 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Gulfs in UI Generation through Semantic Guidance
Jan 27, 2026While generative AI enables high-fidelity UI generation from text prompts, users struggle to articulate design intent and evaluate or refine results-creating gulfs of execution and evaluation. To understand the information needed for UI generation, we conducted a thematic analysis of UI prompting guidelines, identifying key design semantics and discovering that they are hierarchical and interdependent. Leveraging these findings, we developed a system that enables users to specify semantics, visualize relationships, and extract how semantics are reflected in generated UIs. By making semantics serve as an intermediate representation between human intent and AI output, our system bridges both gulfs by making requirements explicit and outcomes interpretable. A comparative user study suggests that our approach enhances users' perceived control over intent expression, outcome interpretation, and facilitates more predictable, iterative refinement. Our work demonstrates how explicit semantic representation enables systematic and explainable exploration of design possibilities in AI-driven UI design.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
ELITE: Enhanced Language-Image Toxicity Evaluation for Safety
Feb 10, 2025



Current Vision Language Models (VLMs) remain vulnerable to malicious prompts that induce harmful outputs. Existing safety benchmarks for VLMs primarily rely on automated evaluation methods, but these methods struggle to detect implicit harmful content or produce inaccurate evaluations. Therefore, we found that existing benchmarks have low levels of harmfulness, ambiguous data, and limited diversity in image-text pair combinations. To address these issues, we propose the ELITE benchmark, a high-quality safety evaluation benchmark for VLMs, underpinned by our enhanced evaluation method, the ELITE evaluator. The ELITE evaluator explicitly incorporates a toxicity score to accurately assess harmfulness in multimodal contexts, where VLMs often provide specific, convincing, but unharmful descriptions of images. We filter out ambiguous and low-quality image-text pairs from existing benchmarks using the ELITE evaluator and generate diverse combinations of safe and unsafe image-text pairs. Our experiments demonstrate that the ELITE evaluator achieves superior alignment with human evaluations compared to prior automated methods, and the ELITE benchmark offers enhanced benchmark quality and diversity. By introducing ELITE, we pave the way for safer, more robust VLMs, contributing essential tools for evaluating and mitigating safety risks in real-world applications.
An In-Depth Analysis of Adversarial Discriminative Domain Adaptation for Digit Classification
Dec 27, 2024
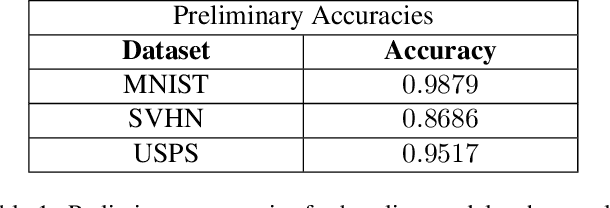

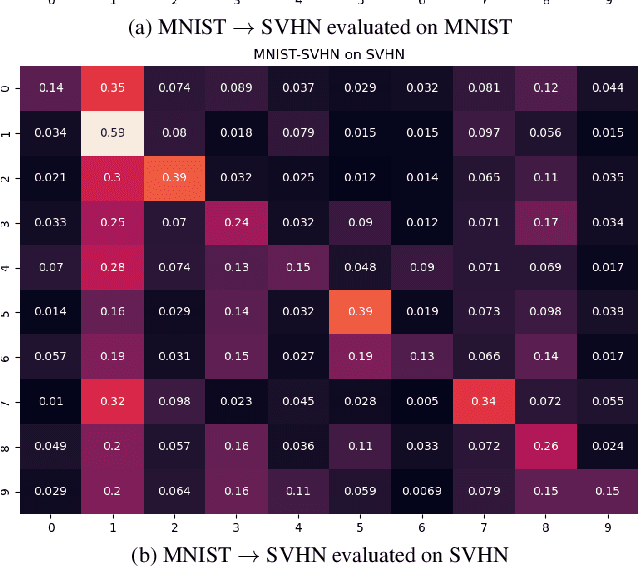
Domain adaptation is an active area of research driven by the growing demand for robust machine learning models that perform well on real-world data. Adversarial learning for deep neural networks (DNNs) has emerged as a promising approach to improving generalization ability, particularly for image classification. In this paper, we implement a specific adversarial learning technique known as Adversarial Discriminative Domain Adaptation (ADDA) and replicate digit classification experiments from the original ADDA paper. We extend their findings by examining a broader range of domain shifts and provide a detailed analysis of in-domain classification accuracy post-ADDA. Our results demonstrate that ADDA significantly improves accuracy across certain domain shifts with minimal impact on in-domain performance. Furthermore, we provide qualitative analysis and propose potential explanations for ADDA's limitations in less successful domain shifts. Code is at https://github.com/eugenechoi2004/COS429_FINAL .
Averaging log-likelihoods in direct alignment
Jun 27, 2024



To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.
Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
Jun 27, 2024Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
Self-Improving Robust Preference Optimization
Jun 03, 2024


Both online and offline RLHF methods such as PPO and DPO have been extremely successful in aligning AI with human preferences. Despite their success, the existing methods suffer from a fundamental problem that their optimal solution is highly task-dependent (i.e., not robust to out-of-distribution (OOD) tasks). Here we address this challenge by proposing Self-Improving Robust Preference Optimization SRPO, a practical and mathematically principled offline RLHF framework that is completely robust to the changes in the task. The key idea of SRPO is to cast the problem of learning from human preferences as a self-improvement process, which can be mathematically expressed in terms of a min-max objective that aims at joint optimization of self-improvement policy and the generative policy in an adversarial fashion. The solution for this optimization problem is independent of the training task and thus it is robust to its changes. We then show that this objective can be re-expressed in the form of a non-adversarial offline loss which can be optimized using standard supervised optimization techniques at scale without any need for reward model and online inference. We show the effectiveness of SRPO in terms of AI Win-Rate (WR) against human (GOLD) completions. In particular, when SRPO is evaluated on the OOD XSUM dataset, it outperforms the celebrated DPO by a clear margin of 15% after 5 self-revisions, achieving WR of 90%.
Machine Learning Regularization for the Minimum Volume Formula of Toric Calabi-Yau 3-folds
Oct 30, 2023



We present a collection of explicit formulas for the minimum volume of Sasaki-Einstein 5-manifolds. The cone over these 5-manifolds is a toric Calabi-Yau 3-fold. These toric Calabi-Yau 3-folds are associated with an infinite class of 4d N=1 supersymmetric gauge theories, which are realized as worldvolume theories of D3-branes probing the toric Calabi-Yau 3-folds. Under the AdS/CFT correspondence, the minimum volume of the Sasaki-Einstein base is inversely proportional to the central charge of the corresponding 4d N=1 superconformal field theories. The presented formulas for the minimum volume are in terms of geometric invariants of the toric Calabi-Yau 3-folds. These explicit results are derived by implementing machine learning regularization techniques that advance beyond previous applications of machine learning for determining the minimum volume. Moreover, the use of machine learning regularization allows us to present interpretable and explainable formulas for the minimum volume. Our work confirms that, even for extensive sets of toric Calabi-Yau 3-folds, the proposed formulas approximate the minimum volume with remarkable accuracy.
A Non-monotonic Self-terminating Language Model
Oct 03, 2022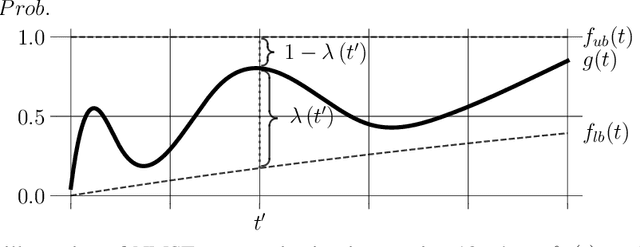
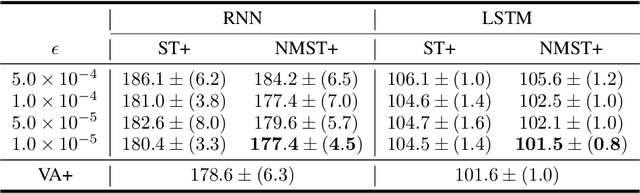
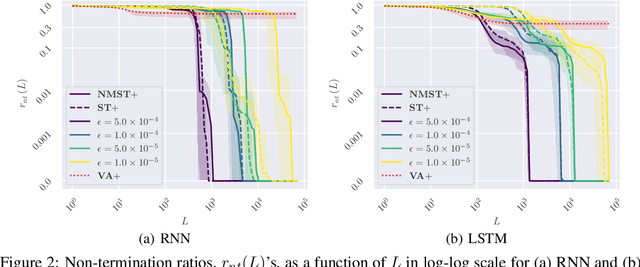
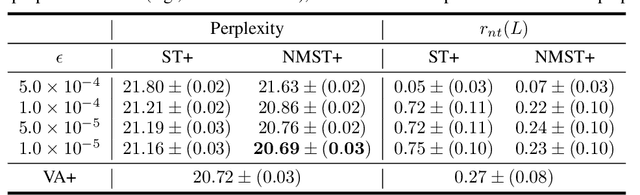
Recent large-scale neural autoregressive sequence models have shown impressive performances on a variety of natural language generation tasks. However, their generated sequences often exhibit degenerate properties such as non-termination, undesirable repetition, and premature termination, when generated with decoding algorithms such as greedy search, beam search, top-$k$ sampling, and nucleus sampling. In this paper, we focus on the problem of non-terminating sequences resulting from an incomplete decoding algorithm. We first define an incomplete probable decoding algorithm which includes greedy search, top-$k$ sampling, and nucleus sampling, beyond the incomplete decoding algorithm originally put forward by Welleck et al. (2020). We then propose a non-monotonic self-terminating language model, which significantly relaxes the constraint of monotonically increasing termination probability in the originally proposed self-terminating language model by Welleck et al. (2020), to address the issue of non-terminating sequences when using incomplete probable decoding algorithms. We prove that our proposed model prevents non-terminating sequences when using not only incomplete probable decoding algorithms but also beam search. We empirically validate our model on sequence completion tasks with various architectures.