 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Weakly-Supervised Video Scene Graph Generation via Pair Affinity Learning
Mar 23, 2026Weakly-supervised video scene graph generation (WS-VSGG) aims to parse video content into structured relational triplets without bounding box annotations and with only sparse temporal labeling, significantly reducing annotation costs. Without ground-truth bounding boxes, these methods rely on off-the-shelf detectors to generate object proposals, yet largely overlook a fundamental discrepancy from fullysupervised pipelines. Fully-supervised detectors implicitly filter out noninteractive objects, while off-the-shelf detectors indiscriminately detect all visible objects, overwhelming relation models with noisy pairs.We address this by introducing a learnable pair affinity that estimates the likelihood of interaction between subject-object pairs. Through Pair Affinity Learning and Scoring (PALS), pair affinity is incorporated into inferencetime ranking and further integrated into contextual reasoning through Pair Affinity Modulation (PAM), enabling the model to suppress noninteractive pairs and focus on relationally meaningful ones. To provide cleaner supervision for pair affinity learning, we further propose Relation- Aware Matching (RAM), which leverages vision-language grounding to resolve class-level ambiguity in pseudo-label generation. Extensive experiments on Action Genome demonstrate that our approach consistently yields substantial improvements across different baselines and backbones, achieving state-of-the-art WS-VSGG performance.
MAPLE: Modality-Aware Post-training and Learning Ecosystem
Feb 12, 2026Multimodal language models now integrate text, audio, and video for unified reasoning. Yet existing RL post-training pipelines treat all input signals as equally relevant, ignoring which modalities each task actually requires. This modality-blind training inflates policy-gradient variance, slows convergence, and degrades robustness to real-world distribution shifts where signals may be missing, added, or reweighted. We introduce MAPLE, a complete modality-aware post-training and learning ecosystem comprising: (1) MAPLE-bench, the first benchmark explicitly annotating minimal signal combinations required per task; (2) MAPO, a modality-aware policy optimization framework that stratifies batches by modality requirement to reduce gradient variance from heterogeneous group advantages; (3) Adaptive weighting and curriculum scheduling that balances and prioritizes harder signal combinations. Systematic analysis across loss aggregation, clipping, sampling, and curriculum design establishes MAPO's optimal training strategy. Adaptive weighting and curriculum focused learning further boost performance across signal combinations. MAPLE narrows uni/multi-modal accuracy gaps by 30.24%, converges 3.18x faster, and maintains stability across all modality combinations under realistic reduced signal access. MAPLE constitutes a complete recipe for deployment-ready multimodal RL post-training.
Possibility for Proactive Anomaly Detection
Apr 15, 2025Time-series anomaly detection, which detects errors and failures in a workflow, is one of the most important topics in real-world applications. The purpose of time-series anomaly detection is to reduce potential damages or losses. However, existing anomaly detection models detect anomalies through the error between the model output and the ground truth (observed) value, which makes them impractical. In this work, we present a \textit{proactive} approach for time-series anomaly detection based on a time-series forecasting model specialized for anomaly detection and a data-driven anomaly detection model. Our proactive approach establishes an anomaly threshold from training data with a data-driven anomaly detection model, and anomalies are subsequently detected by identifying predicted values that exceed the anomaly threshold. In addition, we extensively evaluated the model using four anomaly detection benchmarks and analyzed both predictable and unpredictable anomalies. We attached the source code as supplementary material.
Neural Fourier Modelling: A Highly Compact Approach to Time-Series Analysis
Oct 07, 2024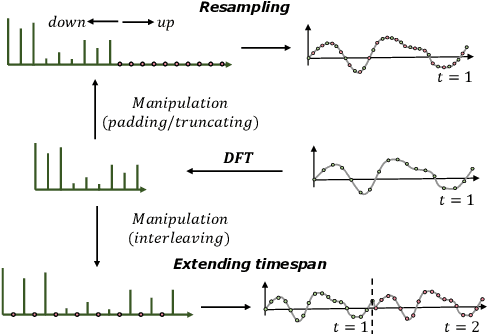
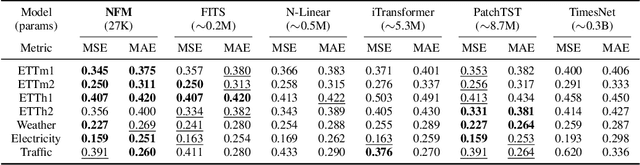
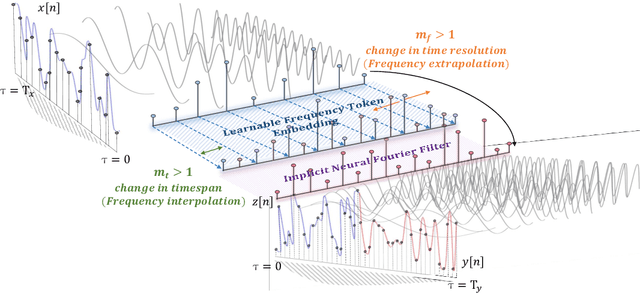
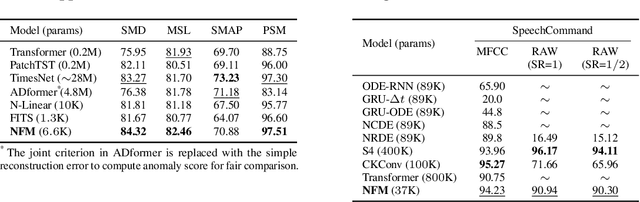
Neural time-series analysis has traditionally focused on modeling data in the time domain, often with some approaches incorporating equivalent Fourier domain representations as auxiliary spectral features. In this work, we shift the main focus to frequency representations, modeling time-series data fully and directly in the Fourier domain. We introduce Neural Fourier Modelling (NFM), a compact yet powerful solution for time-series analysis. NFM is grounded in two key properties of the Fourier transform (FT): (i) the ability to model finite-length time series as functions in the Fourier domain, treating them as continuous-time elements in function space, and (ii) the capacity for data manipulation (such as resampling and timespan extension) within the Fourier domain. We reinterpret Fourier-domain data manipulation as frequency extrapolation and interpolation, incorporating this as a core learning mechanism in NFM, applicable across various tasks. To support flexible frequency extension with spectral priors and effective modulation of frequency representations, we propose two learning modules: Learnable Frequency Tokens (LFT) and Implicit Neural Fourier Filters (INFF). These modules enable compact and expressive modeling in the Fourier domain. Extensive experiments demonstrate that NFM achieves state-of-the-art performance on a wide range of tasks (forecasting, anomaly detection, and classification), including challenging time-series scenarios with previously unseen sampling rates at test time. Moreover, NFM is highly compact, requiring fewer than 40K parameters in each task, with time-series lengths ranging from 100 to 16K.
See It All: Contextualized Late Aggregation for 3D Dense Captioning
Aug 14, 2024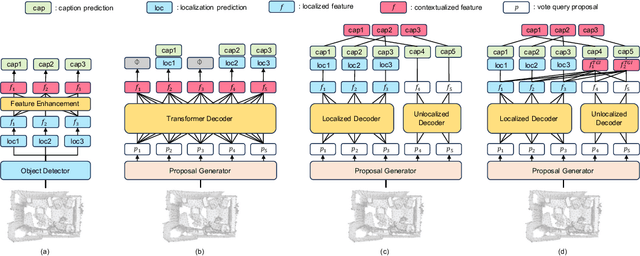
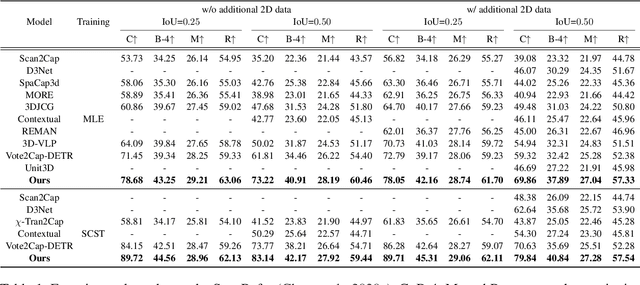
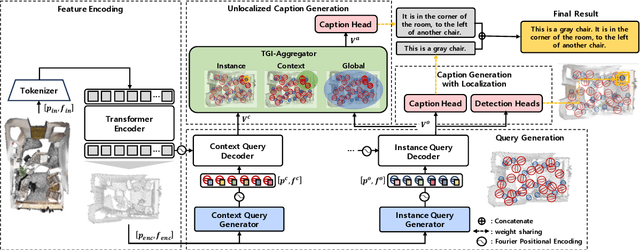
3D dense captioning is a task to localize objects in a 3D scene and generate descriptive sentences for each object. Recent approaches in 3D dense captioning have adopted transformer encoder-decoder frameworks from object detection to build an end-to-end pipeline without hand-crafted components. However, these approaches struggle with contradicting objectives where a single query attention has to simultaneously view both the tightly localized object regions and contextual environment. To overcome this challenge, we introduce SIA (See-It-All), a transformer pipeline that engages in 3D dense captioning with a novel paradigm called late aggregation. SIA simultaneously decodes two sets of queries-context query and instance query. The instance query focuses on localization and object attribute descriptions, while the context query versatilely captures the region-of-interest of relationships between multiple objects or with the global scene, then aggregated afterwards (i.e., late aggregation) via simple distance-based measures. To further enhance the quality of contextualized caption generation, we design a novel aggregator to generate a fully informed caption based on the surrounding context, the global environment, and object instances. Extensive experiments on two of the most widely-used 3D dense captioning datasets demonstrate that our proposed method achieves a significant improvement over prior methods.
Bi-directional Contextual Attention for 3D Dense Captioning
Aug 13, 2024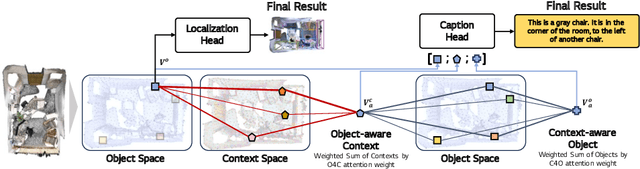
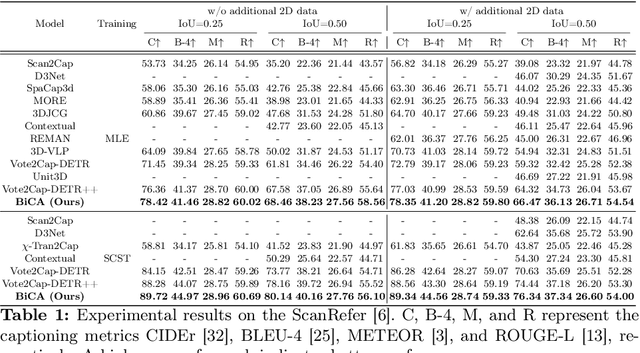
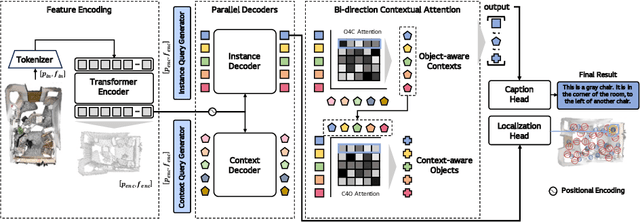
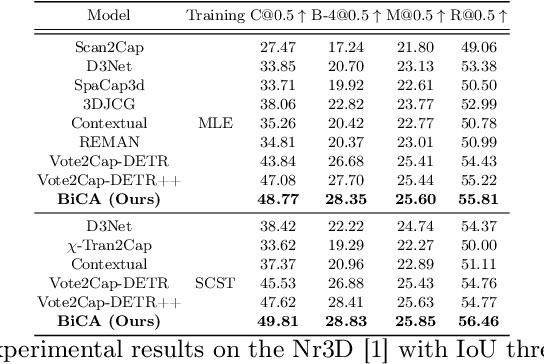
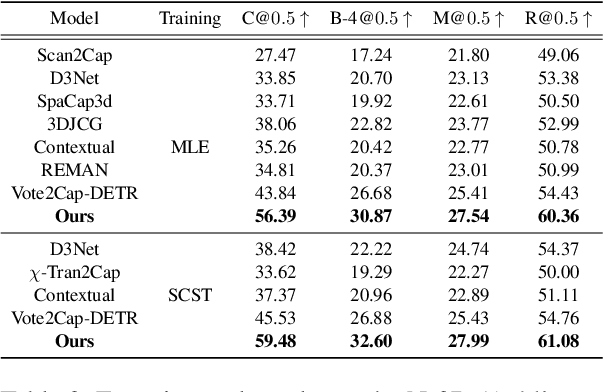
3D dense captioning is a task involving the localization of objects and the generation of descriptions for each object in a 3D scene. Recent approaches have attempted to incorporate contextual information by modeling relationships with object pairs or aggregating the nearest neighbor features of an object. However, the contextual information constructed in these scenarios is limited in two aspects: first, objects have multiple positional relationships that exist across the entire global scene, not only near the object itself. Second, it faces with contradicting objectives--where localization and attribute descriptions are generated better with tight localization, while descriptions involving global positional relations are generated better with contextualized features of the global scene. To overcome this challenge, we introduce BiCA, a transformer encoder-decoder pipeline that engages in 3D dense captioning for each object with Bi-directional Contextual Attention. Leveraging parallelly decoded instance queries for objects and context queries for non-object contexts, BiCA generates object-aware contexts, where the contexts relevant to each object is summarized, and context-aware objects, where the objects relevant to the summarized object-aware contexts are aggregated. This extension relieves previous methods from the contradicting objectives, enhancing both localization performance and enabling the aggregation of contextual features throughout the global scene; thus improving caption generation performance simultaneously. Extensive experiments on two of the most widely-used 3D dense captioning datasets demonstrate that our proposed method achieves a significant improvement over prior methods.
FIMP: Future Interaction Modeling for Multi-Agent Motion Prediction
Jan 29, 2024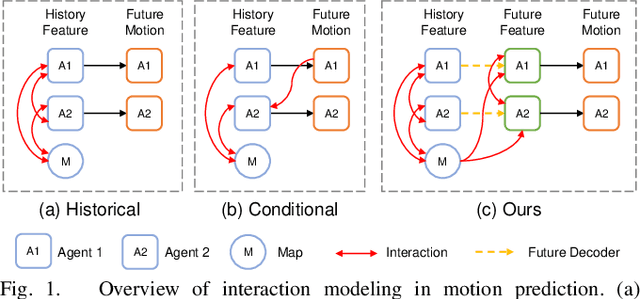
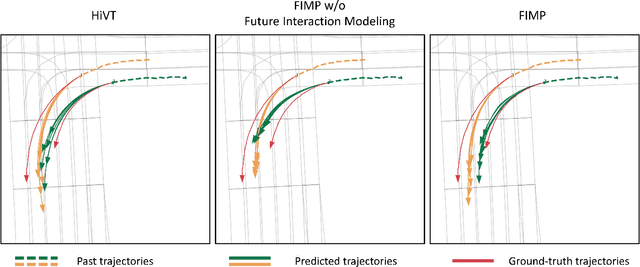
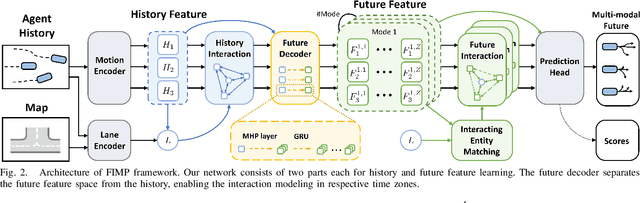
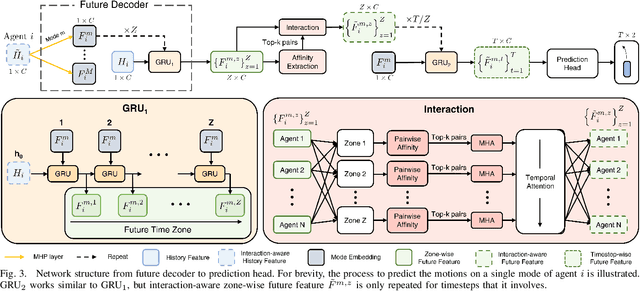
Multi-agent motion prediction is a crucial concern in autonomous driving, yet it remains a challenge owing to the ambiguous intentions of dynamic agents and their intricate interactions. Existing studies have attempted to capture interactions between road entities by using the definite data in history timesteps, as future information is not available and involves high uncertainty. However, without sufficient guidance for capturing future states of interacting agents, they frequently produce unrealistic trajectory overlaps. In this work, we propose Future Interaction modeling for Motion Prediction (FIMP), which captures potential future interactions in an end-to-end manner. FIMP adopts a future decoder that implicitly extracts the potential future information in an intermediate feature-level, and identifies the interacting entity pairs through future affinity learning and top-k filtering strategy. Experiments show that our future interaction modeling improves the performance remarkably, leading to superior performance on the Argoverse motion forecasting benchmark.
EP2P-Loc: End-to-End 3D Point to 2D Pixel Localization for Large-Scale Visual Localization
Sep 14, 2023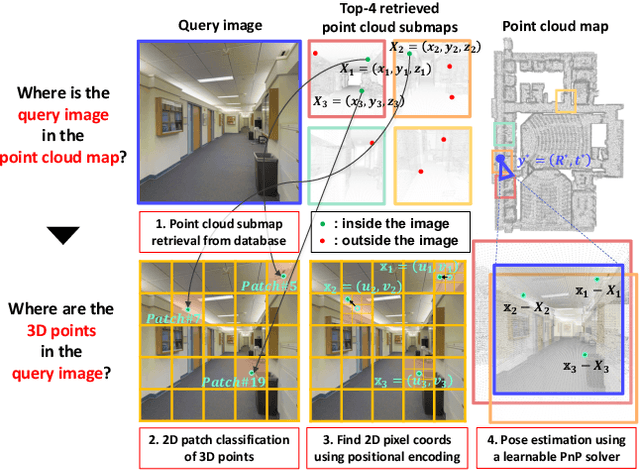
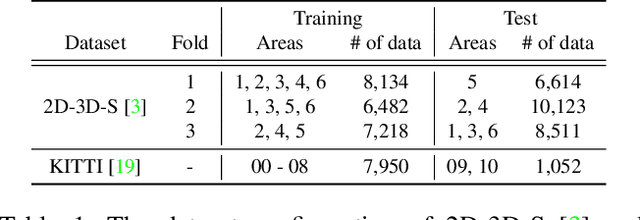
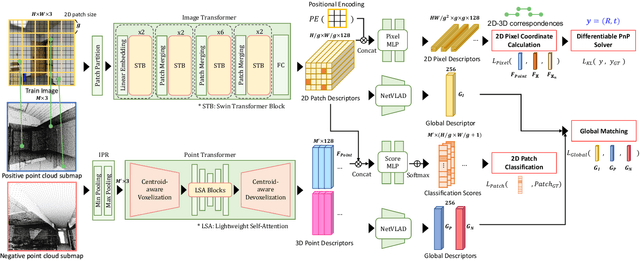
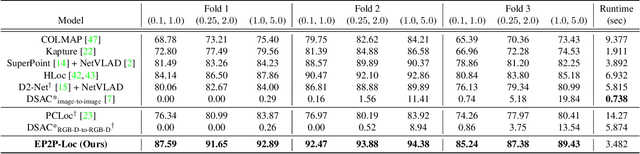
Visual localization is the task of estimating a 6-DoF camera pose of a query image within a provided 3D reference map. Thanks to recent advances in various 3D sensors, 3D point clouds are becoming a more accurate and affordable option for building the reference map, but research to match the points of 3D point clouds with pixels in 2D images for visual localization remains challenging. Existing approaches that jointly learn 2D-3D feature matching suffer from low inliers due to representational differences between the two modalities, and the methods that bypass this problem into classification have an issue of poor refinement. In this work, we propose EP2P-Loc, a novel large-scale visual localization method that mitigates such appearance discrepancy and enables end-to-end training for pose estimation. To increase the number of inliers, we propose a simple algorithm to remove invisible 3D points in the image, and find all 2D-3D correspondences without keypoint detection. To reduce memory usage and search complexity, we take a coarse-to-fine approach where we extract patch-level features from 2D images, then perform 2D patch classification on each 3D point, and obtain the exact corresponding 2D pixel coordinates through positional encoding. Finally, for the first time in this task, we employ a differentiable PnP for end-to-end training. In the experiments on newly curated large-scale indoor and outdoor benchmarks based on 2D-3D-S and KITTI, we show that our method achieves the state-of-the-art performance compared to existing visual localization and image-to-point cloud registration methods.
MadSGM: Multivariate Anomaly Detection with Score-based Generative Models
Aug 29, 2023

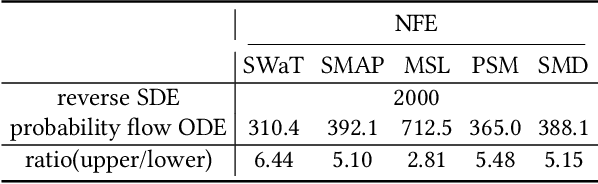
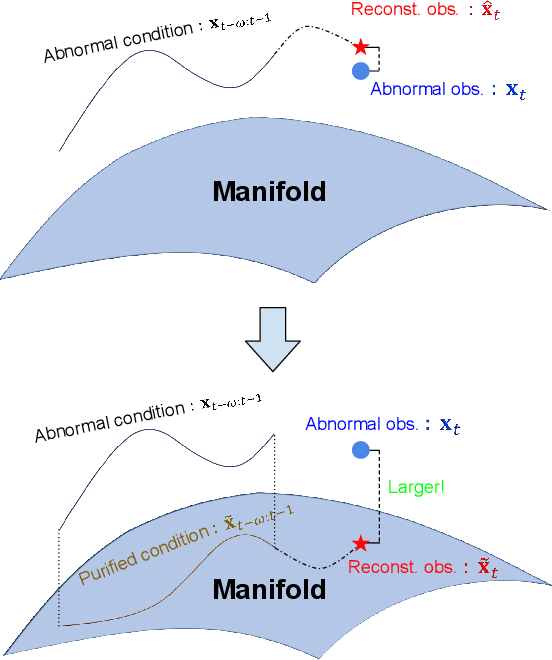
The time-series anomaly detection is one of the most fundamental tasks for time-series. Unlike the time-series forecasting and classification, the time-series anomaly detection typically requires unsupervised (or self-supervised) training since collecting and labeling anomalous observations are difficult. In addition, most existing methods resort to limited forms of anomaly measurements and therefore, it is not clear whether they are optimal in all circumstances. To this end, we present a multivariate time-series anomaly detector based on score-based generative models, called MadSGM, which considers the broadest ever set of anomaly measurement factors: i) reconstruction-based, ii) density-based, and iii) gradient-based anomaly measurements. We also design a conditional score network and its denoising score matching loss for the time-series anomaly detection. Experiments on five real-world benchmark datasets illustrate that MadSGM achieves the most robust and accurate predictions.
Regular Time-series Generation using SGM
Jan 20, 2023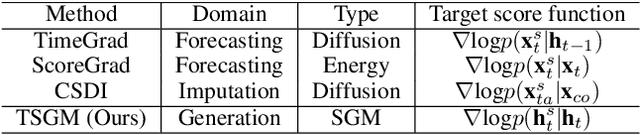
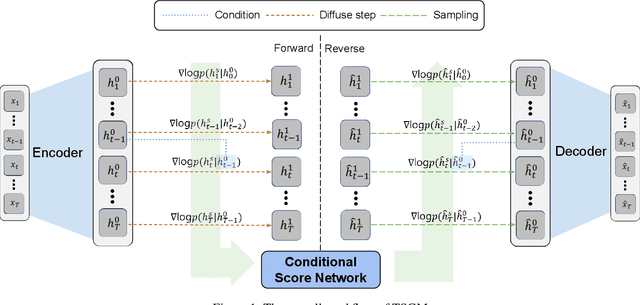
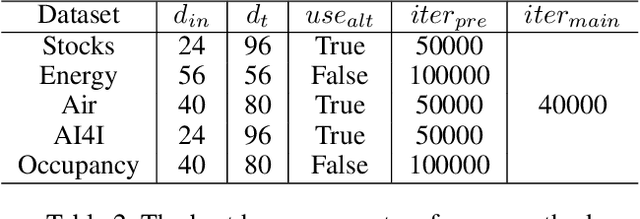
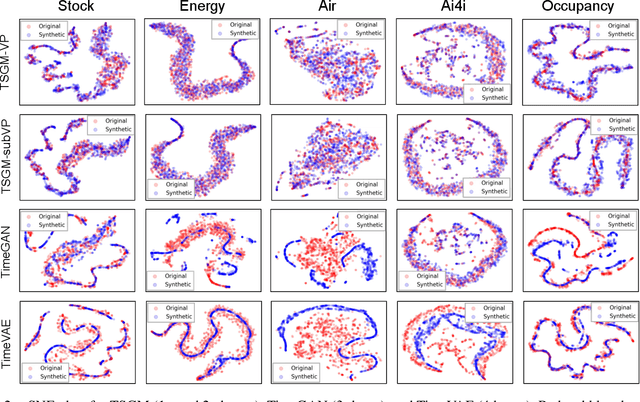
Score-based generative models (SGMs) are generative models that are in the spotlight these days. Time-series frequently occurs in our daily life, e.g., stock data, climate data, and so on. Especially, time-series forecasting and classification are popular research topics in the field of machine learning. SGMs are also known for outperforming other generative models. As a result, we apply SGMs to synthesize time-series data by learning conditional score functions. We propose a conditional score network for the time-series generation domain. Furthermore, we also derive the loss function between the score matching and the denoising score matching in the time-series generation domain. Finally, we achieve state-of-the-art results on real-world datasets in terms of sampling diversity and quality.