 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowTAS: Progressive Expansion from Small to Large Subnets for Efficient ViT Architecture Search
Dec 13, 2025Transformer architecture search (TAS) aims to automatically discover efficient vision transformers (ViTs), reducing the need for manual design. Existing TAS methods typically train an over-parameterized network (i.e., a supernet) that encompasses all candidate architectures (i.e., subnets). However, all subnets share the same set of weights, which leads to interference that degrades the smaller subnets severely. We have found that well-trained small subnets can serve as a good foundation for training larger ones. Motivated by this, we propose a progressive training framework, dubbed GrowTAS, that begins with training small subnets and incorporate larger ones gradually. This enables reducing the interference and stabilizing a training process. We also introduce GrowTAS+ that fine-tunes a subset of weights only to further enhance the performance of large subnets. Extensive experiments on ImageNet and several transfer learning benchmarks, including CIFAR-10/100, Flowers, CARS, and INAT-19, demonstrate the effectiveness of our approach over current TAS methods
Subnet-Aware Dynamic Supernet Training for Neural Architecture Search
Mar 13, 2025N-shot neural architecture search (NAS) exploits a supernet containing all candidate subnets for a given search space. The subnets are typically trained with a static training strategy (e.g., using the same learning rate (LR) scheduler and optimizer for all subnets). This, however, does not consider that individual subnets have distinct characteristics, leading to two problems: (1) The supernet training is biased towards the low-complexity subnets (unfairness); (2) the momentum update in the supernet is noisy (noisy momentum). We present a dynamic supernet training technique to address these problems by adjusting the training strategy adaptive to the subnets. Specifically, we introduce a complexity-aware LR scheduler (CaLR) that controls the decay ratio of LR adaptive to the complexities of subnets, which alleviates the unfairness problem. We also present a momentum separation technique (MS). It groups the subnets with similar structural characteristics and uses a separate momentum for each group, avoiding the noisy momentum problem. Our approach can be applicable to various N-shot NAS methods with marginal cost, while improving the search performance drastically. We validate the effectiveness of our approach on various search spaces (e.g., NAS-Bench-201, Mobilenet spaces) and datasets (e.g., CIFAR-10/100, ImageNet).
FYI: Flip Your Images for Dataset Distillation
Jul 11, 2024
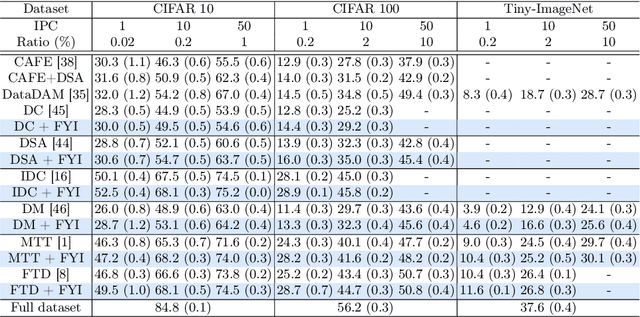


Dataset distillation synthesizes a small set of images from a large-scale real dataset such that synthetic and real images share similar behavioral properties (e.g, distributions of gradients or features) during a training process. Through extensive analyses on current methods and real datasets, together with empirical observations, we provide in this paper two important things to share for dataset distillation. First, object parts that appear on one side of a real image are highly likely to appear on the opposite side of another image within a dataset, which we call the bilateral equivalence. Second, the bilateral equivalence enforces synthetic images to duplicate discriminative parts of objects on both the left and right sides of the images, limiting the recognition of subtle differences between objects. To address this problem, we introduce a surprisingly simple yet effective technique for dataset distillation, dubbed FYI, that enables distilling rich semantics of real images into synthetic ones. To this end, FYI embeds a horizontal flipping technique into distillation processes, mitigating the influence of the bilateral equivalence, while capturing more details of objects. Experiments on CIFAR-10/100, Tiny-ImageNet, and ImageNet demonstrate that FYI can be seamlessly integrated into several state-of-the-art methods, without modifying training objectives and network architectures, and it improves the performance remarkably.
ACLS: Adaptive and Conditional Label Smoothing for Network Calibration
Aug 24, 2023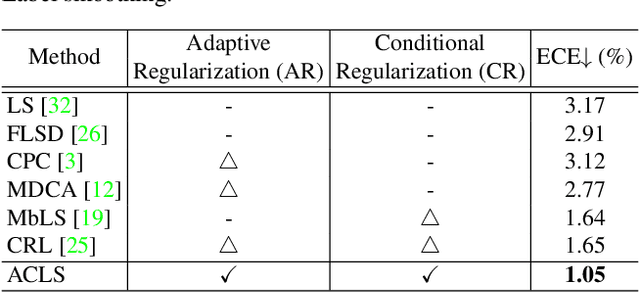
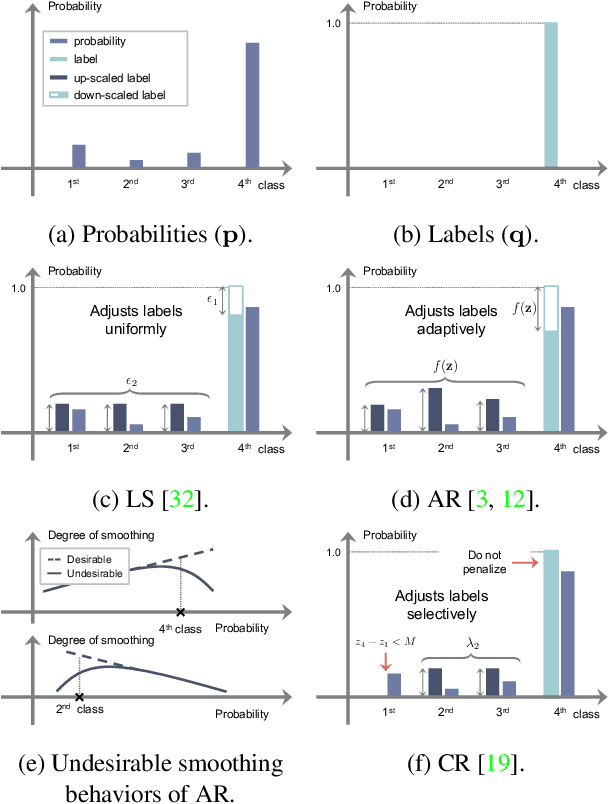
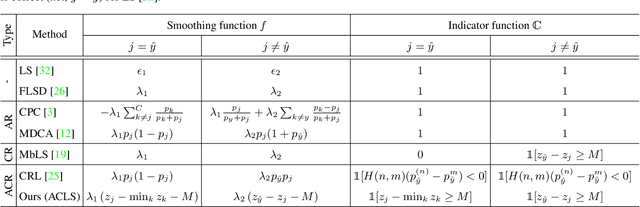
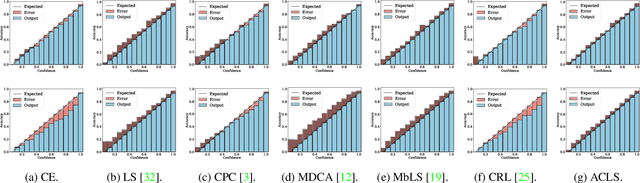
We address the problem of network calibration adjusting miscalibrated confidences of deep neural networks. Many approaches to network calibration adopt a regularization-based method that exploits a regularization term to smooth the miscalibrated confidences. Although these approaches have shown the effectiveness on calibrating the networks, there is still a lack of understanding on the underlying principles of regularization in terms of network calibration. We present in this paper an in-depth analysis of existing regularization-based methods, providing a better understanding on how they affect to network calibration. Specifically, we have observed that 1) the regularization-based methods can be interpreted as variants of label smoothing, and 2) they do not always behave desirably. Based on the analysis, we introduce a novel loss function, dubbed ACLS, that unifies the merits of existing regularization methods, while avoiding the limitations. We show extensive experimental results for image classification and semantic segmentation on standard benchmarks, including CIFAR10, Tiny-ImageNet, ImageNet, and PASCAL VOC, demonstrating the effectiveness of our loss function.
ALIFE: Adaptive Logit Regularizer and Feature Replay for Incremental Semantic Segmentation
Oct 13, 2022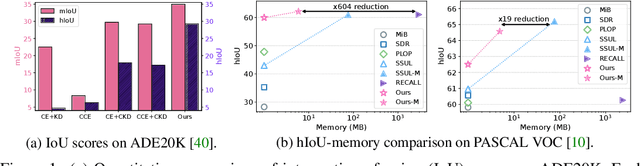
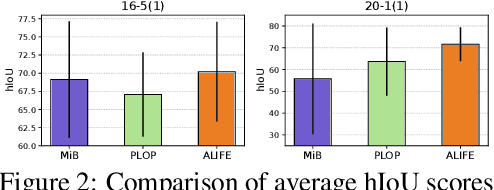


We address the problem of incremental semantic segmentation (ISS) recognizing novel object/stuff categories continually without forgetting previous ones that have been learned. The catastrophic forgetting problem is particularly severe in ISS, since pixel-level ground-truth labels are available only for the novel categories at training time. To address the problem, regularization-based methods exploit probability calibration techniques to learn semantic information from unlabeled pixels. While such techniques are effective, there is still a lack of theoretical understanding of them. Replay-based methods propose to memorize a small set of images for previous categories. They achieve state-of-the-art performance at the cost of large memory footprint. We propose in this paper a novel ISS method, dubbed ALIFE, that provides a better compromise between accuracy and efficiency. To this end, we first show an in-depth analysis on the calibration techniques to better understand the effects on ISS. Based on this, we then introduce an adaptive logit regularizer (ALI) that enables our model to better learn new categories, while retaining knowledge for previous ones. We also present a feature replay scheme that memorizes features, instead of images directly, in order to reduce memory requirements significantly. Since a feature extractor is changed continually, memorized features should also be updated at every incremental stage. To handle this, we introduce category-specific rotation matrices updating the features for each category separately. We demonstrate the effectiveness of our approach with extensive experiments on standard ISS benchmarks, and show that our method achieves a better trade-off in terms of accuracy and efficiency.
Decomposed Knowledge Distillation for Class-Incremental Semantic Segmentation
Oct 12, 2022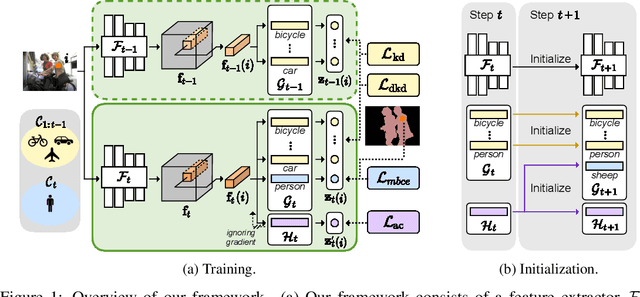
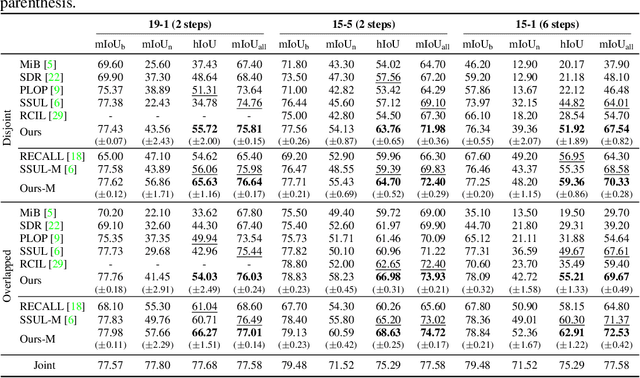
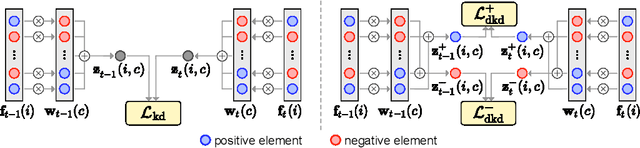
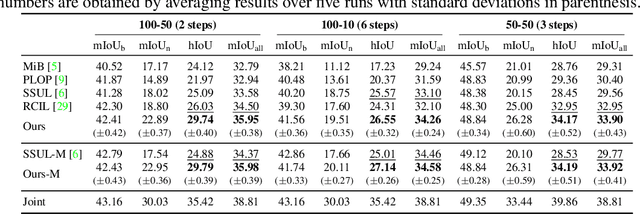
Class-incremental semantic segmentation (CISS) labels each pixel of an image with a corresponding object/stuff class continually. To this end, it is crucial to learn novel classes incrementally without forgetting previously learned knowledge. Current CISS methods typically use a knowledge distillation (KD) technique for preserving classifier logits, or freeze a feature extractor, to avoid the forgetting problem. The strong constraints, however, prevent learning discriminative features for novel classes. We introduce a CISS framework that alleviates the forgetting problem and facilitates learning novel classes effectively. We have found that a logit can be decomposed into two terms. They quantify how likely an input belongs to a particular class or not, providing a clue for a reasoning process of a model. The KD technique, in this context, preserves the sum of two terms (i.e., a class logit), suggesting that each could be changed and thus the KD does not imitate the reasoning process. To impose constraints on each term explicitly, we propose a new decomposed knowledge distillation (DKD) technique, improving the rigidity of a model and addressing the forgetting problem more effectively. We also introduce a novel initialization method to train new classifiers for novel classes. In CISS, the number of negative training samples for novel classes is not sufficient to discriminate old classes. To mitigate this, we propose to transfer knowledge of negatives to the classifiers successively using an auxiliary classifier, boosting the performance significantly. Experimental results on standard CISS benchmarks demonstrate the effectiveness of our framework.
OIMNet++: Prototypical Normalization and Localization-aware Learning for Person Search
Jul 21, 2022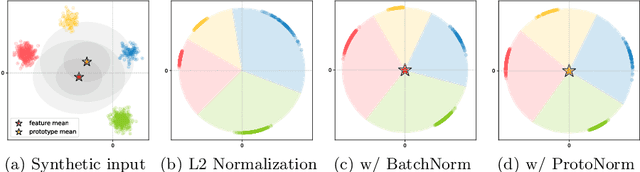
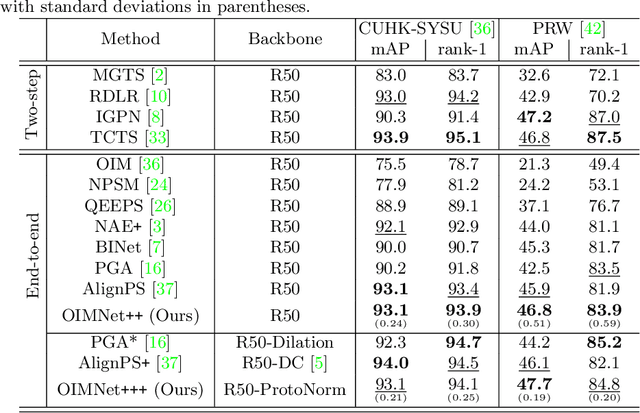
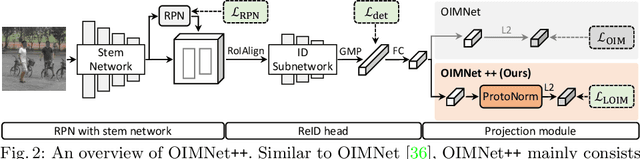
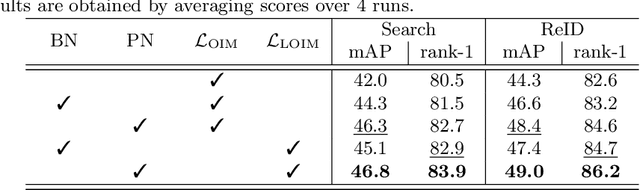
We address the task of person search, that is, localizing and re-identifying query persons from a set of raw scene images. Recent approaches are typically built upon OIMNet, a pioneer work on person search, that learns joint person representations for performing both detection and person re-identification (reID) tasks. To obtain the representations, they extract features from pedestrian proposals, and then project them on a unit hypersphere with L2 normalization. These methods also incorporate all positive proposals, that sufficiently overlap with the ground truth, equally to learn person representations for reID. We have found that 1) the L2 normalization without considering feature distributions degenerates the discriminative power of person representations, and 2) positive proposals often also depict background clutter and person overlaps, which could encode noisy features to person representations. In this paper, we introduce OIMNet++ that addresses the aforementioned limitations. To this end, we introduce a novel normalization layer, dubbed ProtoNorm, that calibrates features from pedestrian proposals, while considering a long-tail distribution of person IDs, enabling L2 normalized person representations to be discriminative. We also propose a localization-aware feature learning scheme that encourages better-aligned proposals to contribute more in learning discriminative representations. Experimental results and analysis on standard person search benchmarks demonstrate the effectiveness of OIMNet++.
Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation
Aug 14, 2021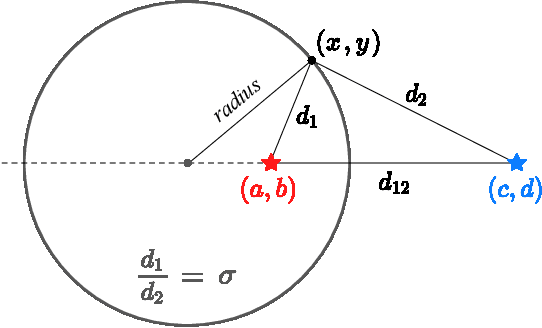


We address the problem of generalized zero-shot semantic segmentation (GZS3) predicting pixel-wise semantic labels for seen and unseen classes. Most GZS3 methods adopt a generative approach that synthesizes visual features of unseen classes from corresponding semantic ones (e.g., word2vec) to train novel classifiers for both seen and unseen classes. Although generative methods show decent performance, they have two limitations: (1) the visual features are biased towards seen classes; (2) the classifier should be retrained whenever novel unseen classes appear. We propose a discriminative approach to address these limitations in a unified framework. To this end, we leverage visual and semantic encoders to learn a joint embedding space, where the semantic encoder transforms semantic features to semantic prototypes that act as centers for visual features of corresponding classes. Specifically, we introduce boundary-aware regression (BAR) and semantic consistency (SC) losses to learn discriminative features. Our approach to exploiting the joint embedding space, together with BAR and SC terms, alleviates the seen bias problem. At test time, we avoid the retraining process by exploiting semantic prototypes as a nearest-neighbor (NN) classifier. To further alleviate the bias problem, we also propose an inference technique, dubbed Apollonius calibration (AC), that modulates the decision boundary of the NN classifier to the Apollonius circle adaptively. Experimental results demonstrate the effectiveness of our framework, achieving a new state of the art on standard benchmarks.