 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-directional Contextual Attention for 3D Dense Captioning
Paper and Code
Aug 13, 2024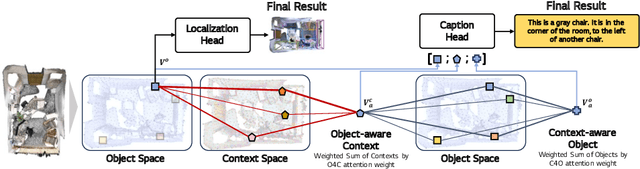
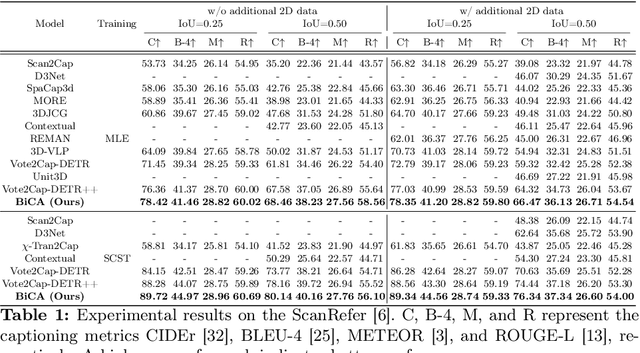
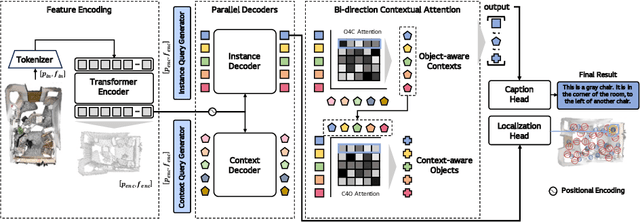
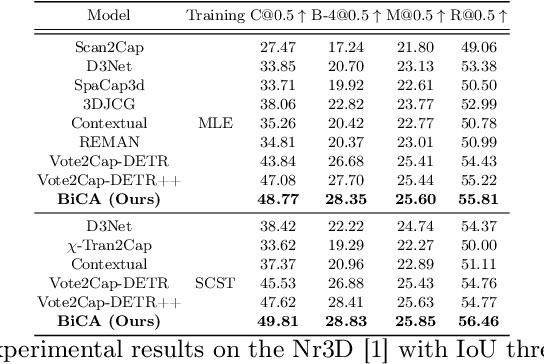
3D dense captioning is a task involving the localization of objects and the generation of descriptions for each object in a 3D scene. Recent approaches have attempted to incorporate contextual information by modeling relationships with object pairs or aggregating the nearest neighbor features of an object. However, the contextual information constructed in these scenarios is limited in two aspects: first, objects have multiple positional relationships that exist across the entire global scene, not only near the object itself. Second, it faces with contradicting objectives--where localization and attribute descriptions are generated better with tight localization, while descriptions involving global positional relations are generated better with contextualized features of the global scene. To overcome this challenge, we introduce BiCA, a transformer encoder-decoder pipeline that engages in 3D dense captioning for each object with Bi-directional Contextual Attention. Leveraging parallelly decoded instance queries for objects and context queries for non-object contexts, BiCA generates object-aware contexts, where the contexts relevant to each object is summarized, and context-aware objects, where the objects relevant to the summarized object-aware contexts are aggregated. This extension relieves previous methods from the contradicting objectives, enhancing both localization performance and enabling the aggregation of contextual features throughout the global scene; thus improving caption generation performance simultaneously. Extensive experiments on two of the most widely-used 3D dense captioning datasets demonstrate that our proposed method achieves a significant improvement over prior methods.