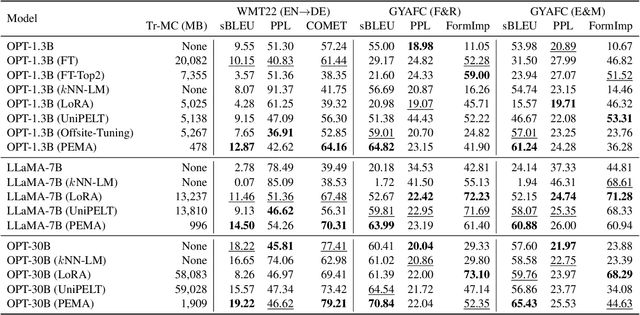
Pre-trained language models (PLMs) have demonstrated impressive performance across various downstream NLP tasks. Nevertheless, the resource requirements of pre-training large language models in terms of memory and training compute pose significant challenges. Furthermore, due to the substantial resources required, many PLM weights are confidential. Consequently, users are compelled to share their data with model owners for fine-tuning on specific tasks. To overcome the limitations, we introduce Plug-in External Memory Adaptation (PEMA), a Parameter-Efficient Fine-Tuning (PEFT) approach designed for fine-tuning PLMs without the need for all weights. PEMA can be integrated into the context representation of test data during inference to execute downstream tasks. It leverages an external memory to store context representations generated by a PLM, mapped with the desired target word. Our method entails training LoRA-based weight matrices within the final layer of the PLM for enhanced efficiency. The probability is then interpolated with the next-word distribution from the PLM to perform downstream tasks. To improve the generation quality, we propose a novel interpolation strategy named Gradual Unrolling. To demonstrate the effectiveness of our proposed method, we conduct experiments to demonstrate the efficacy of PEMA with a syntactic dataset and assess its performance on machine translation and style transfer tasks using real datasets. PEMA outperforms other PEFT methods in terms of memory and latency efficiency for training and inference. Furthermore, it outperforms other baselines in preserving the meaning of sentences while generating appropriate language and styles.