 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Validity of Clustering Validation Datasets
Mar 03, 2025



Clustering techniques are often validated using benchmark datasets where class labels are used as ground-truth clusters. However, depending on the datasets, class labels may not align with the actual data clusters, and such misalignment hampers accurate validation. Therefore, it is essential to evaluate and compare datasets regarding their cluster-label matching (CLM), i.e., how well their class labels match actual clusters. Internal validation measures (IVMs), like Silhouette, can compare CLM over different labeling of the same dataset, but are not designed to do so across different datasets. We thus introduce Adjusted IVMs as fast and reliable methods to evaluate and compare CLM across datasets. We establish four axioms that require validation measures to be independent of data properties not related to cluster structure (e.g., dimensionality, dataset size). Then, we develop standardized protocols to convert any IVM to satisfy these axioms, and use these protocols to adjust six widely used IVMs. Quantitative experiments (1) verify the necessity and effectiveness of our protocols and (2) show that adjusted IVMs outperform the competitors, including standard IVMs, in accurately evaluating CLM both within and across datasets. We also show that the datasets can be filtered or improved using our method to form more reliable benchmarks for clustering validation.
Extracting Human Attention through Crowdsourced Patch Labeling
Mar 22, 2024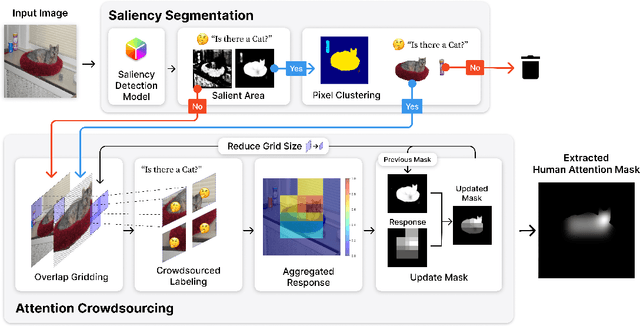


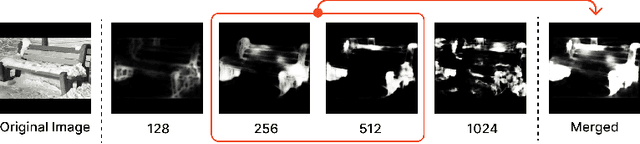
In image classification, a significant problem arises from bias in the datasets. When it contains only specific types of images, the classifier begins to rely on shortcuts - simplistic and erroneous rules for decision-making. This leads to high performance on the training dataset but inferior results on new, varied images, as the classifier's generalization capability is reduced. For example, if the images labeled as mustache consist solely of male figures, the model may inadvertently learn to classify images by gender rather than the presence of a mustache. One approach to mitigate such biases is to direct the model's attention toward the target object's location, usually marked using bounding boxes or polygons for annotation. However, collecting such annotations requires substantial time and human effort. Therefore, we propose a novel patch-labeling method that integrates AI assistance with crowdsourcing to capture human attention from images, which can be a viable solution for mitigating bias. Our method consists of two steps. First, we extract the approximate location of a target using a pre-trained saliency detection model supplemented by human verification for accuracy. Then, we determine the human-attentive area in the image by iteratively dividing the image into smaller patches and employing crowdsourcing to ascertain whether each patch can be classified as the target object. We demonstrated the effectiveness of our method in mitigating bias through improved classification accuracy and the refined focus of the model. Also, crowdsourced experiments validate that our method collects human annotation up to 3.4 times faster than annotating object locations with polygons, significantly reducing the need for human resources. We conclude the paper by discussing the advantages of our method in a crowdsourcing context, mainly focusing on aspects of human errors and accessibility.
ZADU: A Python Library for Evaluating the Reliability of Dimensionality Reduction Embeddings
Aug 11, 2023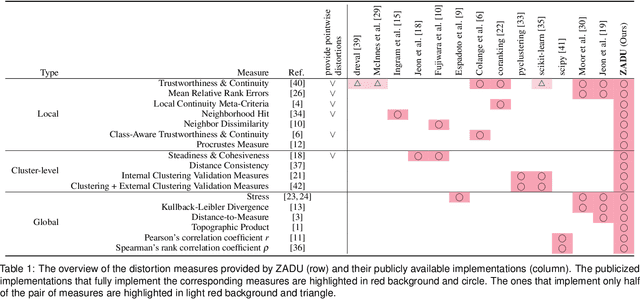

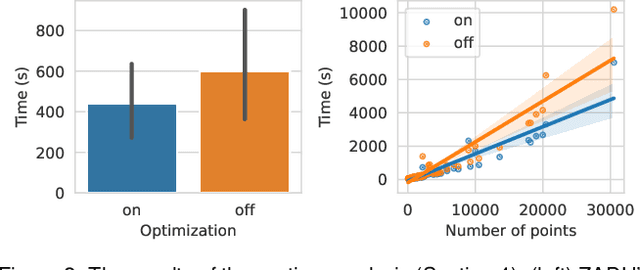
Dimensionality reduction (DR) techniques inherently distort the original structure of input high-dimensional data, producing imperfect low-dimensional embeddings. Diverse distortion measures have thus been proposed to evaluate the reliability of DR embeddings. However, implementing and executing distortion measures in practice has so far been time-consuming and tedious. To address this issue, we present ZADU, a Python library that provides distortion measures. ZADU is not only easy to install and execute but also enables comprehensive evaluation of DR embeddings through three key features. First, the library covers a wide range of distortion measures. Second, it automatically optimizes the execution of distortion measures, substantially reducing the running time required to execute multiple measures. Last, the library informs how individual points contribute to the overall distortions, facilitating the detailed analysis of DR embeddings. By simulating a real-world scenario of optimizing DR embeddings, we verify that our optimization scheme substantially reduces the time required to execute distortion measures. Finally, as an application of ZADU, we present another library called ZADUVis that allows users to easily create distortion visualizations that depict the extent to which each region of an embedding suffers from distortions.
Sanity Check for External Clustering Validation Benchmarks using Internal Validation Measures
Sep 20, 2022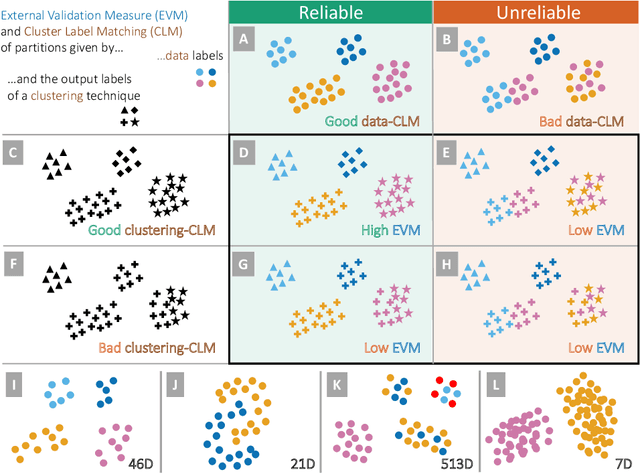
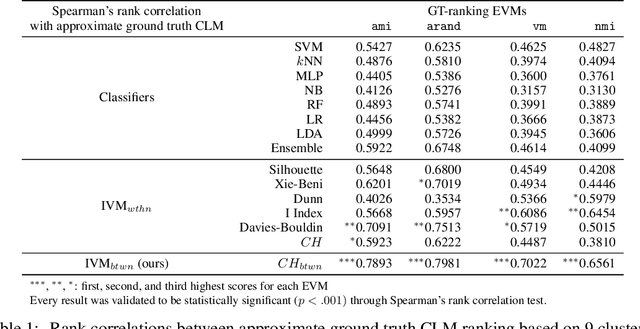
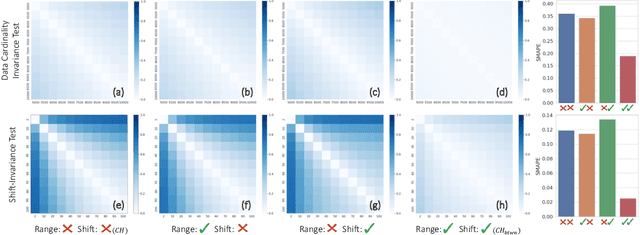
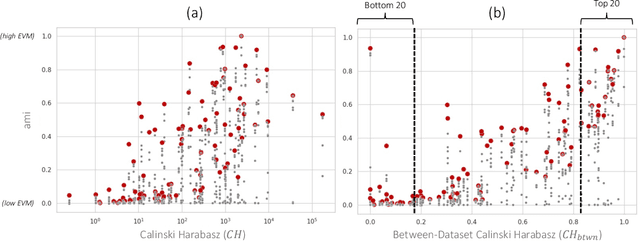
We address the lack of reliability in benchmarking clustering techniques based on labeled datasets. A standard scheme in external clustering validation is to use class labels as ground truth clusters, based on the assumption that each class forms a single, clearly separated cluster. However, as such cluster-label matching (CLM) assumption often breaks, the lack of conducting a sanity check for the CLM of benchmark datasets casts doubt on the validity of external validations. Still, evaluating the degree of CLM is challenging. For example, internal clustering validation measures can be used to quantify CLM within the same dataset to evaluate its different clusterings but are not designed to compare clusterings of different datasets. In this work, we propose a principled way to generate between-dataset internal measures that enable the comparison of CLM across datasets. We first determine four axioms for between-dataset internal measures, complementing Ackerman and Ben-David's within-dataset axioms. We then propose processes to generalize internal measures to fulfill these new axioms, and use them to extend the widely used Calinski-Harabasz index for between-dataset CLM evaluation. Through quantitative experiments, we (1) verify the validity and necessity of the generalization processes and (2) show that the proposed between-dataset Calinski-Harabasz index accurately evaluates CLM across datasets. Finally, we demonstrate the importance of evaluating CLM of benchmark datasets before conducting external validation.