 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Gulfs in UI Generation through Semantic Guidance
Jan 27, 2026While generative AI enables high-fidelity UI generation from text prompts, users struggle to articulate design intent and evaluate or refine results-creating gulfs of execution and evaluation. To understand the information needed for UI generation, we conducted a thematic analysis of UI prompting guidelines, identifying key design semantics and discovering that they are hierarchical and interdependent. Leveraging these findings, we developed a system that enables users to specify semantics, visualize relationships, and extract how semantics are reflected in generated UIs. By making semantics serve as an intermediate representation between human intent and AI output, our system bridges both gulfs by making requirements explicit and outcomes interpretable. A comparative user study suggests that our approach enhances users' perceived control over intent expression, outcome interpretation, and facilitates more predictable, iterative refinement. Our work demonstrates how explicit semantic representation enables systematic and explainable exploration of design possibilities in AI-driven UI design.
Generating Animated Layouts as Structured Text Representations
May 02, 2025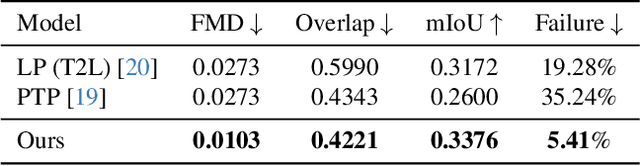
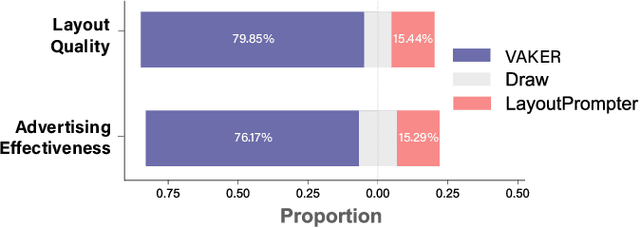
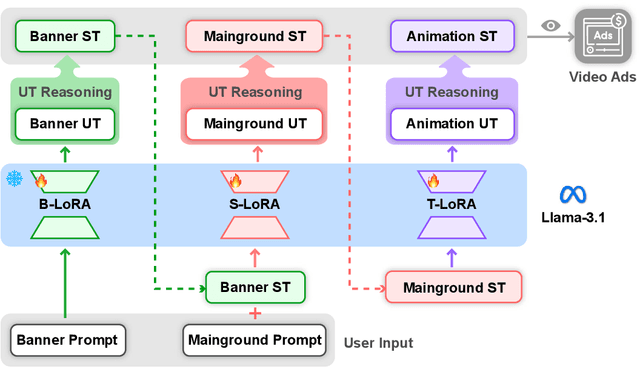
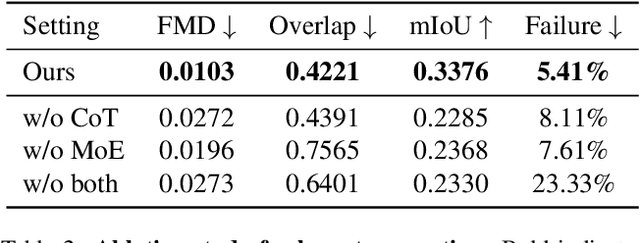
Despite the remarkable progress in text-to-video models, achieving precise control over text elements and animated graphics remains a significant challenge, especially in applications such as video advertisements. To address this limitation, we introduce Animated Layout Generation, a novel approach to extend static graphic layouts with temporal dynamics. We propose a Structured Text Representation for fine-grained video control through hierarchical visual elements. To demonstrate the effectiveness of our approach, we present VAKER (Video Ad maKER), a text-to-video advertisement generation pipeline that combines a three-stage generation process with Unstructured Text Reasoning for seamless integration with LLMs. VAKER fully automates video advertisement generation by incorporating dynamic layout trajectories for objects and graphics across specific video frames. Through extensive evaluations, we demonstrate that VAKER significantly outperforms existing methods in generating video advertisements. Project Page: https://yeonsangshin.github.io/projects/Vaker
Leveraging Multimodal LLM for Inspirational User Interface Search
Jan 30, 2025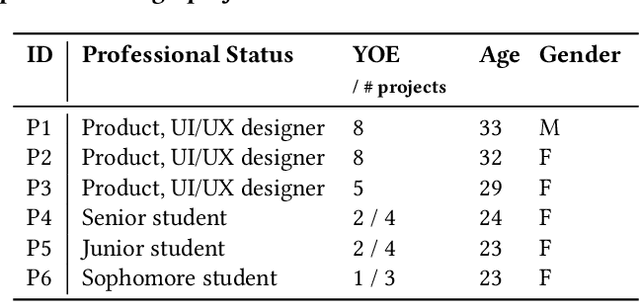
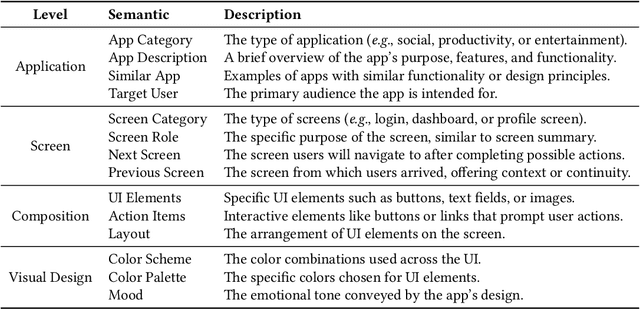

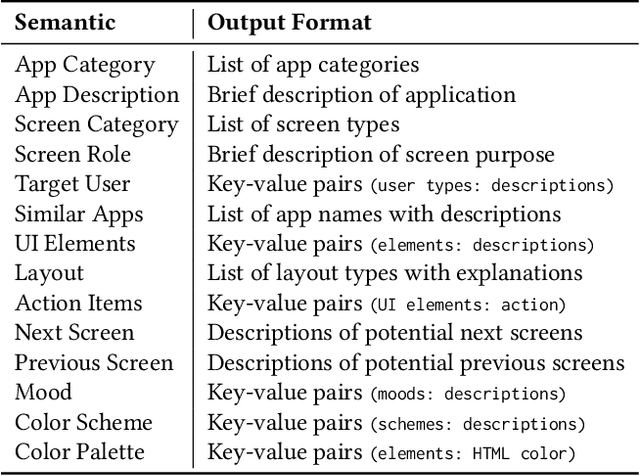
Inspirational search, the process of exploring designs to inform and inspire new creative work, is pivotal in mobile user interface (UI) design. However, exploring the vast space of UI references remains a challenge. Existing AI-based UI search methods often miss crucial semantics like target users or the mood of apps. Additionally, these models typically require metadata like view hierarchies, limiting their practical use. We used a multimodal large language model (MLLM) to extract and interpret semantics from mobile UI images. We identified key UI semantics through a formative study and developed a semantic-based UI search system. Through computational and human evaluations, we demonstrate that our approach significantly outperforms existing UI retrieval methods, offering UI designers a more enriched and contextually relevant search experience. We enhance the understanding of mobile UI design semantics and highlight MLLMs' potential in inspirational search, providing a rich dataset of UI semantics for future studies.