 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhostUI: Unveiling Hidden Interactions in Mobile UI
Jan 27, 2026Modern mobile applications rely on hidden interactions--gestures without visual cues like long presses and swipes--to provide functionality without cluttering interfaces. While experienced users may discover these interactions through prior use or onboarding tutorials, their implicit nature makes them difficult for most users to uncover. Similarly, mobile agents--systems designed to automate tasks on mobile user interfaces, powered by vision language models (VLMs)--struggle to detect veiled interactions or determine actions for completing tasks. To address this challenge, we present GhostUI, a new dataset designed to enable the detection of hidden interactions in mobile applications. GhostUI provides before-and-after screenshots, simplified view hierarchies, gesture metadata, and task descriptions, allowing VLMs to better recognize concealed gestures and anticipate post-interaction states. Quantitative evaluations with VLMs show that models fine-tuned on GhostUI outperform baseline VLMs, particularly in predicting hidden interactions and inferring post-interaction screens, underscoring GhostUI's potential as a foundation for advancing mobile task automation.
Bridging Gulfs in UI Generation through Semantic Guidance
Jan 27, 2026While generative AI enables high-fidelity UI generation from text prompts, users struggle to articulate design intent and evaluate or refine results-creating gulfs of execution and evaluation. To understand the information needed for UI generation, we conducted a thematic analysis of UI prompting guidelines, identifying key design semantics and discovering that they are hierarchical and interdependent. Leveraging these findings, we developed a system that enables users to specify semantics, visualize relationships, and extract how semantics are reflected in generated UIs. By making semantics serve as an intermediate representation between human intent and AI output, our system bridges both gulfs by making requirements explicit and outcomes interpretable. A comparative user study suggests that our approach enhances users' perceived control over intent expression, outcome interpretation, and facilitates more predictable, iterative refinement. Our work demonstrates how explicit semantic representation enables systematic and explainable exploration of design possibilities in AI-driven UI design.
InFerActive: Towards Scalable Human Evaluation of Large Language Models through Interactive Inference
Dec 11, 2025Human evaluation remains the gold standard for evaluating outputs of Large Language Models (LLMs). The current evaluation paradigm reviews numerous individual responses, leading to significant scalability challenges. LLM outputs can be more efficiently represented as a tree structure, reflecting their autoregressive generation process and stochastic token selection. However, conventional tree visualization cannot scale to the exponentially large trees generated by modern sampling methods of LLMs. To address this problem, we present InFerActive, an interactive inference system for scalable human evaluation. InFerActive enables on-demand exploration through probability-based filtering and evaluation features, while bridging the semantic gap between computational tokens and human-readable text through adaptive visualization techniques. Through a technical evaluation and user study (N=12), we demonstrate that InFerActive significantly improves evaluation efficiency and enables more comprehensive assessment of model behavior. We further conduct expert case studies that demonstrate InFerActive's practical applicability and potential for transforming LLM evaluation workflows.
Understanding Bias in Perceiving Dimensionality Reduction Projections
Jul 28, 2025Selecting the dimensionality reduction technique that faithfully represents the structure is essential for reliable visual communication and analytics. In reality, however, practitioners favor projections for other attractions, such as aesthetics and visual saliency, over the projection's structural faithfulness, a bias we define as visual interestingness. In this research, we conduct a user study that (1) verifies the existence of such bias and (2) explains why the bias exists. Our study suggests that visual interestingness biases practitioners' preferences when selecting projections for analysis, and this bias intensifies with color-encoded labels and shorter exposure time. Based on our findings, we discuss strategies to mitigate bias in perceiving and interpreting DR projections.
Dataset-Adaptive Dimensionality Reduction
Jul 16, 2025
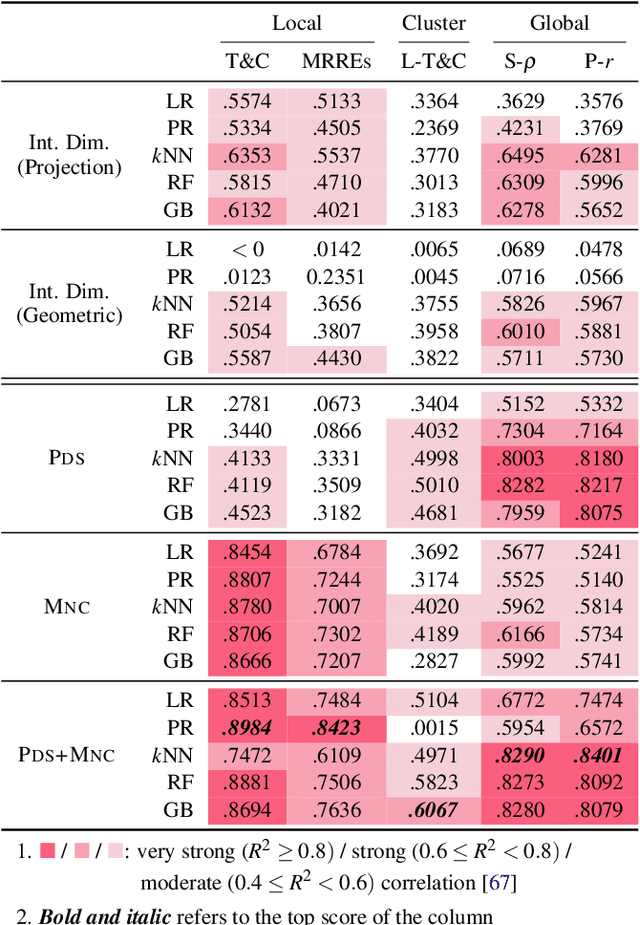


Selecting the appropriate dimensionality reduction (DR) technique and determining its optimal hyperparameter settings that maximize the accuracy of the output projections typically involves extensive trial and error, often resulting in unnecessary computational overhead. To address this challenge, we propose a dataset-adaptive approach to DR optimization guided by structural complexity metrics. These metrics quantify the intrinsic complexity of a dataset, predicting whether higher-dimensional spaces are necessary to represent it accurately. Since complex datasets are often inaccurately represented in two-dimensional projections, leveraging these metrics enables us to predict the maximum achievable accuracy of DR techniques for a given dataset, eliminating redundant trials in optimizing DR. We introduce the design and theoretical foundations of these structural complexity metrics. We quantitatively verify that our metrics effectively approximate the ground truth complexity of datasets and confirm their suitability for guiding dataset-adaptive DR workflow. Finally, we empirically show that our dataset-adaptive workflow significantly enhances the efficiency of DR optimization without compromising accuracy.
Metric Design != Metric Behavior: Improving Metric Selection for the Unbiased Evaluation of Dimensionality Reduction
Jul 03, 2025Evaluating the accuracy of dimensionality reduction (DR) projections in preserving the structure of high-dimensional data is crucial for reliable visual analytics. Diverse evaluation metrics targeting different structural characteristics have thus been developed. However, evaluations of DR projections can become biased if highly correlated metrics--those measuring similar structural characteristics--are inadvertently selected, favoring DR techniques that emphasize those characteristics. To address this issue, we propose a novel workflow that reduces bias in the selection of evaluation metrics by clustering metrics based on their empirical correlations rather than on their intended design characteristics alone. Our workflow works by computing metric similarity using pairwise correlations, clustering metrics to minimize overlap, and selecting a representative metric from each cluster. Quantitative experiments demonstrate that our approach improves the stability of DR evaluation, which indicates that our workflow contributes to mitigating evaluation bias.
Stop Misusing t-SNE and UMAP for Visual Analytics
Jun 10, 2025



Misuses of t-SNE and UMAP in visual analytics have become increasingly common. For example, although t-SNE and UMAP projections often do not faithfully reflect true distances between clusters, practitioners frequently use them to investigate inter-cluster relationships. In this paper, we bring this issue to the surface and comprehensively investigate why such misuse occurs and how to prevent it. We conduct a literature review of 114 papers to verify the prevalence of the misuse and analyze the reasonings behind it. We then execute an interview study to uncover practitioners' implicit motivations for using these techniques -- rationales often undisclosed in the literature. Our findings indicate that misuse of t-SNE and UMAP primarily stems from limited discourse on their appropriate use in visual analytics. We conclude by proposing future directions and concrete action items to promote more reasonable use of DR.
MedOrchestra: A Hybrid Cloud-Local LLM Approach for Clinical Data Interpretation
May 27, 2025Deploying large language models (LLMs) in clinical settings faces critical trade-offs: cloud LLMs, with their extensive parameters and superior performance, pose risks to sensitive clinical data privacy, while local LLMs preserve privacy but often fail at complex clinical interpretation tasks. We propose MedOrchestra, a hybrid framework where a cloud LLM decomposes complex clinical tasks into manageable subtasks and prompt generation, while a local LLM executes these subtasks in a privacy-preserving manner. Without accessing clinical data, the cloud LLM generates and validates subtask prompts using clinical guidelines and synthetic test cases. The local LLM executes subtasks locally and synthesizes outputs generated by the cloud LLM. We evaluate MedOrchestra on pancreatic cancer staging using 100 radiology reports under NCCN guidelines. On free-text reports, MedOrchestra achieves 70.21% accuracy, outperforming local model baselines (without guideline: 48.94%, with guideline: 56.59%) and board-certified clinicians (gastroenterologists: 59.57%, surgeons: 65.96%, radiologists: 55.32%). On structured reports, MedOrchestra reaches 85.42% accuracy, showing clear superiority across all settings.
Measuring the Validity of Clustering Validation Datasets
Mar 03, 2025



Clustering techniques are often validated using benchmark datasets where class labels are used as ground-truth clusters. However, depending on the datasets, class labels may not align with the actual data clusters, and such misalignment hampers accurate validation. Therefore, it is essential to evaluate and compare datasets regarding their cluster-label matching (CLM), i.e., how well their class labels match actual clusters. Internal validation measures (IVMs), like Silhouette, can compare CLM over different labeling of the same dataset, but are not designed to do so across different datasets. We thus introduce Adjusted IVMs as fast and reliable methods to evaluate and compare CLM across datasets. We establish four axioms that require validation measures to be independent of data properties not related to cluster structure (e.g., dimensionality, dataset size). Then, we develop standardized protocols to convert any IVM to satisfy these axioms, and use these protocols to adjust six widely used IVMs. Quantitative experiments (1) verify the necessity and effectiveness of our protocols and (2) show that adjusted IVMs outperform the competitors, including standard IVMs, in accurately evaluating CLM both within and across datasets. We also show that the datasets can be filtered or improved using our method to form more reliable benchmarks for clustering validation.
Leveraging Multimodal LLM for Inspirational User Interface Search
Jan 30, 2025
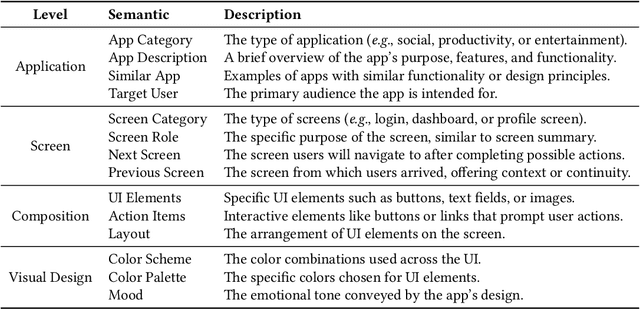

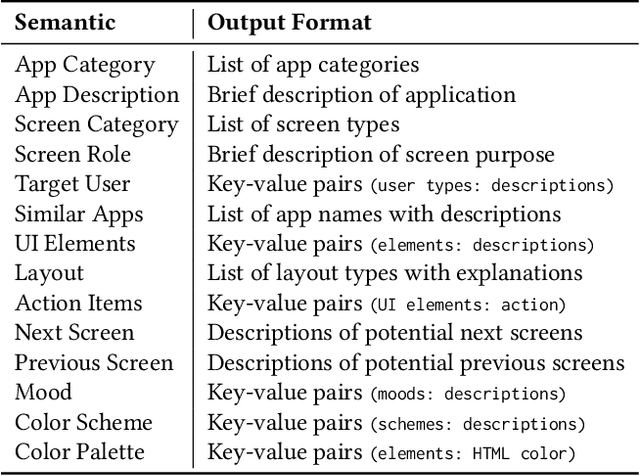
Inspirational search, the process of exploring designs to inform and inspire new creative work, is pivotal in mobile user interface (UI) design. However, exploring the vast space of UI references remains a challenge. Existing AI-based UI search methods often miss crucial semantics like target users or the mood of apps. Additionally, these models typically require metadata like view hierarchies, limiting their practical use. We used a multimodal large language model (MLLM) to extract and interpret semantics from mobile UI images. We identified key UI semantics through a formative study and developed a semantic-based UI search system. Through computational and human evaluations, we demonstrate that our approach significantly outperforms existing UI retrieval methods, offering UI designers a more enriched and contextually relevant search experience. We enhance the understanding of mobile UI design semantics and highlight MLLMs' potential in inspirational search, providing a rich dataset of UI semantics for future studies.