 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelightable and Dynamic Gaussian Avatar Reconstruction from Monocular Video
Dec 11, 2025Modeling relightable and animatable human avatars from monocular video is a long-standing and challenging task. Recently, Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) methods have been employed to reconstruct the avatars. However, they often produce unsatisfactory photo-realistic results because of insufficient geometrical details related to body motion, such as clothing wrinkles. In this paper, we propose a 3DGS-based human avatar modeling framework, termed as Relightable and Dynamic Gaussian Avatar (RnD-Avatar), that presents accurate pose-variant deformation for high-fidelity geometrical details. To achieve this, we introduce dynamic skinning weights that define the human avatar's articulation based on pose while also learning additional deformations induced by body motion. We also introduce a novel regularization to capture fine geometric details under sparse visual cues. Furthermore, we present a new multi-view dataset with varied lighting conditions to evaluate relight. Our framework enables realistic rendering of novel poses and views while supporting photo-realistic lighting effects under arbitrary lighting conditions. Our method achieves state-of-the-art performance in novel view synthesis, novel pose rendering, and relighting.
* 8 pages, 9 figures, published in ACM MM 2025
Dependency Chain Analysis of ROS 2 DDS QoS Policies: From Lifecycle Tutorial to Static Verification
Sep 03, 2025Robot Operating System 2 (ROS 2) relies on the Data Distribution Service (DDS), which offers more than 20 Quality of Service (QoS) policies governing availability, reliability, and resource usage. Yet ROS 2 users lack clear guidance on safe policy combinations and validation processes prior to deployment, which often leads to trial-and-error tuning and unexpected runtime failures. To address these challenges, we analyze DDS Publisher-Subscriber communication over a life cycle divided into Discovery, Data Exchange, and Disassociation, and provide a user oriented tutorial explaining how 16 QoS policies operate in each phase. Building on this analysis, we derive a QoS dependency chain that formalizes inter-policy relationships and classifies 41 dependency violation rules, capturing constraints that commonly cause communication failures in practice. Finally, we introduce QoS Guard, a ROS 2 package that statically validates DDS XML profiles offline, flags conflicts, and enables safe, predeployment tuning without establishing a live ROS 2 session. Together, these contributions give ROS 2 users both conceptual insight and a concrete tool that enables early detection of misconfigurations, improving the reliability and resource efficiency of ROS 2 based robotic systems.
Probabilistic Latency Analysis of the Data Distribution Service in ROS 2
Aug 14, 2025Robot Operating System 2 (ROS 2) is now the de facto standard for robotic communication, pairing UDP transport with the Data Distribution Service (DDS) publish-subscribe middleware. DDS achieves reliability through periodic heartbeats that solicit acknowledgments for missing samples and trigger selective retransmissions. In lossy wireless networks, the tight coupling among heartbeat period, IP fragmentation, and retransmission interval obscures end to end latency behavior and leaves practitioners with little guidance on how to tune these parameters. To address these challenges, we propose a probabilistic latency analysis (PLA) that analytically models the reliable transmission process of ROS 2 DDS communication using a discrete state approach. By systematically analyzing both middleware level and transport level events, PLA computes the steady state probability distribution of unacknowledged messages and the retransmission latency. We validate our PLA across 270 scenarios, exploring variations in packet delivery ratios, message sizes, and both publishing and retransmission intervals, demonstrating a close alignment between analytical predictions and experimental results. Our findings establish a theoretical basis to systematically optimize reliability, latency, and performance in wireless industrial robotics.
Tri-MTL: A Triple Multitask Learning Approach for Respiratory Disease Diagnosis
May 06, 2025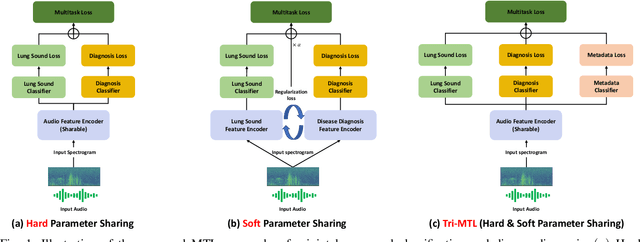
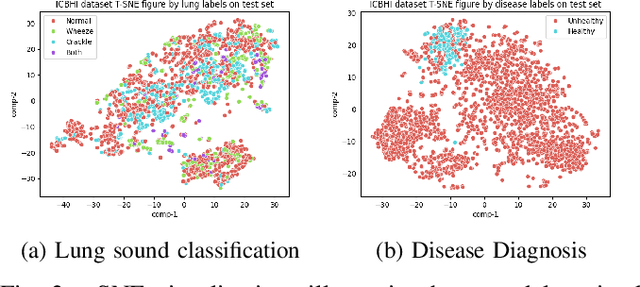
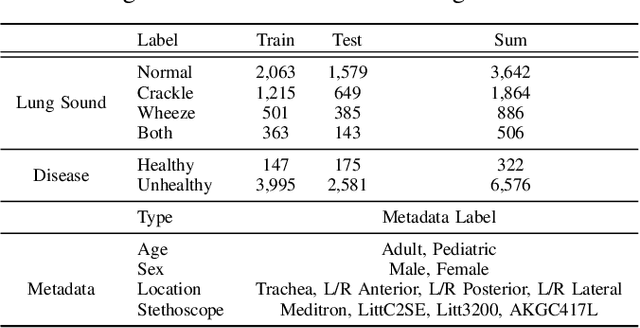
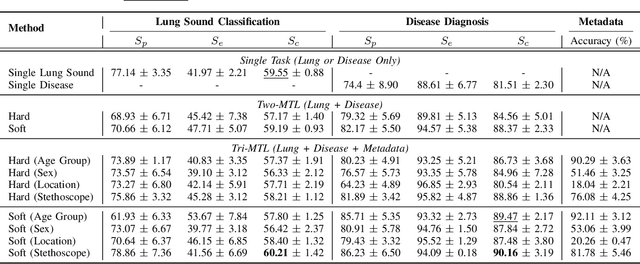
Auscultation remains a cornerstone of clinical practice, essential for both initial evaluation and continuous monitoring. Clinicians listen to the lung sounds and make a diagnosis by combining the patient's medical history and test results. Given this strong association, multitask learning (MTL) can offer a compelling framework to simultaneously model these relationships, integrating respiratory sound patterns with disease manifestations. While MTL has shown considerable promise in medical applications, a significant research gap remains in understanding the complex interplay between respiratory sounds, disease manifestations, and patient metadata attributes. This study investigates how integrating MTL with cutting-edge deep learning architectures can enhance both respiratory sound classification and disease diagnosis. Specifically, we extend recent findings regarding the beneficial impact of metadata on respiratory sound classification by evaluating its effectiveness within an MTL framework. Our comprehensive experiments reveal significant improvements in both lung sound classification and diagnostic performance when the stethoscope information is incorporated into the MTL architecture.
Unveiling the Invisible: Reasoning Complex Occlusions Amodally with AURA
Mar 13, 2025Amodal segmentation aims to infer the complete shape of occluded objects, even when the occluded region's appearance is unavailable. However, current amodal segmentation methods lack the capability to interact with users through text input and struggle to understand or reason about implicit and complex purposes. While methods like LISA integrate multi-modal large language models (LLMs) with segmentation for reasoning tasks, they are limited to predicting only visible object regions and face challenges in handling complex occlusion scenarios. To address these limitations, we propose a novel task named amodal reasoning segmentation, aiming to predict the complete amodal shape of occluded objects while providing answers with elaborations based on user text input. We develop a generalizable dataset generation pipeline and introduce a new dataset focusing on daily life scenarios, encompassing diverse real-world occlusions. Furthermore, we present AURA (Amodal Understanding and Reasoning Assistant), a novel model with advanced global and spatial-level designs specifically tailored to handle complex occlusions. Extensive experiments validate AURA's effectiveness on the proposed dataset. The code, model, and dataset will be publicly released.
BEAT: Balanced Frequency Adaptive Tuning for Long-Term Time-Series Forecasting
Jan 31, 2025



Time-series forecasting is crucial for numerous real-world applications including weather prediction and financial market modeling. While temporal-domain methods remain prevalent, frequency-domain approaches can effectively capture multi-scale periodic patterns, reduce sequence dependencies, and naturally denoise signals. However, existing approaches typically train model components for all frequencies under a unified training objective, often leading to mismatched learning speeds: high-frequency components converge faster and risk overfitting, while low-frequency components underfit due to insufficient training time. To deal with this challenge, we propose BEAT (Balanced frEquency Adaptive Tuning), a novel framework that dynamically monitors the training status for each frequency and adaptively adjusts their gradient updates. By recognizing convergence, overfitting, or underfitting for each frequency, BEAT dynamically reallocates learning priorities, moderating gradients for rapid learners and increasing those for slower ones, alleviating the tension between competing objectives across frequencies and synchronizing the overall learning process. Extensive experiments on seven real-world datasets demonstrate that BEAT consistently outperforms state-of-the-art approaches.
TurboHopp: Accelerated Molecule Scaffold Hopping with Consistency Models
Oct 28, 2024



Navigating the vast chemical space of druggable compounds is a formidable challenge in drug discovery, where generative models are increasingly employed to identify viable candidates. Conditional 3D structure-based drug design (3D-SBDD) models, which take into account complex three-dimensional interactions and molecular geometries, are particularly promising. Scaffold hopping is an efficient strategy that facilitates the identification of similar active compounds by strategically modifying the core structure of molecules, effectively narrowing the wide chemical space and enhancing the discovery of drug-like products. However, the practical application of 3D-SBDD generative models is hampered by their slow processing speeds. To address this bottleneck, we introduce TurboHopp, an accelerated pocket-conditioned 3D scaffold hopping model that merges the strategic effectiveness of traditional scaffold hopping with rapid generation capabilities of consistency models. This synergy not only enhances efficiency but also significantly boosts generation speeds, achieving up to 30 times faster inference speed as well as superior generation quality compared to existing diffusion-based models, establishing TurboHopp as a powerful tool in drug discovery. Supported by faster inference speed, we further optimize our model, using Reinforcement Learning for Consistency Models (RLCM), to output desirable molecules. We demonstrate the broad applicability of TurboHopp across multiple drug discovery scenarios, underscoring its potential in diverse molecular settings.
Learning-enabled Flexible Job-shop Scheduling for Scalable Smart Manufacturing
Feb 14, 2024



In smart manufacturing systems (SMSs), flexible job-shop scheduling with transportation constraints (FJSPT) is essential to optimize solutions for maximizing productivity, considering production flexibility based on automated guided vehicles (AGVs). Recent developments in deep reinforcement learning (DRL)-based methods for FJSPT have encountered a scale generalization challenge. These methods underperform when applied to environment at scales different from their training set, resulting in low-quality solutions. To address this, we introduce a novel graph-based DRL method, named the Heterogeneous Graph Scheduler (HGS). Our method leverages locally extracted relational knowledge among operations, machines, and vehicle nodes for scheduling, with a graph-structured decision-making framework that reduces encoding complexity and enhances scale generalization. Our performance evaluation, conducted with benchmark datasets, reveals that the proposed method outperforms traditional dispatching rules, meta-heuristics, and existing DRL-based approaches in terms of makespan performance, even on large-scale instances that have not been experienced during training.
MolPLA: A Molecular Pretraining Framework for Learning Cores, R-Groups and their Linker Joints
Jan 30, 2024Molecular core structures and R-groups are essential concepts in drug development. Integration of these concepts with conventional graph pre-training approaches can promote deeper understanding in molecules. We propose MolPLA, a novel pre-training framework that employs masked graph contrastive learning in understanding the underlying decomposable parts inmolecules that implicate their core structure and peripheral R-groups. Furthermore, we formulate an additional framework that grants MolPLA the ability to help chemists find replaceable R-groups in lead optimization scenarios. Experimental results on molecular property prediction show that MolPLA exhibits predictability comparable to current state-of-the-art models. Qualitative analysis implicate that MolPLA is capable of distinguishing core and R-group sub-structures, identifying decomposable regions in molecules and contributing to lead optimization scenarios by rationally suggesting R-group replacements given various query core templates. The code implementation for MolPLA and its pre-trained model checkpoint is available at https://github.com/dmis-lab/MolPLA
Camera-Driven Representation Learning for Unsupervised Domain Adaptive Person Re-identification
Aug 23, 2023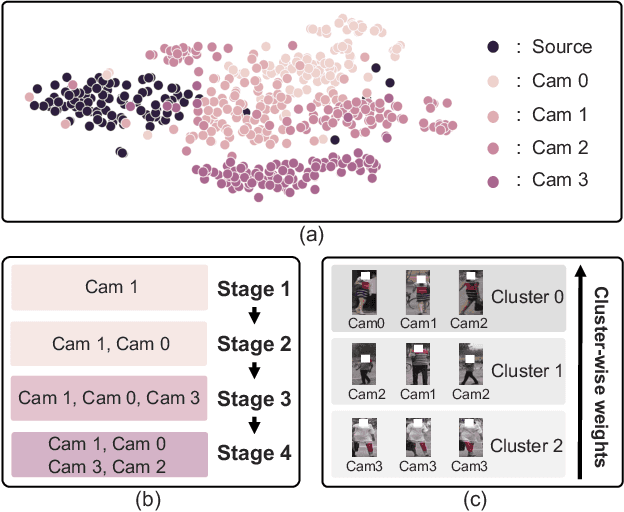

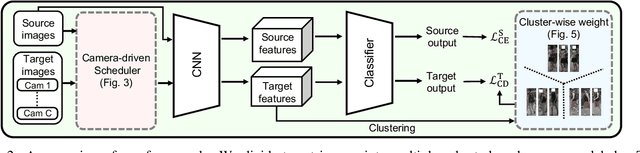

We present a novel unsupervised domain adaption method for person re-identification (reID) that generalizes a model trained on a labeled source domain to an unlabeled target domain. We introduce a camera-driven curriculum learning (CaCL) framework that leverages camera labels of person images to transfer knowledge from source to target domains progressively. To this end, we divide target domain dataset into multiple subsets based on the camera labels, and initially train our model with a single subset (i.e., images captured by a single camera). We then gradually exploit more subsets for training, according to a curriculum sequence obtained with a camera-driven scheduling rule. The scheduler considers maximum mean discrepancies (MMD) between each subset and the source domain dataset, such that the subset closer to the source domain is exploited earlier within the curriculum. For each curriculum sequence, we generate pseudo labels of person images in a target domain to train a reID model in a supervised way. We have observed that the pseudo labels are highly biased toward cameras, suggesting that person images obtained from the same camera are likely to have the same pseudo labels, even for different IDs. To address the camera bias problem, we also introduce a camera-diversity (CD) loss encouraging person images of the same pseudo label, but captured across various cameras, to involve more for discriminative feature learning, providing person representations robust to inter-camera variations. Experimental results on standard benchmarks, including real-to-real and synthetic-to-real scenarios, demonstrate the effectiveness of our framework.