 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuQuant: Simulating Multiple Denoising Steps for Quantizing Diffusion Models
Oct 23, 2025We present in this paper a novel post-training quantization (PTQ) method, dubbed AccuQuant, for diffusion models. We show analytically and empirically that quantization errors for diffusion models are accumulated over denoising steps in a sampling process. To alleviate the error accumulation problem, AccuQuant minimizes the discrepancies between outputs of a full-precision diffusion model and its quantized version within a couple of denoising steps. That is, it simulates multiple denoising steps of a diffusion sampling process explicitly for quantization, accounting the accumulated errors over multiple denoising steps, which is in contrast to previous approaches to imitating a training process of diffusion models, namely, minimizing the discrepancies independently for each step. We also present an efficient implementation technique for AccuQuant, together with a novel objective, which reduces a memory complexity significantly from $\mathcal{O}(n)$ to $\mathcal{O}(1)$, where $n$ is the number of denoising steps. We demonstrate the efficacy and efficiency of AccuQuant across various tasks and diffusion models on standard benchmarks.
FYI: Flip Your Images for Dataset Distillation
Jul 11, 2024
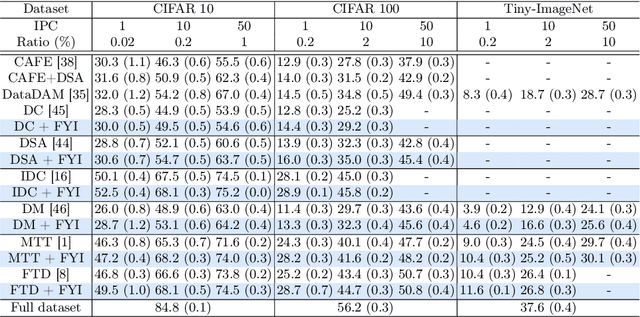


Dataset distillation synthesizes a small set of images from a large-scale real dataset such that synthetic and real images share similar behavioral properties (e.g, distributions of gradients or features) during a training process. Through extensive analyses on current methods and real datasets, together with empirical observations, we provide in this paper two important things to share for dataset distillation. First, object parts that appear on one side of a real image are highly likely to appear on the opposite side of another image within a dataset, which we call the bilateral equivalence. Second, the bilateral equivalence enforces synthetic images to duplicate discriminative parts of objects on both the left and right sides of the images, limiting the recognition of subtle differences between objects. To address this problem, we introduce a surprisingly simple yet effective technique for dataset distillation, dubbed FYI, that enables distilling rich semantics of real images into synthetic ones. To this end, FYI embeds a horizontal flipping technique into distillation processes, mitigating the influence of the bilateral equivalence, while capturing more details of objects. Experiments on CIFAR-10/100, Tiny-ImageNet, and ImageNet demonstrate that FYI can be seamlessly integrated into several state-of-the-art methods, without modifying training objectives and network architectures, and it improves the performance remarkably.