 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowTAS: Progressive Expansion from Small to Large Subnets for Efficient ViT Architecture Search
Dec 13, 2025Transformer architecture search (TAS) aims to automatically discover efficient vision transformers (ViTs), reducing the need for manual design. Existing TAS methods typically train an over-parameterized network (i.e., a supernet) that encompasses all candidate architectures (i.e., subnets). However, all subnets share the same set of weights, which leads to interference that degrades the smaller subnets severely. We have found that well-trained small subnets can serve as a good foundation for training larger ones. Motivated by this, we propose a progressive training framework, dubbed GrowTAS, that begins with training small subnets and incorporate larger ones gradually. This enables reducing the interference and stabilizing a training process. We also introduce GrowTAS+ that fine-tunes a subset of weights only to further enhance the performance of large subnets. Extensive experiments on ImageNet and several transfer learning benchmarks, including CIFAR-10/100, Flowers, CARS, and INAT-19, demonstrate the effectiveness of our approach over current TAS methods
AccuQuant: Simulating Multiple Denoising Steps for Quantizing Diffusion Models
Oct 23, 2025We present in this paper a novel post-training quantization (PTQ) method, dubbed AccuQuant, for diffusion models. We show analytically and empirically that quantization errors for diffusion models are accumulated over denoising steps in a sampling process. To alleviate the error accumulation problem, AccuQuant minimizes the discrepancies between outputs of a full-precision diffusion model and its quantized version within a couple of denoising steps. That is, it simulates multiple denoising steps of a diffusion sampling process explicitly for quantization, accounting the accumulated errors over multiple denoising steps, which is in contrast to previous approaches to imitating a training process of diffusion models, namely, minimizing the discrepancies independently for each step. We also present an efficient implementation technique for AccuQuant, together with a novel objective, which reduces a memory complexity significantly from $\mathcal{O}(n)$ to $\mathcal{O}(1)$, where $n$ is the number of denoising steps. We demonstrate the efficacy and efficiency of AccuQuant across various tasks and diffusion models on standard benchmarks.
Jailbreaking on Text-to-Video Models via Scene Splitting Strategy
Sep 26, 2025Along with the rapid advancement of numerous Text-to-Video (T2V) models, growing concerns have emerged regarding their safety risks. While recent studies have explored vulnerabilities in models like LLMs, VLMs, and Text-to-Image (T2I) models through jailbreak attacks, T2V models remain largely unexplored, leaving a significant safety gap. To address this gap, we introduce SceneSplit, a novel black-box jailbreak method that works by fragmenting a harmful narrative into multiple scenes, each individually benign. This approach manipulates the generative output space, the abstract set of all potential video outputs for a given prompt, using the combination of scenes as a powerful constraint to guide the final outcome. While each scene individually corresponds to a wide and safe space where most outcomes are benign, their sequential combination collectively restricts this space, narrowing it to an unsafe region and significantly increasing the likelihood of generating a harmful video. This core mechanism is further enhanced through iterative scene manipulation, which bypasses the safety filter within this constrained unsafe region. Additionally, a strategy library that reuses successful attack patterns further improves the attack's overall effectiveness and robustness. To validate our method, we evaluate SceneSplit across 11 safety categories on T2V models. Our results show that it achieves a high average Attack Success Rate (ASR) of 77.2% on Luma Ray2, 84.1% on Hailuo, and 78.2% on Veo2, significantly outperforming the existing baseline. Through this work, we demonstrate that current T2V safety mechanisms are vulnerable to attacks that exploit narrative structure, providing new insights for understanding and improving the safety of T2V models.
Subnet-Aware Dynamic Supernet Training for Neural Architecture Search
Mar 13, 2025N-shot neural architecture search (NAS) exploits a supernet containing all candidate subnets for a given search space. The subnets are typically trained with a static training strategy (e.g., using the same learning rate (LR) scheduler and optimizer for all subnets). This, however, does not consider that individual subnets have distinct characteristics, leading to two problems: (1) The supernet training is biased towards the low-complexity subnets (unfairness); (2) the momentum update in the supernet is noisy (noisy momentum). We present a dynamic supernet training technique to address these problems by adjusting the training strategy adaptive to the subnets. Specifically, we introduce a complexity-aware LR scheduler (CaLR) that controls the decay ratio of LR adaptive to the complexities of subnets, which alleviates the unfairness problem. We also present a momentum separation technique (MS). It groups the subnets with similar structural characteristics and uses a separate momentum for each group, avoiding the noisy momentum problem. Our approach can be applicable to various N-shot NAS methods with marginal cost, while improving the search performance drastically. We validate the effectiveness of our approach on various search spaces (e.g., NAS-Bench-201, Mobilenet spaces) and datasets (e.g., CIFAR-10/100, ImageNet).
ELITE: Enhanced Language-Image Toxicity Evaluation for Safety
Feb 10, 2025Current Vision Language Models (VLMs) remain vulnerable to malicious prompts that induce harmful outputs. Existing safety benchmarks for VLMs primarily rely on automated evaluation methods, but these methods struggle to detect implicit harmful content or produce inaccurate evaluations. Therefore, we found that existing benchmarks have low levels of harmfulness, ambiguous data, and limited diversity in image-text pair combinations. To address these issues, we propose the ELITE benchmark, a high-quality safety evaluation benchmark for VLMs, underpinned by our enhanced evaluation method, the ELITE evaluator. The ELITE evaluator explicitly incorporates a toxicity score to accurately assess harmfulness in multimodal contexts, where VLMs often provide specific, convincing, but unharmful descriptions of images. We filter out ambiguous and low-quality image-text pairs from existing benchmarks using the ELITE evaluator and generate diverse combinations of safe and unsafe image-text pairs. Our experiments demonstrate that the ELITE evaluator achieves superior alignment with human evaluations compared to prior automated methods, and the ELITE benchmark offers enhanced benchmark quality and diversity. By introducing ELITE, we pave the way for safer, more robust VLMs, contributing essential tools for evaluating and mitigating safety risks in real-world applications.
Maximizing the Position Embedding for Vision Transformers with Global Average Pooling
Feb 05, 2025In vision transformers, position embedding (PE) plays a crucial role in capturing the order of tokens. However, in vision transformer structures, there is a limitation in the expressiveness of PE due to the structure where position embedding is simply added to the token embedding. A layer-wise method that delivers PE to each layer and applies independent Layer Normalizations for token embedding and PE has been adopted to overcome this limitation. In this paper, we identify the conflicting result that occurs in a layer-wise structure when using the global average pooling (GAP) method instead of the class token. To overcome this problem, we propose MPVG, which maximizes the effectiveness of PE in a layer-wise structure with GAP. Specifically, we identify that PE counterbalances token embedding values at each layer in a layer-wise structure. Furthermore, we recognize that the counterbalancing role of PE is insufficient in the layer-wise structure, and we address this by maximizing the effectiveness of PE through MPVG. Through experiments, we demonstrate that PE performs a counterbalancing role and that maintaining this counterbalancing directionality significantly impacts vision transformers. As a result, the experimental results show that MPVG outperforms existing methods across vision transformers on various tasks.
Efficient Few-Shot Neural Architecture Search by Counting the Number of Nonlinear Functions
Dec 19, 2024Neural architecture search (NAS) enables finding the best-performing architecture from a search space automatically. Most NAS methods exploit an over-parameterized network (i.e., a supernet) containing all possible architectures (i.e., subnets) in the search space. However, the subnets that share the same set of parameters are likely to have different characteristics, interfering with each other during training. To address this, few-shot NAS methods have been proposed that divide the space into a few subspaces and employ a separate supernet for each subspace to limit the extent of weight sharing. They achieve state-of-the-art performance, but the computational cost increases accordingly. We introduce in this paper a novel few-shot NAS method that exploits the number of nonlinear functions to split the search space. To be specific, our method divides the space such that each subspace consists of subnets with the same number of nonlinear functions. Our splitting criterion is efficient, since it does not require comparing gradients of a supernet to split the space. In addition, we have found that dividing the space allows us to reduce the channel dimensions required for each supernet, which enables training multiple supernets in an efficient manner. We also introduce a supernet-balanced sampling (SBS) technique, sampling several subnets at each training step, to train different supernets evenly within a limited number of training steps. Extensive experiments on standard NAS benchmarks demonstrate the effectiveness of our approach. Our code is available at https://cvlab.yonsei.ac.kr/projects/EFS-NAS.
Cerberus: Attribute-based person re-identification using semantic IDs
Dec 02, 2024We introduce a new framework, dubbed Cerberus, for attribute-based person re-identification (reID). Our approach leverages person attribute labels to learn local and global person representations that encode specific traits, such as gender and clothing style. To achieve this, we define semantic IDs (SIDs) by combining attribute labels, and use a semantic guidance loss to align the person representations with the prototypical features of corresponding SIDs, encouraging the representations to encode the relevant semantics. Simultaneously, we enforce the representations of the same person to be embedded closely, enabling recognizing subtle differences in appearance to discriminate persons sharing the same attribute labels. To increase the generalization ability on unseen data, we also propose a regularization method that takes advantage of the relationships between SID prototypes. Our framework performs individual comparisons of local and global person representations between query and gallery images for attribute-based reID. By exploiting the SID prototypes aligned with the corresponding representations, it can also perform person attribute recognition (PAR) and attribute-based person search (APS) without bells and whistles. Experimental results on standard benchmarks on attribute-based person reID, Market-1501 and DukeMTMC, demonstrate the superiority of our model compared to the state of the art.
Disentangled Representations for Short-Term and Long-Term Person Re-Identification
Sep 09, 2024
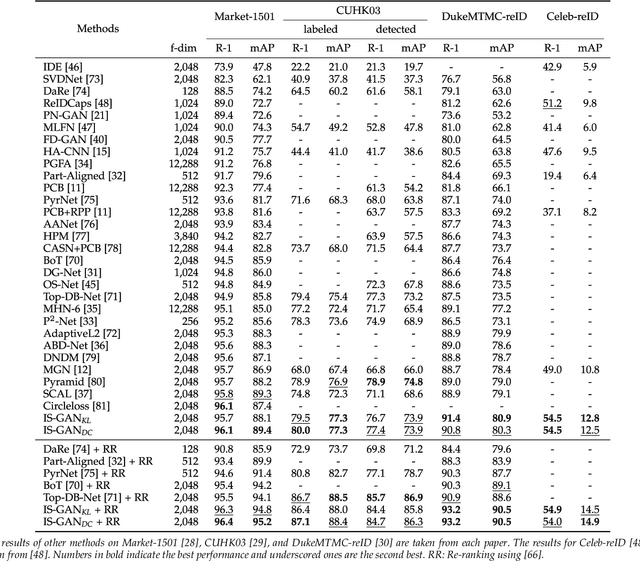

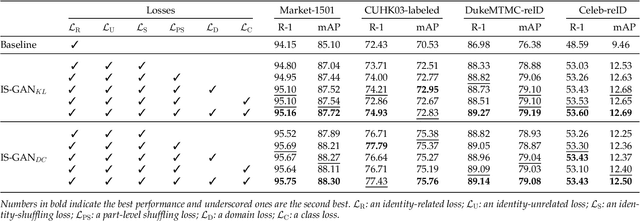
We address the problem of person re-identification (reID), that is, retrieving person images from a large dataset, given a query image of the person of interest. A key challenge is to learn person representations robust to intra-class variations, as different persons could have the same attribute, and persons' appearances look different, e.g., with viewpoint changes. Recent reID methods focus on learning person features discriminative only for a particular factor of variations (e.g., human pose), which also requires corresponding supervisory signals (e.g., pose annotations). To tackle this problem, we propose to factorize person images into identity-related and unrelated features. Identity-related features contain information useful for specifying a particular person (e.g., clothing), while identity-unrelated ones hold other factors (e.g., human pose). To this end, we propose a new generative adversarial network, dubbed identity shuffle GAN (IS-GAN). It disentangles identity-related and unrelated features from person images through an identity-shuffling technique that exploits identification labels alone without any auxiliary supervisory signals. We restrict the distribution of identity-unrelated features or encourage the identity-related and unrelated features to be uncorrelated, facilitating the disentanglement process. Experimental results validate the effectiveness of IS-GAN, showing state-of-the-art performance on standard reID benchmarks, including Market-1501, CUHK03, and DukeMTMC-reID. We further demonstrate the advantages of disentangling person representations on a long-term reID task, setting a new state of the art on a Celeb-reID dataset.
* arXiv admin note: substantial text overlap with arXiv:1910.12003
Toward INT4 Fixed-Point Training via Exploring Quantization Error for Gradients
Jul 17, 2024Network quantization generally converts full-precision weights and/or activations into low-bit fixed-point values in order to accelerate an inference process. Recent approaches to network quantization further discretize the gradients into low-bit fixed-point values, enabling an efficient training. They typically set a quantization interval using a min-max range of the gradients or adjust the interval such that the quantization error for entire gradients is minimized. In this paper, we analyze the quantization error of gradients for the low-bit fixed-point training, and show that lowering the error for large-magnitude gradients boosts the quantization performance significantly. Based on this, we derive an upper bound of quantization error for the large gradients in terms of the quantization interval, and obtain an optimal condition for the interval minimizing the quantization error for large gradients. We also introduce an interval update algorithm that adjusts the quantization interval adaptively to maintain a small quantization error for large gradients. Experimental results demonstrate the effectiveness of our quantization method for various combinations of network architectures and bit-widths on various tasks, including image classification, object detection, and super-resolution.