 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIMP: Future Interaction Modeling for Multi-Agent Motion Prediction
Jan 29, 2024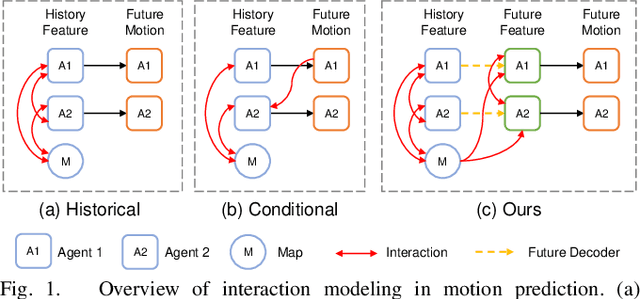
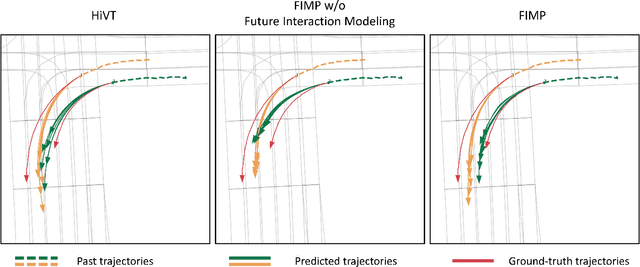
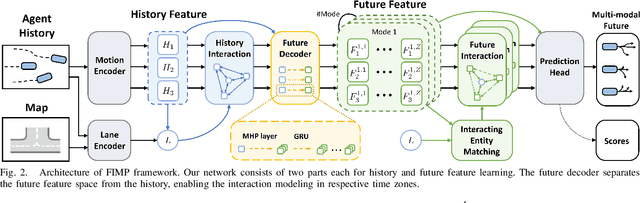
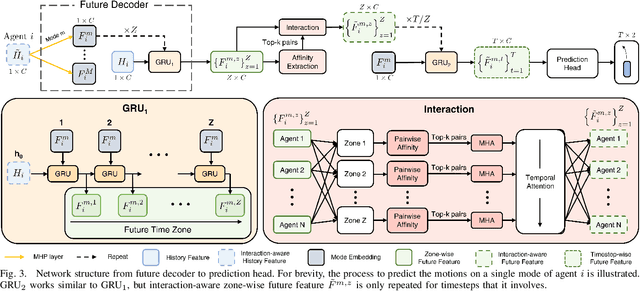
Multi-agent motion prediction is a crucial concern in autonomous driving, yet it remains a challenge owing to the ambiguous intentions of dynamic agents and their intricate interactions. Existing studies have attempted to capture interactions between road entities by using the definite data in history timesteps, as future information is not available and involves high uncertainty. However, without sufficient guidance for capturing future states of interacting agents, they frequently produce unrealistic trajectory overlaps. In this work, we propose Future Interaction modeling for Motion Prediction (FIMP), which captures potential future interactions in an end-to-end manner. FIMP adopts a future decoder that implicitly extracts the potential future information in an intermediate feature-level, and identifies the interacting entity pairs through future affinity learning and top-k filtering strategy. Experiments show that our future interaction modeling improves the performance remarkably, leading to superior performance on the Argoverse motion forecasting benchmark.
Tackling Background Distraction in Video Object Segmentation
Jul 14, 2022Semi-supervised video object segmentation (VOS) aims to densely track certain designated objects in videos. One of the main challenges in this task is the existence of background distractors that appear similar to the target objects. We propose three novel strategies to suppress such distractors: 1) a spatio-temporally diversified template construction scheme to obtain generalized properties of the target objects; 2) a learnable distance-scoring function to exclude spatially-distant distractors by exploiting the temporal consistency between two consecutive frames; 3) swap-and-attach augmentation to force each object to have unique features by providing training samples containing entangled objects. On all public benchmark datasets, our model achieves a comparable performance to contemporary state-of-the-art approaches, even with real-time performance. Qualitative results also demonstrate the superiority of our approach over existing methods. We believe our approach will be widely used for future VOS research.
Pixel-Level Bijective Matching for Video Object Segmentation
Oct 04, 2021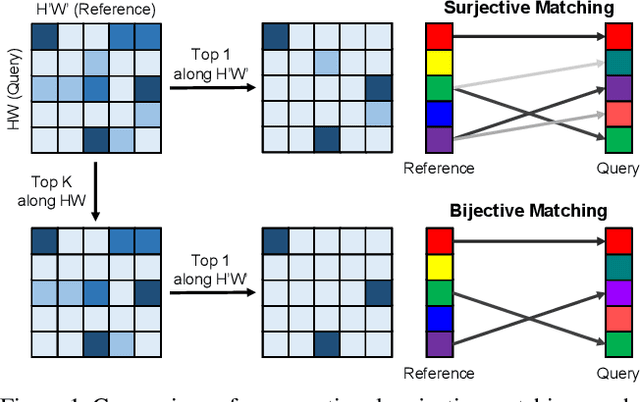
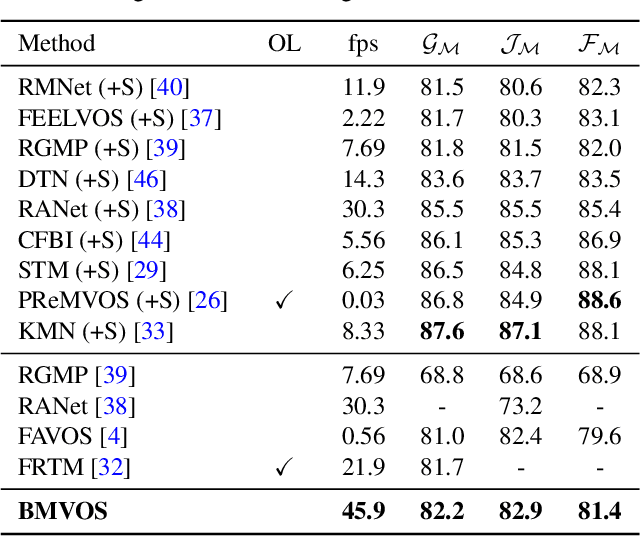
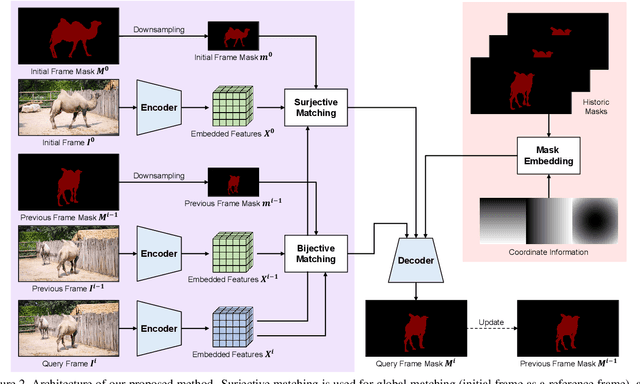
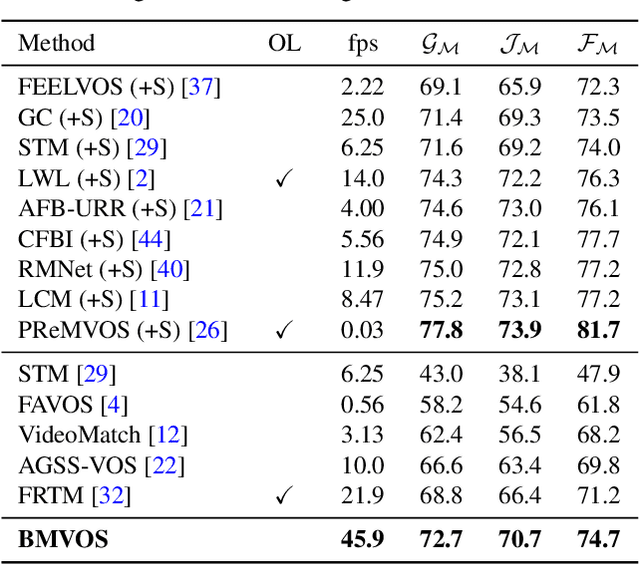
Semi-supervised video object segmentation (VOS) aims to track the designated objects present in the initial frame of a video at the pixel level. To fully exploit the appearance information of an object, pixel-level feature matching is widely used in VOS. Conventional feature matching runs in a surjective manner, i.e., only the best matches from the query frame to the reference frame are considered. Each location in the query frame refers to the optimal location in the reference frame regardless of how often each reference frame location is referenced. This works well in most cases and is robust against rapid appearance variations, but may cause critical errors when the query frame contains background distractors that look similar to the target object. To mitigate this concern, we introduce a bijective matching mechanism to find the best matches from the query frame to the reference frame and vice versa. Before finding the best matches for the query frame pixels, the optimal matches for the reference frame pixels are first considered to prevent each reference frame pixel from being overly referenced. As this mechanism operates in a strict manner, i.e., pixels are connected if and only if they are the sure matches for each other, it can effectively eliminate background distractors. In addition, we propose a mask embedding module to improve the existing mask propagation method. By embedding multiple historic masks with coordinate information, it can effectively capture the position information of a target object.
PMVOS: Pixel-Level Matching-Based Video Object Segmentation
Sep 18, 2020Semi-supervised video object segmentation (VOS) aims to segment arbitrary target objects in video when the ground truth segmentation mask of the initial frame is provided. Due to this limitation of using prior knowledge about the target object, feature matching, which compares template features representing the target object with input features, is an essential step. Recently, pixel-level matching (PM), which matches every pixel in template features and input features, has been widely used for feature matching because of its high performance. However, despite its effectiveness, the information used to build the template features is limited to the initial and previous frames. We address this issue by proposing a novel method-PM-based video object segmentation (PMVOS)-that constructs strong template features containing the information of all past frames. Furthermore, we apply self-attention to the similarity maps generated from PM to capture global dependencies. On the DAVIS 2016 validation set, we achieve new state-of-the-art performance among real-time methods (> 30 fps), with a J&F score of 85.6%. Performance on the DAVIS 2017 and YouTube-VOS validation sets is also impressive, with J&F scores of 74.0% and 68.2%, respectively.