 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Human Attention through Crowdsourced Patch Labeling
Paper and Code
Mar 22, 2024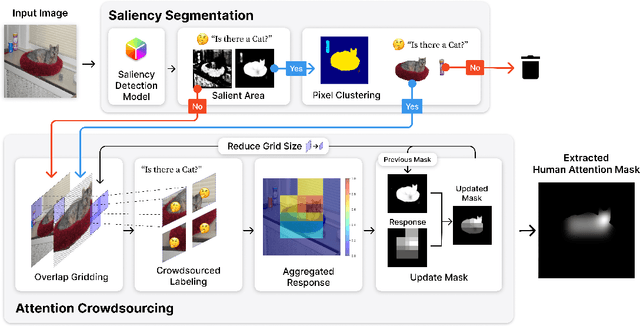


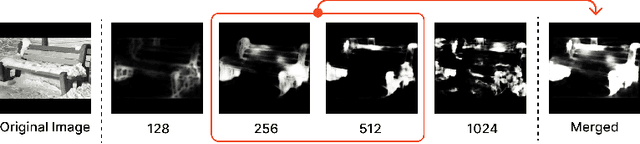
In image classification, a significant problem arises from bias in the datasets. When it contains only specific types of images, the classifier begins to rely on shortcuts - simplistic and erroneous rules for decision-making. This leads to high performance on the training dataset but inferior results on new, varied images, as the classifier's generalization capability is reduced. For example, if the images labeled as mustache consist solely of male figures, the model may inadvertently learn to classify images by gender rather than the presence of a mustache. One approach to mitigate such biases is to direct the model's attention toward the target object's location, usually marked using bounding boxes or polygons for annotation. However, collecting such annotations requires substantial time and human effort. Therefore, we propose a novel patch-labeling method that integrates AI assistance with crowdsourcing to capture human attention from images, which can be a viable solution for mitigating bias. Our method consists of two steps. First, we extract the approximate location of a target using a pre-trained saliency detection model supplemented by human verification for accuracy. Then, we determine the human-attentive area in the image by iteratively dividing the image into smaller patches and employing crowdsourcing to ascertain whether each patch can be classified as the target object. We demonstrated the effectiveness of our method in mitigating bias through improved classification accuracy and the refined focus of the model. Also, crowdsourced experiments validate that our method collects human annotation up to 3.4 times faster than annotating object locations with polygons, significantly reducing the need for human resources. We conclude the paper by discussing the advantages of our method in a crowdsourcing context, mainly focusing on aspects of human errors and accessibility.