 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedOrchestra: A Hybrid Cloud-Local LLM Approach for Clinical Data Interpretation
May 27, 2025Deploying large language models (LLMs) in clinical settings faces critical trade-offs: cloud LLMs, with their extensive parameters and superior performance, pose risks to sensitive clinical data privacy, while local LLMs preserve privacy but often fail at complex clinical interpretation tasks. We propose MedOrchestra, a hybrid framework where a cloud LLM decomposes complex clinical tasks into manageable subtasks and prompt generation, while a local LLM executes these subtasks in a privacy-preserving manner. Without accessing clinical data, the cloud LLM generates and validates subtask prompts using clinical guidelines and synthetic test cases. The local LLM executes subtasks locally and synthesizes outputs generated by the cloud LLM. We evaluate MedOrchestra on pancreatic cancer staging using 100 radiology reports under NCCN guidelines. On free-text reports, MedOrchestra achieves 70.21% accuracy, outperforming local model baselines (without guideline: 48.94%, with guideline: 56.59%) and board-certified clinicians (gastroenterologists: 59.57%, surgeons: 65.96%, radiologists: 55.32%). On structured reports, MedOrchestra reaches 85.42% accuracy, showing clear superiority across all settings.
PhenoFlow: A Human-LLM Driven Visual Analytics System for Exploring Large and Complex Stroke Datasets
Jul 23, 2024

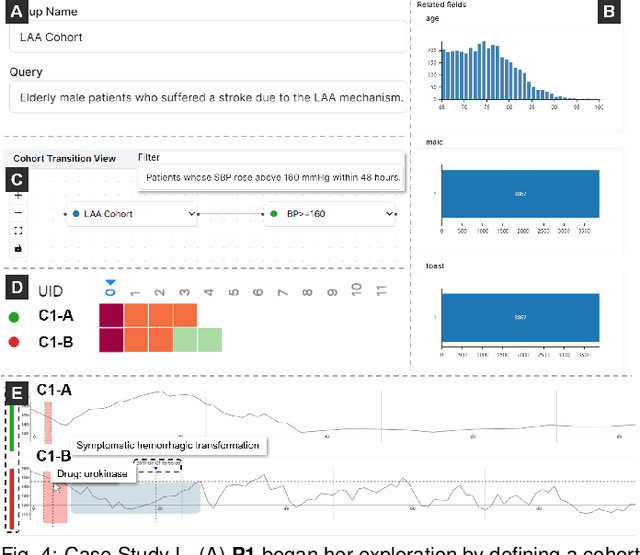
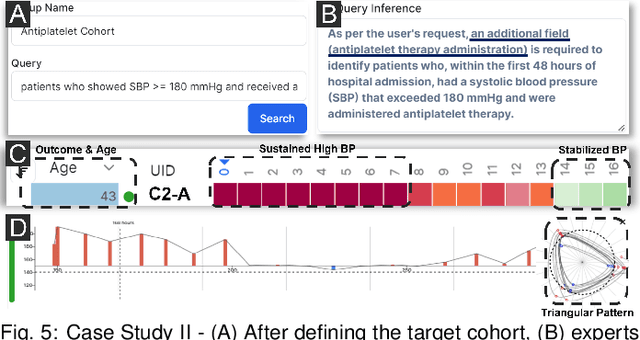
Acute stroke demands prompt diagnosis and treatment to achieve optimal patient outcomes. However, the intricate and irregular nature of clinical data associated with acute stroke, particularly blood pressure (BP) measurements, presents substantial obstacles to effective visual analytics and decision-making. Through a year-long collaboration with experienced neurologists, we developed PhenoFlow, a visual analytics system that leverages the collaboration between human and Large Language Models (LLMs) to analyze the extensive and complex data of acute ischemic stroke patients. PhenoFlow pioneers an innovative workflow, where the LLM serves as a data wrangler while neurologists explore and supervise the output using visualizations and natural language interactions. This approach enables neurologists to focus more on decision-making with reduced cognitive load. To protect sensitive patient information, PhenoFlow only utilizes metadata to make inferences and synthesize executable codes, without accessing raw patient data. This ensures that the results are both reproducible and interpretable while maintaining patient privacy. The system incorporates a slice-and-wrap design that employs temporal folding to create an overlaid circular visualization. Combined with a linear bar graph, this design aids in exploring meaningful patterns within irregularly measured BP data. Through case studies, PhenoFlow has demonstrated its capability to support iterative analysis of extensive clinical datasets, reducing cognitive load and enabling neurologists to make well-informed decisions. Grounded in long-term collaboration with domain experts, our research demonstrates the potential of utilizing LLMs to tackle current challenges in data-driven clinical decision-making for acute ischemic stroke patients.
Interactive Visualization for Exploring Information Fragments in Software Repositories
Apr 28, 2021Software developers explore and inspect software repository data to obtain detailed information archived in the development history. However, developers who are not acquainted with the development context suffer from delving into the repositories with a handful of information; they have difficulty discovering and expanding information fragments considering the topological and sequential multi-dimensional structure of repositories. We introduce ExIF, an interactive visualization for exploring information fragments in software repositories. ExIF helps users discover new information fragments within clusters or topological neighbors and identify revisions incorporating user-collected fragments.