 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiFloodSynth: Multi-Annotated Flood Synthetic Dataset Generation
Feb 10, 2025



In this paper, we present synthetic data generation framework for flood hazard detection system. For high fidelity and quality, we characterize several real-world properties into virtual world and simulate the flood situation by controlling them. For the sake of efficiency, recent generative models in image-to-3D and urban city synthesis are leveraged to easily composite flood environments so that we avoid data bias due to the hand-crafted manner. Based on our framework, we build the flood synthetic dataset with 5 levels, dubbed MultiFloodSynth which contains rich annotation types like normal map, segmentation, 3D bounding box for a variety of downstream task. In experiments, our dataset demonstrate the enhanced performance of flood hazard detection with on-par realism compared with real dataset.
ImagePiece: Content-aware Re-tokenization for Efficient Image Recognition
Dec 21, 2024



Vision Transformers (ViTs) have achieved remarkable success in various computer vision tasks. However, ViTs have a huge computational cost due to their inherent reliance on multi-head self-attention (MHSA), prompting efforts to accelerate ViTs for practical applications. To this end, recent works aim to reduce the number of tokens, mainly focusing on how to effectively prune or merge them. Nevertheless, since ViT tokens are generated from non-overlapping grid patches, they usually do not convey sufficient semantics, making it incompatible with efficient ViTs. To address this, we propose ImagePiece, a novel re-tokenization strategy for Vision Transformers. Following the MaxMatch strategy of NLP tokenization, ImagePiece groups semantically insufficient yet locally coherent tokens until they convey meaning. This simple retokenization is highly compatible with previous token reduction methods, being able to drastically narrow down relevant tokens, enhancing the inference speed of DeiT-S by 54% (nearly 1.5$\times$ faster) while achieving a 0.39% improvement in ImageNet classification accuracy. For hyper-speed inference scenarios (with 251% acceleration), our approach surpasses other baselines by an accuracy over 8%.
Is 'Right' Right? Enhancing Object Orientation Understanding in Multimodal Language Models through Egocentric Instruction Tuning
Nov 24, 2024
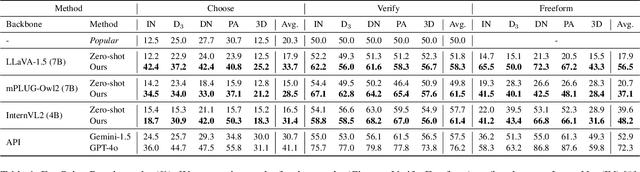

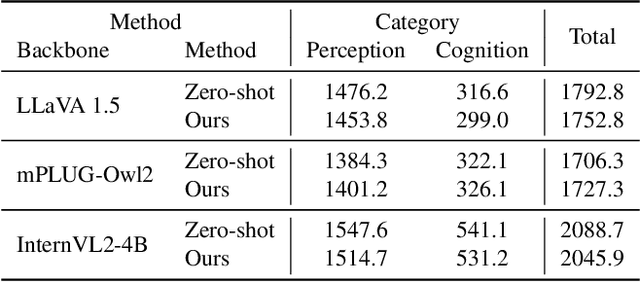
Multimodal large language models (MLLMs) act as essential interfaces, connecting humans with AI technologies in multimodal applications. However, current MLLMs face challenges in accurately interpreting object orientation in images due to inconsistent orientation annotations in training data, hindering the development of a coherent orientation understanding. To overcome this, we propose egocentric instruction tuning, which aligns MLLMs' orientation understanding with the user's perspective, based on a consistent annotation standard derived from the user's egocentric viewpoint. We first generate egocentric instruction data that leverages MLLMs' ability to recognize object details and applies prior knowledge for orientation understanding. Using this data, we perform instruction tuning to enhance the model's capability for accurate orientation interpretation. In addition, we introduce EgoOrientBench, a benchmark that evaluates MLLMs' orientation understanding across three tasks using images collected from diverse domains. Experimental results on this benchmark show that egocentric instruction tuning significantly improves orientation understanding without compromising overall MLLM performance. The instruction data and benchmark dataset are available on our project page at https://github.com/jhCOR/EgoOrientBench.
See It All: Contextualized Late Aggregation for 3D Dense Captioning
Aug 14, 2024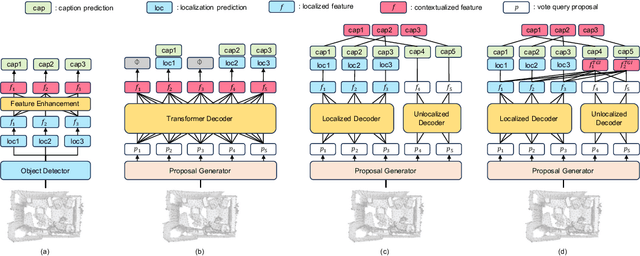
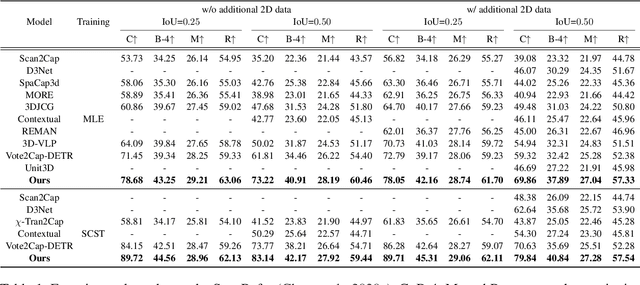
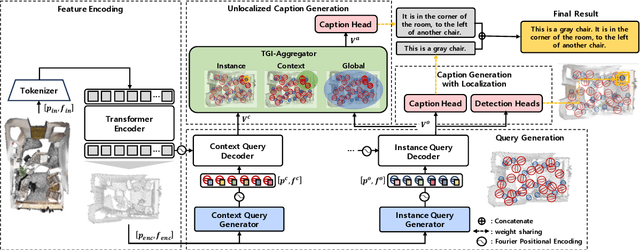
3D dense captioning is a task to localize objects in a 3D scene and generate descriptive sentences for each object. Recent approaches in 3D dense captioning have adopted transformer encoder-decoder frameworks from object detection to build an end-to-end pipeline without hand-crafted components. However, these approaches struggle with contradicting objectives where a single query attention has to simultaneously view both the tightly localized object regions and contextual environment. To overcome this challenge, we introduce SIA (See-It-All), a transformer pipeline that engages in 3D dense captioning with a novel paradigm called late aggregation. SIA simultaneously decodes two sets of queries-context query and instance query. The instance query focuses on localization and object attribute descriptions, while the context query versatilely captures the region-of-interest of relationships between multiple objects or with the global scene, then aggregated afterwards (i.e., late aggregation) via simple distance-based measures. To further enhance the quality of contextualized caption generation, we design a novel aggregator to generate a fully informed caption based on the surrounding context, the global environment, and object instances. Extensive experiments on two of the most widely-used 3D dense captioning datasets demonstrate that our proposed method achieves a significant improvement over prior methods.
Bi-directional Contextual Attention for 3D Dense Captioning
Aug 13, 2024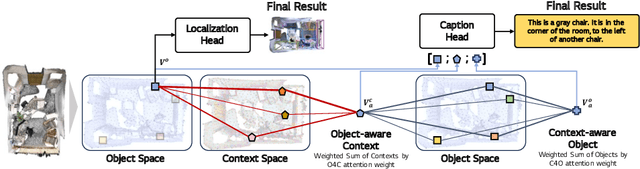
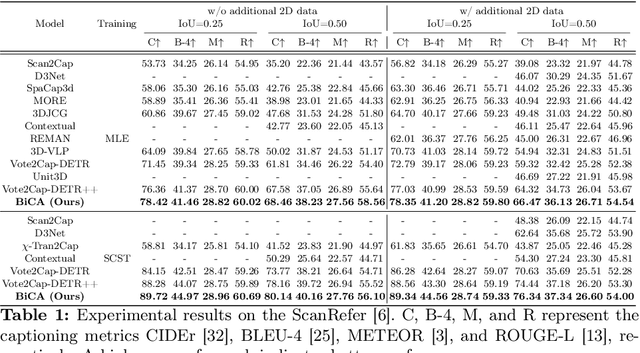
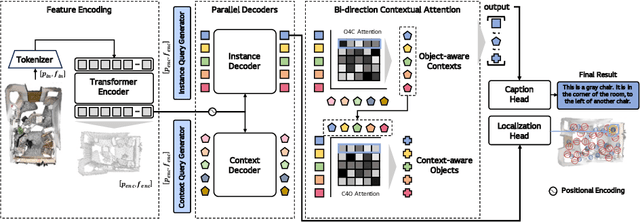
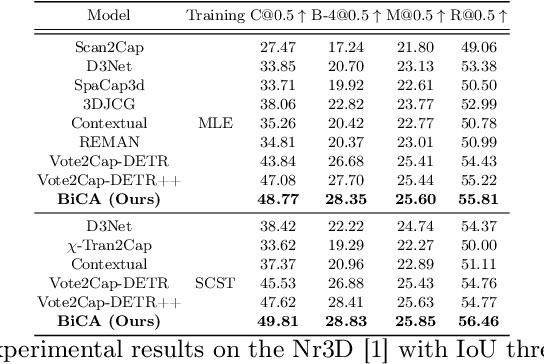
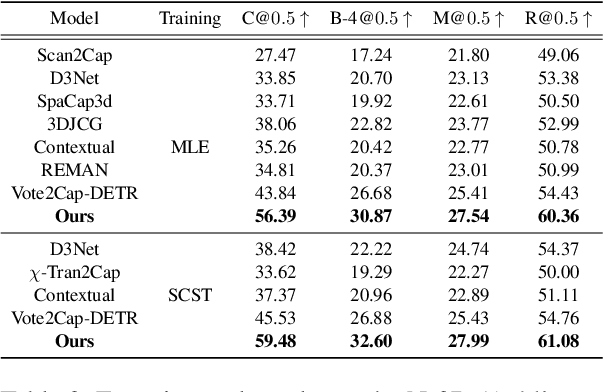
3D dense captioning is a task involving the localization of objects and the generation of descriptions for each object in a 3D scene. Recent approaches have attempted to incorporate contextual information by modeling relationships with object pairs or aggregating the nearest neighbor features of an object. However, the contextual information constructed in these scenarios is limited in two aspects: first, objects have multiple positional relationships that exist across the entire global scene, not only near the object itself. Second, it faces with contradicting objectives--where localization and attribute descriptions are generated better with tight localization, while descriptions involving global positional relations are generated better with contextualized features of the global scene. To overcome this challenge, we introduce BiCA, a transformer encoder-decoder pipeline that engages in 3D dense captioning for each object with Bi-directional Contextual Attention. Leveraging parallelly decoded instance queries for objects and context queries for non-object contexts, BiCA generates object-aware contexts, where the contexts relevant to each object is summarized, and context-aware objects, where the objects relevant to the summarized object-aware contexts are aggregated. This extension relieves previous methods from the contradicting objectives, enhancing both localization performance and enabling the aggregation of contextual features throughout the global scene; thus improving caption generation performance simultaneously. Extensive experiments on two of the most widely-used 3D dense captioning datasets demonstrate that our proposed method achieves a significant improvement over prior methods.
Cartoon Hallucinations Detection: Pose-aware In Context Visual Learning
Mar 25, 2024



Large-scale Text-to-Image (TTI) models have become a common approach for generating training data in various generative fields. However, visual hallucinations, which contain perceptually critical defects, remain a concern, especially in non-photorealistic styles like cartoon characters. We propose a novel visual hallucination detection system for cartoon character images generated by TTI models. Our approach leverages pose-aware in-context visual learning (PA-ICVL) with Vision-Language Models (VLMs), utilizing both RGB images and pose information. By incorporating pose guidance from a fine-tuned pose estimator, we enable VLMs to make more accurate decisions. Experimental results demonstrate significant improvements in identifying visual hallucinations compared to baseline methods relying solely on RGB images. This research advances TTI models by mitigating visual hallucinations, expanding their potential in non-photorealistic domains.
Minecraft-ify: Minecraft Style Image Generation with Text-guided Image Editing for In-Game Application
Feb 08, 2024



In this paper, we first present the character texture generation system \textit{Minecraft-ify}, specified to Minecraft video game toward in-game application. Ours can generate face-focused image for texture mapping tailored to 3D virtual character having cube manifold. While existing projects or works only generate texture, proposed system can inverse the user-provided real image, or generate average/random appearance from learned distribution. Moreover, it can be manipulated with text-guidance using StyleGAN and StyleCLIP. These features provide a more extended user experience with enlarged freedom as a user-friendly AI-tool. Project page can be found at https://gh-bumsookim.github.io/Minecraft-ify/
ToonAging: Face Re-Aging upon Artistic Portrait Style Transfer
Feb 05, 2024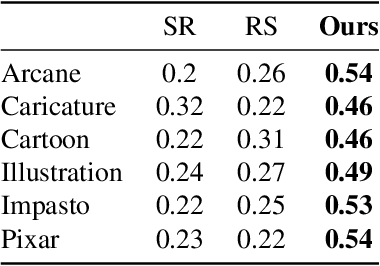

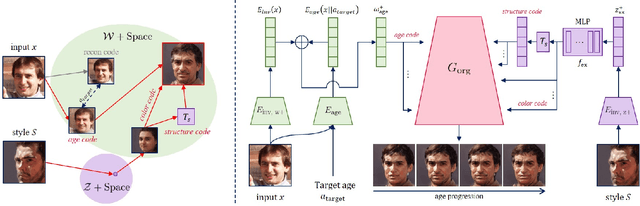
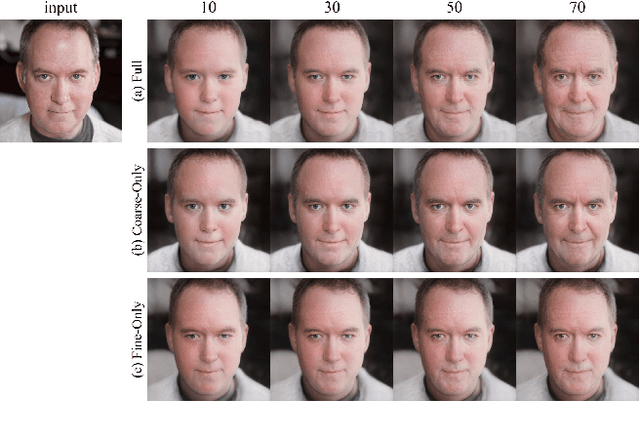
Face re-aging is a prominent field in computer vision and graphics, with significant applications in photorealistic domains such as movies, advertising, and live streaming. Recently, the need to apply face re-aging to non-photorealistic images, like comics, illustrations, and animations, has emerged as an extension in various entertainment sectors. However, the absence of a network capable of seamlessly editing the apparent age on NPR images means that these tasks have been confined to a naive approach, applying each task sequentially. This often results in unpleasant artifacts and a loss of facial attributes due to domain discrepancies. In this paper, we introduce a novel one-stage method for face re-aging combined with portrait style transfer, executed in a single generative step. We leverage existing face re-aging and style transfer networks, both trained within the same PR domain. Our method uniquely fuses distinct latent vectors, each responsible for managing aging-related attributes and NPR appearance. Adopting an exemplar-based approach, our method offers greater flexibility than domain-level fine-tuning approaches, which typically require separate training or fine-tuning for each domain. This effectively addresses the limitation of requiring paired datasets for re-aging and domain-level, data-driven approaches for stylization. Our experiments show that our model can effortlessly generate re-aged images while simultaneously transferring the style of examples, maintaining both natural appearance and controllability.
UnionDet: Union-Level Detector Towards Real-Time Human-Object Interaction Detection
Dec 19, 2023Recent advances in deep neural networks have achieved significant progress in detecting individual objects from an image. However, object detection is not sufficient to fully understand a visual scene. Towards a deeper visual understanding, the interactions between objects, especially humans and objects are essential. Most prior works have obtained this information with a bottom-up approach, where the objects are first detected and the interactions are predicted sequentially by pairing the objects. This is a major bottleneck in HOI detection inference time. To tackle this problem, we propose UnionDet, a one-stage meta-architecture for HOI detection powered by a novel union-level detector that eliminates this additional inference stage by directly capturing the region of interaction. Our one-stage detector for human-object interaction shows a significant reduction in interaction prediction time 4x~14x while outperforming state-of-the-art methods on two public datasets: V-COCO and HICO-DET.
Misalign, Contrast then Distill: Rethinking Misalignments in Language-Image Pretraining
Dec 19, 2023Contrastive Language-Image Pretraining has emerged as a prominent approach for training vision and text encoders with uncurated image-text pairs from the web. To enhance data-efficiency, recent efforts have introduced additional supervision terms that involve random-augmented views of the image. However, since the image augmentation process is unaware of its text counterpart, this procedure could cause various degrees of image-text misalignments during training. Prior methods either disregarded this discrepancy or introduced external models to mitigate the impact of misalignments during training. In contrast, we propose a novel metric learning approach that capitalizes on these misalignments as an additional training source, which we term "Misalign, Contrast then Distill (MCD)". Unlike previous methods that treat augmented images and their text counterparts as simple positive pairs, MCD predicts the continuous scales of misalignment caused by the augmentation. Our extensive experimental results show that our proposed MCD achieves state-of-the-art transferability in multiple classification and retrieval downstream datasets.