 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Offline RL via Efficient and Expressive Shortcut Models
May 28, 2025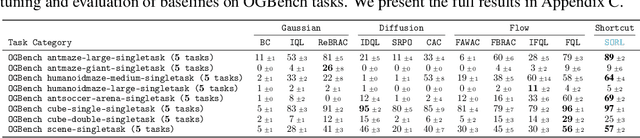
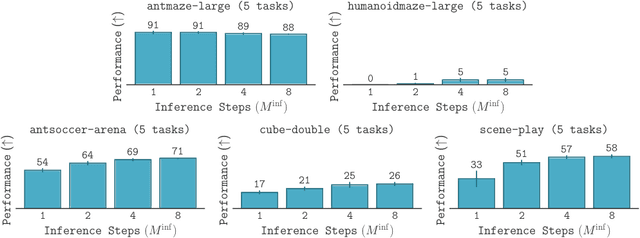
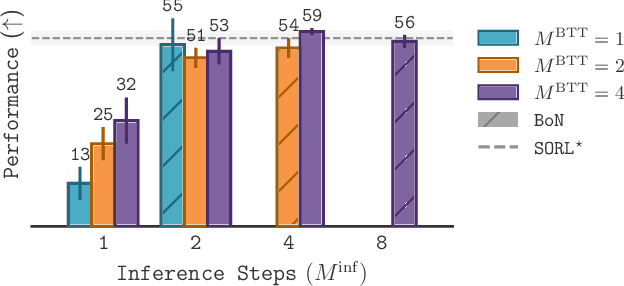
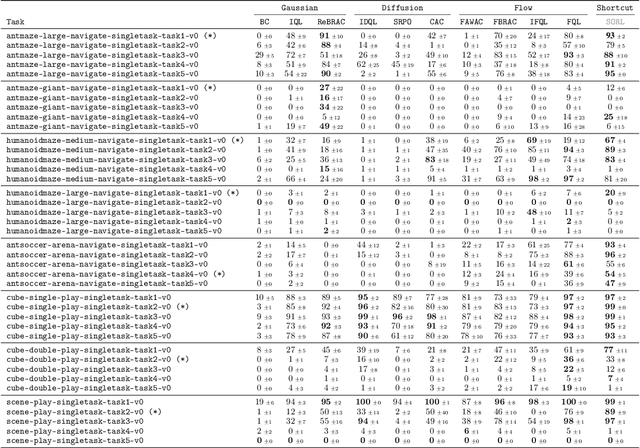
Diffusion and flow models have emerged as powerful generative approaches capable of modeling diverse and multimodal behavior. However, applying these models to offline reinforcement learning (RL) remains challenging due to the iterative nature of their noise sampling processes, making policy optimization difficult. In this paper, we introduce Scalable Offline Reinforcement Learning (SORL), a new offline RL algorithm that leverages shortcut models - a novel class of generative models - to scale both training and inference. SORL's policy can capture complex data distributions and can be trained simply and efficiently in a one-stage training procedure. At test time, SORL introduces both sequential and parallel inference scaling by using the learned Q-function as a verifier. We demonstrate that SORL achieves strong performance across a range of offline RL tasks and exhibits positive scaling behavior with increased test-time compute. We release the code at nico-espinosadice.github.io/projects/sorl.
Efficient Controllable Diffusion via Optimal Classifier Guidance
May 27, 2025The controllable generation of diffusion models aims to steer the model to generate samples that optimize some given objective functions. It is desirable for a variety of applications including image generation, molecule generation, and DNA/sequence generation. Reinforcement Learning (RL) based fine-tuning of the base model is a popular approach but it can overfit the reward function while requiring significant resources. We frame controllable generation as a problem of finding a distribution that optimizes a KL-regularized objective function. We present SLCD -- Supervised Learning based Controllable Diffusion, which iteratively generates online data and trains a small classifier to guide the generation of the diffusion model. Similar to the standard classifier-guided diffusion, SLCD's key computation primitive is classification and does not involve any complex concepts from RL or control. Via a reduction to no-regret online learning analysis, we show that under KL divergence, the output from SLCD provably converges to the optimal solution of the KL-regularized objective. Further, we empirically demonstrate that SLCD can generate high quality samples with nearly the same inference time as the base model in both image generation with continuous diffusion and biological sequence generation with discrete diffusion. Our code is available at https://github.com/Owen-Oertell/slcd
Convergence Of Consistency Model With Multistep Sampling Under General Data Assumptions
May 06, 2025Diffusion models accomplish remarkable success in data generation tasks across various domains. However, the iterative sampling process is computationally expensive. Consistency models are proposed to learn consistency functions to map from noise to data directly, which allows one-step fast data generation and multistep sampling to improve sample quality. In this paper, we study the convergence of consistency models when the self-consistency property holds approximately under the training distribution. Our analysis requires only mild data assumption and applies to a family of forward processes. When the target data distribution has bounded support or has tails that decay sufficiently fast, we show that the samples generated by the consistency model are close to the target distribution in Wasserstein distance; when the target distribution satisfies some smoothness assumption, we show that with an additional perturbation step for smoothing, the generated samples are close to the target distribution in total variation distance. We provide two case studies with commonly chosen forward processes to demonstrate the benefit of multistep sampling.
TurboHopp: Accelerated Molecule Scaffold Hopping with Consistency Models
Oct 28, 2024



Navigating the vast chemical space of druggable compounds is a formidable challenge in drug discovery, where generative models are increasingly employed to identify viable candidates. Conditional 3D structure-based drug design (3D-SBDD) models, which take into account complex three-dimensional interactions and molecular geometries, are particularly promising. Scaffold hopping is an efficient strategy that facilitates the identification of similar active compounds by strategically modifying the core structure of molecules, effectively narrowing the wide chemical space and enhancing the discovery of drug-like products. However, the practical application of 3D-SBDD generative models is hampered by their slow processing speeds. To address this bottleneck, we introduce TurboHopp, an accelerated pocket-conditioned 3D scaffold hopping model that merges the strategic effectiveness of traditional scaffold hopping with rapid generation capabilities of consistency models. This synergy not only enhances efficiency but also significantly boosts generation speeds, achieving up to 30 times faster inference speed as well as superior generation quality compared to existing diffusion-based models, establishing TurboHopp as a powerful tool in drug discovery. Supported by faster inference speed, we further optimize our model, using Reinforcement Learning for Consistency Models (RLCM), to output desirable molecules. We demonstrate the broad applicability of TurboHopp across multiple drug discovery scenarios, underscoring its potential in diverse molecular settings.
REBEL: Reinforcement Learning via Regressing Relative Rewards
Apr 25, 2024While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping) and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative rewards via a direct policy parameterization between two completions to a prompt, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally tractable than PPO.
Dataset Reset Policy Optimization for RLHF
Apr 15, 2024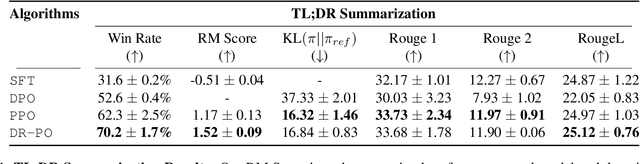
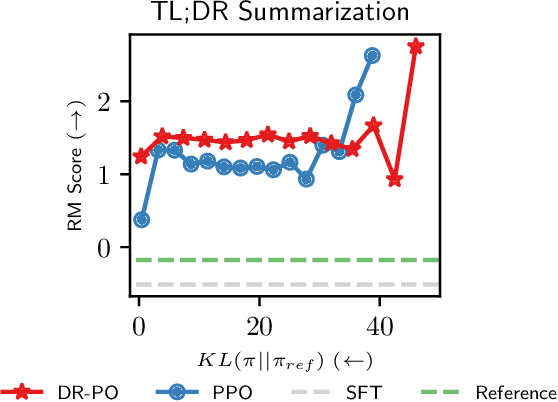


Reinforcement Learning (RL) from Human Preference-based feedback is a popular paradigm for fine-tuning generative models, which has produced impressive models such as GPT-4 and Claude3 Opus. This framework often consists of two steps: learning a reward model from an offline preference dataset followed by running online RL to optimize the learned reward model. In this work, leveraging the idea of reset, we propose a new RLHF algorithm with provable guarantees. Motivated by the fact that offline preference dataset provides informative states (i.e., data that is preferred by the labelers), our new algorithm, Dataset Reset Policy Optimization (DR-PO), integrates the existing offline preference dataset into the online policy training procedure via dataset reset: it directly resets the policy optimizer to the states in the offline dataset, instead of always starting from the initial state distribution. In theory, we show that DR-PO learns to perform at least as good as any policy that is covered by the offline dataset under general function approximation with finite sample complexity. In experiments, we demonstrate that on both the TL;DR summarization and the Anthropic Helpful Harmful (HH) dataset, the generation from DR-PO is better than that from Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO), under the metric of GPT4 win-rate. Code for this work can be found at https://github.com/Cornell-RL/drpo.
RL for Consistency Models: Faster Reward Guided Text-to-Image Generation
Mar 25, 2024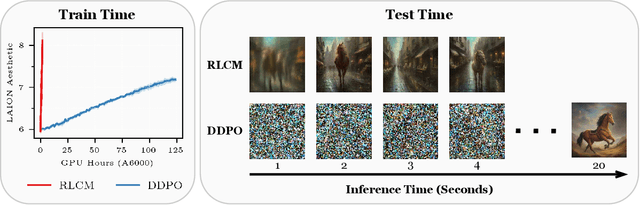
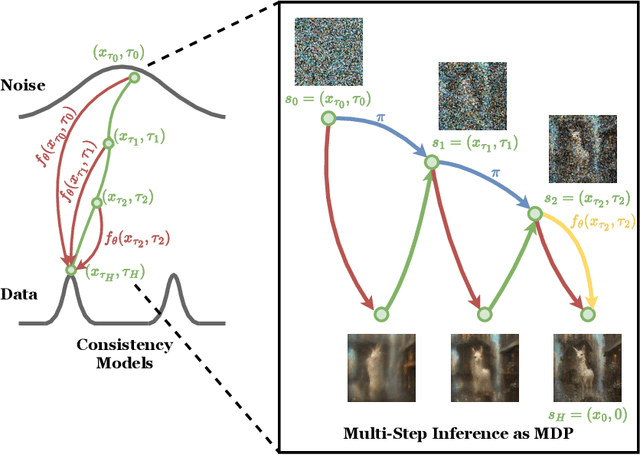

Reinforcement learning (RL) has improved guided image generation with diffusion models by directly optimizing rewards that capture image quality, aesthetics, and instruction following capabilities. However, the resulting generative policies inherit the same iterative sampling process of diffusion models that causes slow generation. To overcome this limitation, consistency models proposed learning a new class of generative models that directly map noise to data, resulting in a model that can generate an image in as few as one sampling iteration. In this work, to optimize text-to-image generative models for task specific rewards and enable fast training and inference, we propose a framework for fine-tuning consistency models via RL. Our framework, called Reinforcement Learning for Consistency Model (RLCM), frames the iterative inference process of a consistency model as an RL procedure. RLCM improves upon RL fine-tuned diffusion models on text-to-image generation capabilities and trades computation during inference time for sample quality. Experimentally, we show that RLCM can adapt text-to-image consistency models to objectives that are challenging to express with prompting, such as image compressibility, and those derived from human feedback, such as aesthetic quality. Comparing to RL finetuned diffusion models, RLCM trains significantly faster, improves the quality of the generation measured under the reward objectives, and speeds up the inference procedure by generating high quality images with as few as two inference steps. Our code is available at https://rlcm.owenoertell.com
More Benefits of Being Distributional: Second-Order Bounds for Reinforcement Learning
Feb 11, 2024In this paper, we prove that Distributional Reinforcement Learning (DistRL), which learns the return distribution, can obtain second-order bounds in both online and offline RL in general settings with function approximation. Second-order bounds are instance-dependent bounds that scale with the variance of return, which we prove are tighter than the previously known small-loss bounds of distributional RL. To the best of our knowledge, our results are the first second-order bounds for low-rank MDPs and for offline RL. When specializing to contextual bandits (one-step RL problem), we show that a distributional learning based optimism algorithm achieves a second-order worst-case regret bound, and a second-order gap dependent bound, simultaneously. We also empirically demonstrate the benefit of DistRL in contextual bandits on real-world datasets. We highlight that our analysis with DistRL is relatively simple, follows the general framework of optimism in the face of uncertainty and does not require weighted regression. Our results suggest that DistRL is a promising framework for obtaining second-order bounds in general RL settings, thus further reinforcing the benefits of DistRL.