 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Appropriateness That Accounts for Norms of Rationality
Mar 14, 2026We propose a society-first theory of normative appropriateness where individuals, modeled as pre-trained actors with cognitive architectures analogous to Large Language Models (LLMs), generate behavior via predictive pattern completion. Our theory posits that individuals act by completing distributed symbolic patterns based on context, answering questions such as "What does a person such as I do in a situation such as this?". This sense-making mechanism provides a parsimonious account of the key features of human norms: their context-dependence, arbitrariness, automaticity, dynamism, and their support from social sanctioning. It challenges rational-choice theories of social norms by accounting for their key features without needing to exogenously posit scalar rewards or preference relations. By distinguishing between explicit norms, which we associate with in-context adaptation, and implicit norms, which we associate with long-term memory, the theory reconceptualizes several foundational ideas in cognitive science. In particular, it gives an alternative account to the data traditionally seen as supporting dual-process models, and it flips the role of rationality, allowing us to construe it as adherence to culturally-contingent justification standards.
Beyond Turn-taking: Introducing Text-based Overlap into Human-LLM Interactions
Jan 30, 2025



Traditional text-based human-AI interactions often adhere to a strict turn-taking approach. In this research, we propose a novel approach that incorporates overlapping messages, mirroring natural human conversations. Through a formative study, we observed that even in text-based contexts, users instinctively engage in overlapping behaviors like "A: Today I went to-" "B: yeah." To capitalize on these insights, we developed OverlapBot, a prototype chatbot where both AI and users can initiate overlapping. Our user study revealed that OverlapBot was perceived as more communicative and immersive than traditional turn-taking chatbot, fostering faster and more natural interactions. Our findings contribute to the understanding of design space for overlapping interactions. We also provide recommendations for implementing overlap-capable AI interactions to enhance the fluidity and engagement of text-based conversations.
Assessing Graphical Perception of Image Embedding Models using Channel Effectiveness
Jul 30, 2024
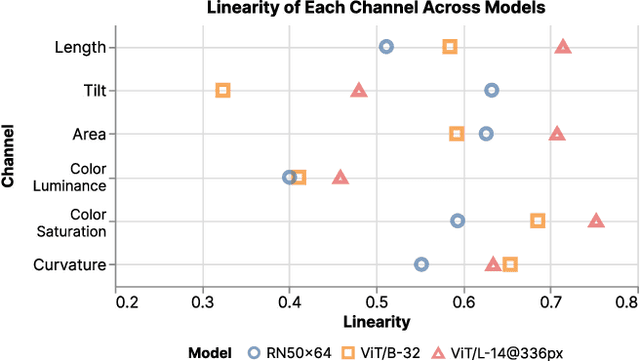


Recent advancements in vision models have greatly improved their ability to handle complex chart understanding tasks, like chart captioning and question answering. However, it remains challenging to assess how these models process charts. Existing benchmarks only roughly evaluate model performance without evaluating the underlying mechanisms, such as how models extract image embeddings. This limits our understanding of the model's ability to perceive fundamental graphical components. To address this, we introduce a novel evaluation framework to assess the graphical perception of image embedding models. For chart comprehension, we examine two main aspects of channel effectiveness: accuracy and discriminability of various visual channels. Channel accuracy is assessed through the linearity of embeddings, measuring how well the perceived magnitude aligns with the size of the stimulus. Discriminability is evaluated based on the distances between embeddings, indicating their distinctness. Our experiments with the CLIP model show that it perceives channel accuracy differently from humans and shows unique discriminability in channels like length, tilt, and curvature. We aim to develop this work into a broader benchmark for reliable visual encoders, enhancing models for precise chart comprehension and human-like perception in future applications.
Beyond Thumbs Up/Down: Untangling Challenges of Fine-Grained Feedback for Text-to-Image Generation
Jun 24, 2024Human feedback plays a critical role in learning and refining reward models for text-to-image generation, but the optimal form the feedback should take for learning an accurate reward function has not been conclusively established. This paper investigates the effectiveness of fine-grained feedback which captures nuanced distinctions in image quality and prompt-alignment, compared to traditional coarse-grained feedback (for example, thumbs up/down or ranking between a set of options). While fine-grained feedback holds promise, particularly for systems catering to diverse societal preferences, we show that demonstrating its superiority to coarse-grained feedback is not automatic. Through experiments on real and synthetic preference data, we surface the complexities of building effective models due to the interplay of model choice, feedback type, and the alignment between human judgment and computational interpretation. We identify key challenges in eliciting and utilizing fine-grained feedback, prompting a reassessment of its assumed benefits and practicality. Our findings -- e.g., that fine-grained feedback can lead to worse models for a fixed budget, in some settings; however, in controlled settings with known attributes, fine grained rewards can indeed be more helpful -- call for careful consideration of feedback attributes and potentially beckon novel modeling approaches to appropriately unlock the potential value of fine-grained feedback in-the-wild.
Designing for Human-Agent Alignment: Understanding what humans want from their agents
Apr 04, 2024Our ability to build autonomous agents that leverage Generative AI continues to increase by the day. As builders and users of such agents it is unclear what parameters we need to align on before the agents start performing tasks on our behalf. To discover these parameters, we ran a qualitative empirical research study about designing agents that can negotiate during a fictional yet relatable task of selling a camera online. We found that for an agent to perform the task successfully, humans/users and agents need to align over 6 dimensions: 1) Knowledge Schema Alignment 2) Autonomy and Agency Alignment 3) Operational Alignment and Training 4) Reputational Heuristics Alignment 5) Ethics Alignment and 6) Human Engagement Alignment. These empirical findings expand previous work related to process and specification alignment and the need for values and safety in Human-AI interactions. Subsequently we discuss three design directions for designers who are imagining a world filled with Human-Agent collaborations.
Extracting Human Attention through Crowdsourced Patch Labeling
Mar 22, 2024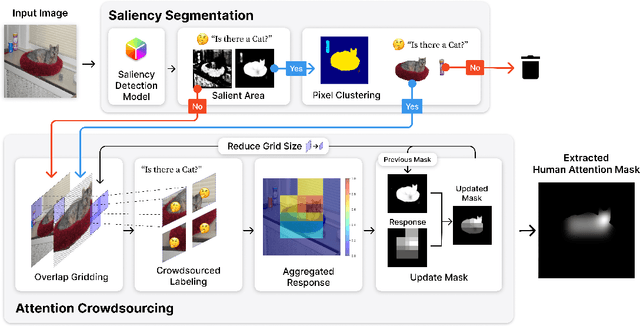


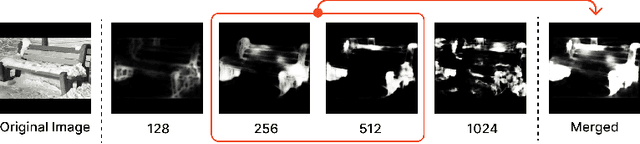
In image classification, a significant problem arises from bias in the datasets. When it contains only specific types of images, the classifier begins to rely on shortcuts - simplistic and erroneous rules for decision-making. This leads to high performance on the training dataset but inferior results on new, varied images, as the classifier's generalization capability is reduced. For example, if the images labeled as mustache consist solely of male figures, the model may inadvertently learn to classify images by gender rather than the presence of a mustache. One approach to mitigate such biases is to direct the model's attention toward the target object's location, usually marked using bounding boxes or polygons for annotation. However, collecting such annotations requires substantial time and human effort. Therefore, we propose a novel patch-labeling method that integrates AI assistance with crowdsourcing to capture human attention from images, which can be a viable solution for mitigating bias. Our method consists of two steps. First, we extract the approximate location of a target using a pre-trained saliency detection model supplemented by human verification for accuracy. Then, we determine the human-attentive area in the image by iteratively dividing the image into smaller patches and employing crowdsourcing to ascertain whether each patch can be classified as the target object. We demonstrated the effectiveness of our method in mitigating bias through improved classification accuracy and the refined focus of the model. Also, crowdsourced experiments validate that our method collects human annotation up to 3.4 times faster than annotating object locations with polygons, significantly reducing the need for human resources. We conclude the paper by discussing the advantages of our method in a crowdsourcing context, mainly focusing on aspects of human errors and accessibility.
LLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models
Feb 16, 2024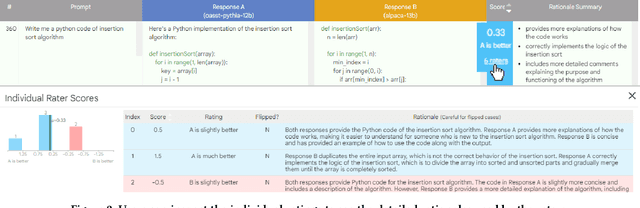

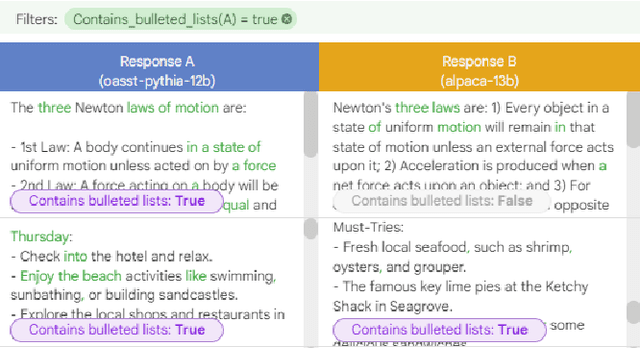
Automatic side-by-side evaluation has emerged as a promising approach to evaluating the quality of responses from large language models (LLMs). However, analyzing the results from this evaluation approach raises scalability and interpretability challenges. In this paper, we present LLM Comparator, a novel visual analytics tool for interactively analyzing results from automatic side-by-side evaluation. The tool supports interactive workflows for users to understand when and why a model performs better or worse than a baseline model, and how the responses from two models are qualitatively different. We iteratively designed and developed the tool by closely working with researchers and engineers at a large technology company. This paper details the user challenges we identified, the design and development of the tool, and an observational study with participants who regularly evaluate their models.
Bootstrap Your Own Skills: Learning to Solve New Tasks with Large Language Model Guidance
Oct 17, 2023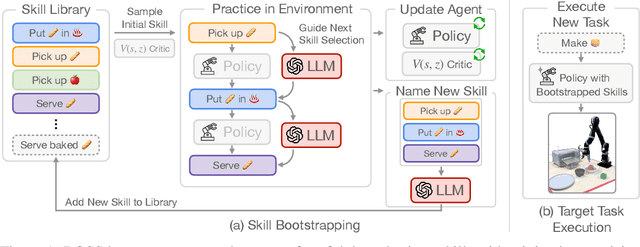
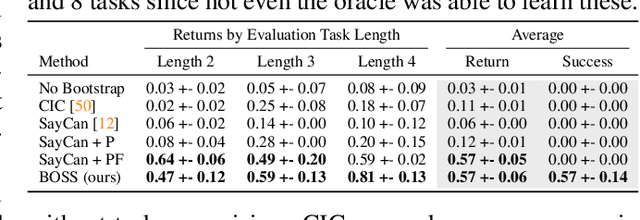
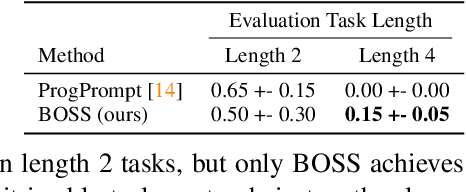
We propose BOSS, an approach that automatically learns to solve new long-horizon, complex, and meaningful tasks by growing a learned skill library with minimal supervision. Prior work in reinforcement learning require expert supervision, in the form of demonstrations or rich reward functions, to learn long-horizon tasks. Instead, our approach BOSS (BOotStrapping your own Skills) learns to accomplish new tasks by performing "skill bootstrapping," where an agent with a set of primitive skills interacts with the environment to practice new skills without receiving reward feedback for tasks outside of the initial skill set. This bootstrapping phase is guided by large language models (LLMs) that inform the agent of meaningful skills to chain together. Through this process, BOSS builds a wide range of complex and useful behaviors from a basic set of primitive skills. We demonstrate through experiments in realistic household environments that agents trained with our LLM-guided bootstrapping procedure outperform those trained with naive bootstrapping as well as prior unsupervised skill acquisition methods on zero-shot execution of unseen, long-horizon tasks in new environments. Website at clvrai.com/boss.
CLARA: Classifying and Disambiguating User Commands for Reliable Interactive Robotic Agents
Jun 22, 2023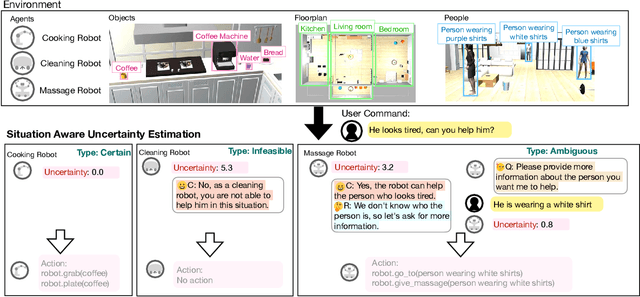
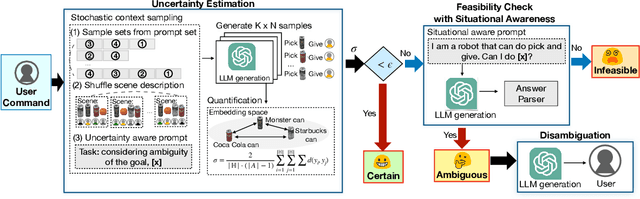
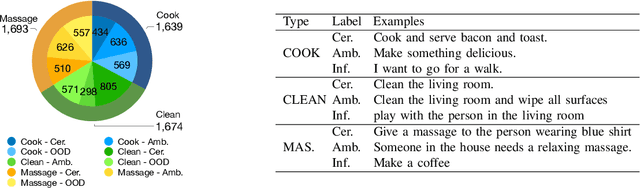
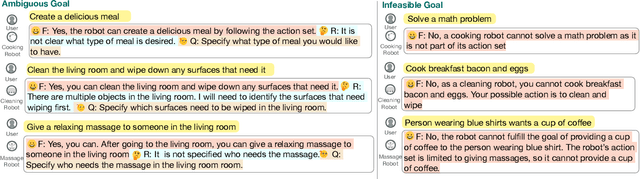
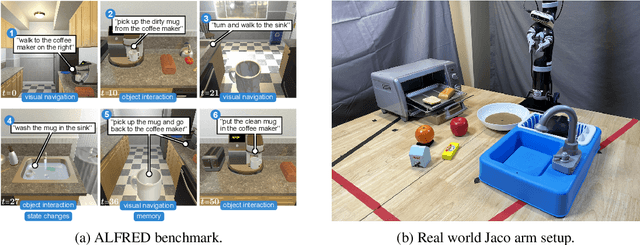
In this paper, we focus on inferring whether the given user command is clear, ambiguous, or infeasible in the context of interactive robotic agents utilizing large language models (LLMs). To tackle this problem, we first present an uncertainty estimation method for LLMs to classify whether the command is certain (i.e., clear) or not (i.e., ambiguous or infeasible). Once the command is classified as uncertain, we further distinguish it between ambiguous or infeasible commands leveraging LLMs with situational aware context in a zero-shot manner. For ambiguous commands, we disambiguate the command by interacting with users via question generation with LLMs. We believe that proper recognition of the given commands could lead to a decrease in malfunction and undesired actions of the robot, enhancing the reliability of interactive robot agents. We present a dataset for robotic situational awareness, consisting pair of high-level commands, scene descriptions, and labels of command type (i.e., clear, ambiguous, or infeasible). We validate the proposed method on the collected dataset, pick-and-place tabletop simulation. Finally, we demonstrate the proposed approach in real-world human-robot interaction experiments, i.e., handover scenarios.
Neglected Free Lunch; Learning Image Classifiers Using Annotation Byproducts
Apr 04, 2023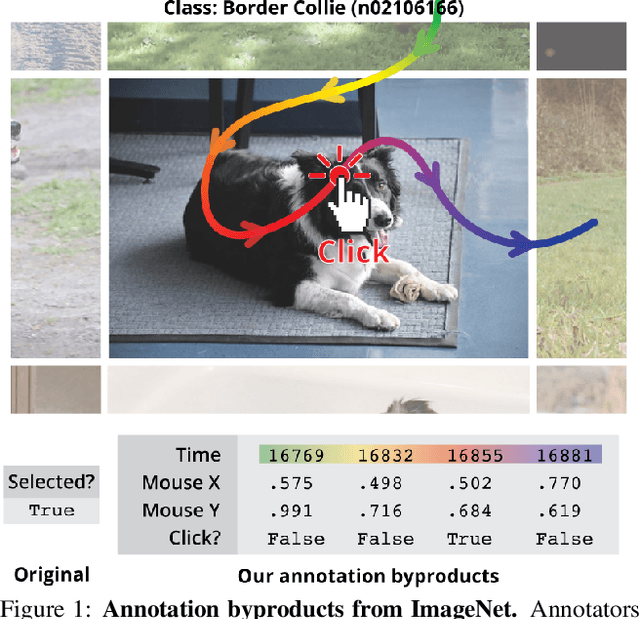

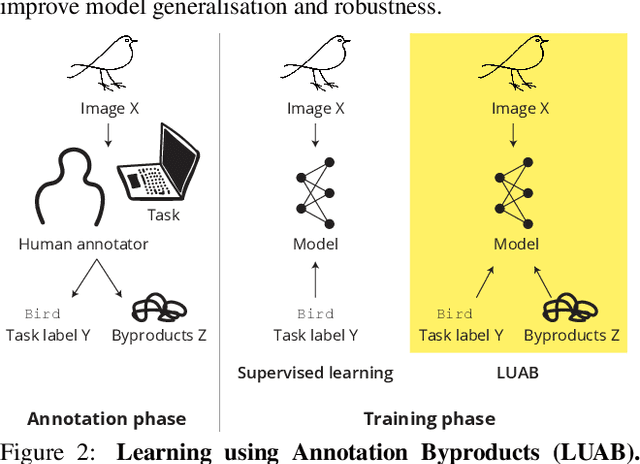

Supervised learning of image classifiers distills human knowledge into a parametric model through pairs of images and corresponding labels (X,Y). We argue that this simple and widely used representation of human knowledge neglects rich auxiliary information from the annotation procedure, such as the time-series of mouse traces and clicks left after image selection. Our insight is that such annotation byproducts Z provide approximate human attention that weakly guides the model to focus on the foreground cues, reducing spurious correlations and discouraging shortcut learning. To verify this, we create ImageNet-AB and COCO-AB. They are ImageNet and COCO training sets enriched with sample-wise annotation byproducts, collected by replicating the respective original annotation tasks. We refer to the new paradigm of training models with annotation byproducts as learning using annotation byproducts (LUAB). We show that a simple multitask loss for regressing Z together with Y already improves the generalisability and robustness of the learned models. Compared to the original supervised learning, LUAB does not require extra annotation costs. ImageNet-AB and COCO-AB are at https://github.com/naver-ai/NeglectedFreeLunch.