 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Static Benchmarks to Dynamic Protocol: Agent-Centric Text Anomaly Detection for Evaluating LLM Reasoning
Feb 27, 2026The evaluation of large language models (LLMs) has predominantly relied on static datasets, which offer limited scalability and fail to capture the evolving reasoning capabilities of recent models. To overcome these limitations, we propose an agent-centric benchmarking paradigm that moves beyond static datasets by introducing a dynamic protocol in which autonomous agents iteratively generate, validate, and solve problems. Within this protocol, a teacher agent generates candidate problems, an orchestrator agent rigorously verifies their validity and guards against adversarial attacks, and a student agent attempts to solve the validated problems. An invalid problem is revised by the teacher agent until it passes validation. If the student correctly solves the problem, the orchestrator prompts the teacher to generate more challenging variants. Consequently, the benchmark scales in difficulty automatically as more capable agents are substituted into any role, enabling progressive evaluation of large language models without manually curated datasets. Adopting text anomaly detection as our primary evaluation format, which demands cross-sentence logical inference and resists pattern-matching shortcuts, we demonstrate that this protocol systematically exposes corner-case reasoning errors that conventional benchmarks fail to reveal. We further advocate evaluating systems along several complementary axes including cross-model pairwise performance and progress between the initial and orchestrator-finalized problems. By shifting the focus from fixed datasets to dynamic protocols, our approach offers a sustainable direction for evaluating ever-evolving language models and introduces a research agenda centered on the co-evolution of agent-centric benchmarks.
HiRef: Leveraging Hierarchical Ontology and Network Refinement for Robust Medication Recommendation
Aug 14, 2025Medication recommendation is a crucial task for assisting physicians in making timely decisions from longitudinal patient medical records. However, real-world EHR data present significant challenges due to the presence of rarely observed medical entities and incomplete records that may not fully capture the clinical ground truth. While data-driven models trained on longitudinal Electronic Health Records often achieve strong empirical performance, they struggle to generalize under missing or novel conditions, largely due to their reliance on observed co-occurrence patterns. To address these issues, we propose Hierarchical Ontology and Network Refinement for Robust Medication Recommendation (HiRef), a unified framework that combines two complementary structures: (i) the hierarchical semantics encoded in curated medical ontologies, and (ii) refined co-occurrence patterns derived from real-world EHRs. We embed ontology entities in hyperbolic space, which naturally captures tree-like relationships and enables knowledge transfer through shared ancestors, thereby improving generalizability to unseen codes. To further improve robustness, we introduce a prior-guided sparse regularization scheme that refines the EHR co-occurrence graph by suppressing spurious edges while preserving clinically meaningful associations. Our model achieves strong performance on EHR benchmarks (MIMIC-III and MIMIC-IV) and maintains high accuracy under simulated unseen-code settings. Extensive experiments with comprehensive ablation studies demonstrate HiRef's resilience to unseen medical codes, supported by in-depth analyses of the learned sparsified graph structure and medical code embeddings.
Cold-Start Recommendation with Knowledge-Guided Retrieval-Augmented Generation
May 27, 2025Cold-start items remain a persistent challenge in recommender systems due to their lack of historical user interactions, which collaborative models rely on. While recent zero-shot methods leverage large language models (LLMs) to address this, they often struggle with sparse metadata and hallucinated or incomplete knowledge. We propose ColdRAG, a retrieval-augmented generation approach that builds a domain-specific knowledge graph dynamically to enhance LLM-based recommendation in cold-start scenarios, without requiring task-specific fine-tuning. ColdRAG begins by converting structured item attributes into rich natural-language profiles, from which it extracts entities and relationships to construct a unified knowledge graph capturing item semantics. Given a user's interaction history, it scores edges in the graph using an LLM, retrieves candidate items with supporting evidence, and prompts the LLM to rank them. By enabling multi-hop reasoning over this graph, ColdRAG grounds recommendations in verifiable evidence, reducing hallucinations and strengthening semantic connections. Experiments on three public benchmarks demonstrate that ColdRAG surpasses existing zero-shot baselines in both Recall and NDCG. This framework offers a practical solution to cold-start recommendation by combining knowledge-graph reasoning with retrieval-augmented LLM generation.
BRIDO: Bringing Democratic Order to Abstractive Summarization
Feb 25, 2025



Hallucination refers to the inaccurate, irrelevant, and inconsistent text generated from large language models (LLMs). While the LLMs have shown great promise in a variety of tasks, the issue of hallucination still remains a major challenge for many practical uses. In this paper, we tackle the issue of hallucination in abstract text summarization by mitigating exposure bias. Existing models targeted for exposure bias mitigation, namely BRIO, aim for better summarization quality in the ROUGE score. We propose a model that uses a similar exposure bias mitigation strategy but with a goal that is aligned with less hallucination. We conjecture that among a group of candidate outputs, ones with hallucinations will comprise the minority of the whole group. That is, candidates with less similarity with others will have a higher chance of containing hallucinated content. Our method uses this aspect and utilizes contrastive learning, incentivizing candidates with high inter-candidate ROUGE scores. We performed experiments on the XSum and CNN/DM summarization datasets, and our method showed 6.25% and 3.82% improvement, respectively, on the consistency G-Eval score over BRIO.
Hansel: Output Length Controlling Framework for Large Language Models
Dec 18, 2024Despite the great success of large language models (LLMs), efficiently controlling the length of the output sequence still remains a challenge. In this paper, we propose Hansel, an efficient framework for length control in LLMs without affecting its generation ability. Hansel utilizes periodically outputted hidden special tokens to keep track of the remaining target length of the output sequence. Together with techniques to avoid abrupt termination of the output, this seemingly simple method proved to be efficient and versatile, while not harming the coherency and fluency of the generated text. The framework can be applied to any pre-trained LLMs during the finetuning stage of the model, regardless of its original positional encoding method. We demonstrate this by finetuning four different LLMs with Hansel and show that the mean absolute error of the output sequence decreases significantly in every model and dataset compared to the prompt-based length control finetuning. Moreover, the framework showed a substantially improved ability to extrapolate to target lengths unseen during finetuning, such as long dialog responses or extremely short summaries. This indicates that the model learns the general means of length control, rather than learning to match output lengths to those seen during training.
TurboHopp: Accelerated Molecule Scaffold Hopping with Consistency Models
Oct 28, 2024



Navigating the vast chemical space of druggable compounds is a formidable challenge in drug discovery, where generative models are increasingly employed to identify viable candidates. Conditional 3D structure-based drug design (3D-SBDD) models, which take into account complex three-dimensional interactions and molecular geometries, are particularly promising. Scaffold hopping is an efficient strategy that facilitates the identification of similar active compounds by strategically modifying the core structure of molecules, effectively narrowing the wide chemical space and enhancing the discovery of drug-like products. However, the practical application of 3D-SBDD generative models is hampered by their slow processing speeds. To address this bottleneck, we introduce TurboHopp, an accelerated pocket-conditioned 3D scaffold hopping model that merges the strategic effectiveness of traditional scaffold hopping with rapid generation capabilities of consistency models. This synergy not only enhances efficiency but also significantly boosts generation speeds, achieving up to 30 times faster inference speed as well as superior generation quality compared to existing diffusion-based models, establishing TurboHopp as a powerful tool in drug discovery. Supported by faster inference speed, we further optimize our model, using Reinforcement Learning for Consistency Models (RLCM), to output desirable molecules. We demonstrate the broad applicability of TurboHopp across multiple drug discovery scenarios, underscoring its potential in diverse molecular settings.
CRADLE-VAE: Enhancing Single-Cell Gene Perturbation Modeling with Counterfactual Reasoning-based Artifact Disentanglement
Sep 10, 2024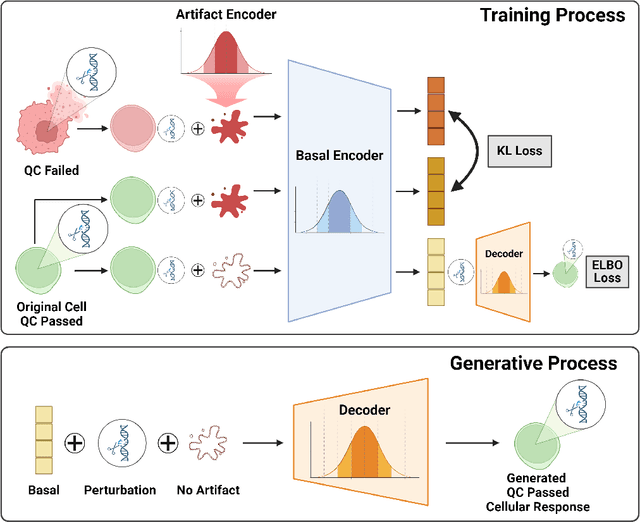
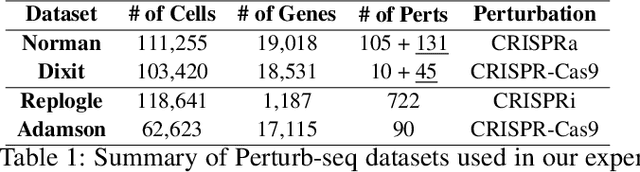
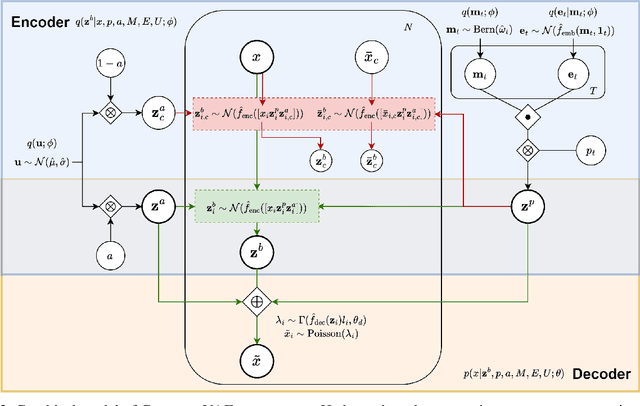
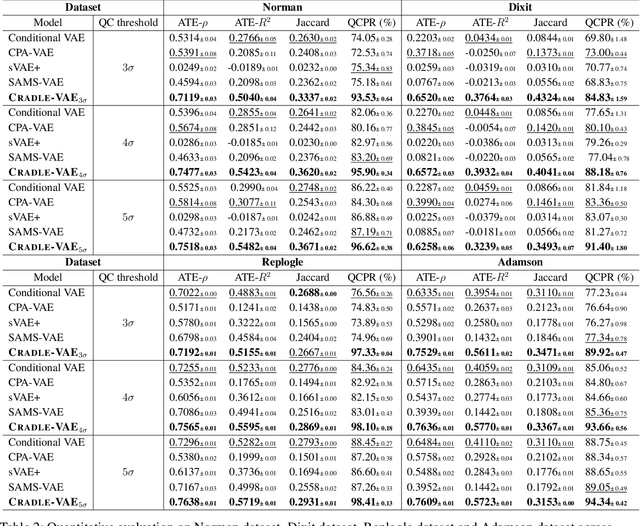
Predicting cellular responses to various perturbations is a critical focus in drug discovery and personalized therapeutics, with deep learning models playing a significant role in this endeavor. Single-cell datasets contain technical artifacts that may hinder the predictability of such models, which poses quality control issues highly regarded in this area. To address this, we propose CRADLE-VAE, a causal generative framework tailored for single-cell gene perturbation modeling, enhanced with counterfactual reasoning-based artifact disentanglement. Throughout training, CRADLE-VAE models the underlying latent distribution of technical artifacts and perturbation effects present in single-cell datasets. It employs counterfactual reasoning to effectively disentangle such artifacts by modulating the latent basal spaces and learns robust features for generating cellular response data with improved quality. Experimental results demonstrate that this approach improves not only treatment effect estimation performance but also generative quality as well. The CRADLE-VAE codebase is publicly available at https://github.com/dmis-lab/CRADLE-VAE.
Subgraph-level Universal Prompt Tuning
Feb 16, 2024



In the evolving landscape of machine learning, the adaptation of pre-trained models through prompt tuning has become increasingly prominent. This trend is particularly observable in the graph domain, where diverse pre-training strategies present unique challenges in developing effective prompt-based tuning methods for graph neural networks. Previous approaches have been limited, focusing on specialized prompting functions tailored to models with edge prediction pre-training tasks. These methods, however, suffer from a lack of generalizability across different pre-training strategies. Recently, a simple prompt tuning method has been designed for any pre-training strategy, functioning within the input graph's feature space. This allows it to theoretically emulate any type of prompting function, thereby significantly increasing its versatility for a range of downstream applications. Nevertheless, the capacity of such simple prompts to fully grasp the complex contexts found in graphs remains an open question, necessitating further investigation. Addressing this challenge, our work introduces the Subgraph-level Universal Prompt Tuning (SUPT) approach, focusing on the detailed context within subgraphs. In SUPT, prompt features are assigned at the subgraph-level, preserving the method's universal capability. This requires extremely fewer tuning parameters than fine-tuning-based methods, outperforming them in 42 out of 45 full-shot scenario experiments with an average improvement of over 2.5%. In few-shot scenarios, it excels in 41 out of 45 experiments, achieving an average performance increase of more than 6.6%.
MolPLA: A Molecular Pretraining Framework for Learning Cores, R-Groups and their Linker Joints
Jan 30, 2024Molecular core structures and R-groups are essential concepts in drug development. Integration of these concepts with conventional graph pre-training approaches can promote deeper understanding in molecules. We propose MolPLA, a novel pre-training framework that employs masked graph contrastive learning in understanding the underlying decomposable parts inmolecules that implicate their core structure and peripheral R-groups. Furthermore, we formulate an additional framework that grants MolPLA the ability to help chemists find replaceable R-groups in lead optimization scenarios. Experimental results on molecular property prediction show that MolPLA exhibits predictability comparable to current state-of-the-art models. Qualitative analysis implicate that MolPLA is capable of distinguishing core and R-group sub-structures, identifying decomposable regions in molecules and contributing to lead optimization scenarios by rationally suggesting R-group replacements given various query core templates. The code implementation for MolPLA and its pre-trained model checkpoint is available at https://github.com/dmis-lab/MolPLA
Co-attention Graph Pooling for Efficient Pairwise Graph Interaction Learning
Jul 28, 2023



Graph Neural Networks (GNNs) have proven to be effective in processing and learning from graph-structured data. However, previous works mainly focused on understanding single graph inputs while many real-world applications require pair-wise analysis for graph-structured data (e.g., scene graph matching, code searching, and drug-drug interaction prediction). To this end, recent works have shifted their focus to learning the interaction between pairs of graphs. Despite their improved performance, these works were still limited in that the interactions were considered at the node-level, resulting in high computational costs and suboptimal performance. To address this issue, we propose a novel and efficient graph-level approach for extracting interaction representations using co-attention in graph pooling. Our method, Co-Attention Graph Pooling (CAGPool), exhibits competitive performance relative to existing methods in both classification and regression tasks using real-world datasets, while maintaining lower computational complexity.
* Published at IEEE Access