 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccluded Person Re-Identification via Relational Adaptive Feature Correction Learning
Dec 09, 2022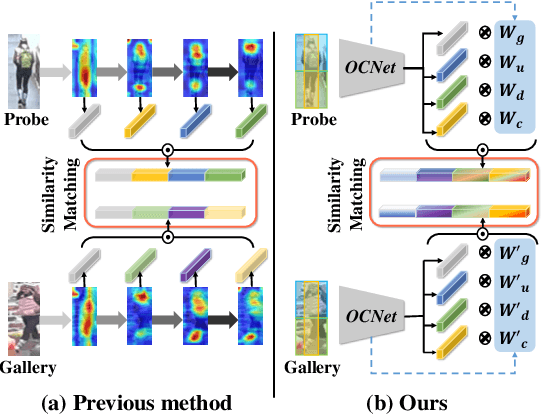
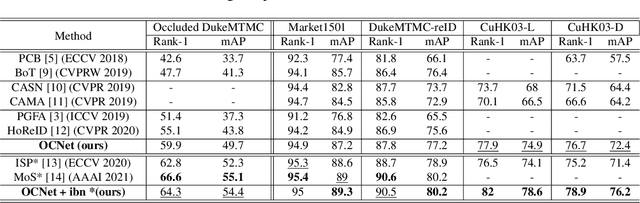
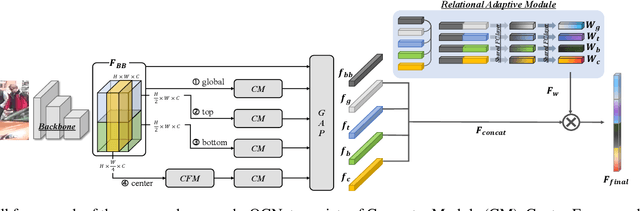

Occluded person re-identification (Re-ID) in images captured by multiple cameras is challenging because the target person is occluded by pedestrians or objects, especially in crowded scenes. In addition to the processes performed during holistic person Re-ID, occluded person Re-ID involves the removal of obstacles and the detection of partially visible body parts. Most existing methods utilize the off-the-shelf pose or parsing networks as pseudo labels, which are prone to error. To address these issues, we propose a novel Occlusion Correction Network (OCNet) that corrects features through relational-weight learning and obtains diverse and representative features without using external networks. In addition, we present a simple concept of a center feature in order to provide an intuitive solution to pedestrian occlusion scenarios. Furthermore, we suggest the idea of Separation Loss (SL) for focusing on different parts between global features and part features. We conduct extensive experiments on five challenging benchmark datasets for occluded and holistic Re-ID tasks to demonstrate that our method achieves superior performance to state-of-the-art methods especially on occluded scene.
Tackling Background Distraction in Video Object Segmentation
Jul 14, 2022Semi-supervised video object segmentation (VOS) aims to densely track certain designated objects in videos. One of the main challenges in this task is the existence of background distractors that appear similar to the target objects. We propose three novel strategies to suppress such distractors: 1) a spatio-temporally diversified template construction scheme to obtain generalized properties of the target objects; 2) a learnable distance-scoring function to exclude spatially-distant distractors by exploiting the temporal consistency between two consecutive frames; 3) swap-and-attach augmentation to force each object to have unique features by providing training samples containing entangled objects. On all public benchmark datasets, our model achieves a comparable performance to contemporary state-of-the-art approaches, even with real-time performance. Qualitative results also demonstrate the superiority of our approach over existing methods. We believe our approach will be widely used for future VOS research.
Pixel-Level Bijective Matching for Video Object Segmentation
Oct 04, 2021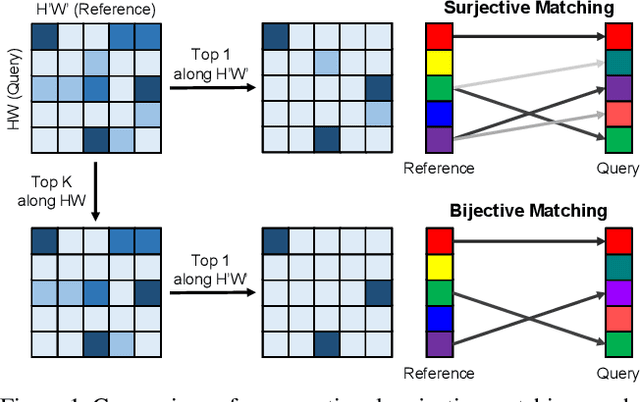
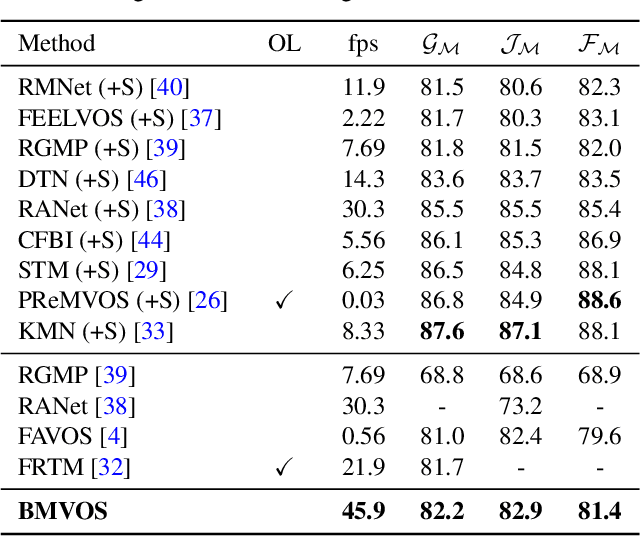
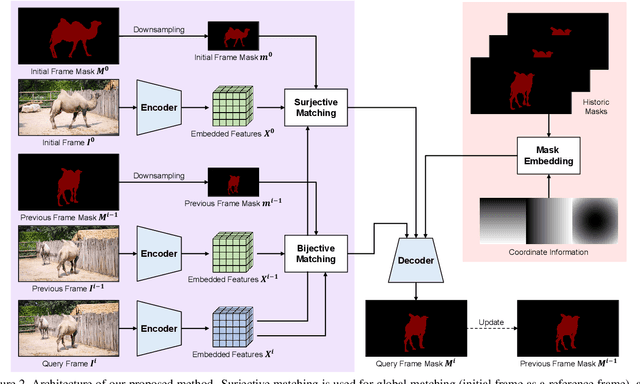
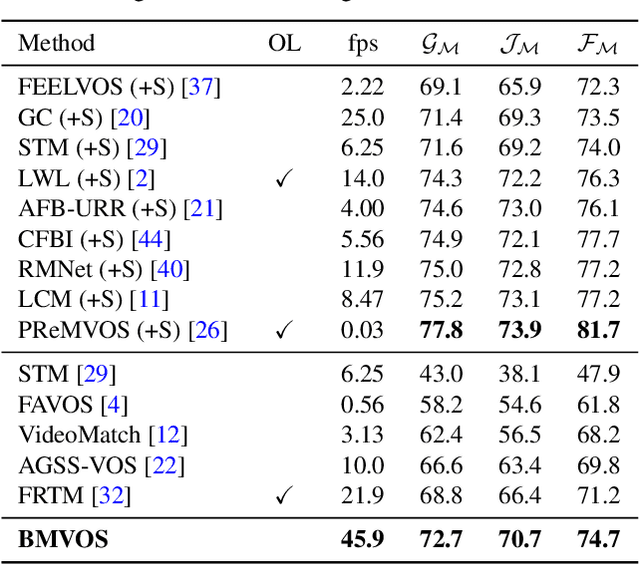
Semi-supervised video object segmentation (VOS) aims to track the designated objects present in the initial frame of a video at the pixel level. To fully exploit the appearance information of an object, pixel-level feature matching is widely used in VOS. Conventional feature matching runs in a surjective manner, i.e., only the best matches from the query frame to the reference frame are considered. Each location in the query frame refers to the optimal location in the reference frame regardless of how often each reference frame location is referenced. This works well in most cases and is robust against rapid appearance variations, but may cause critical errors when the query frame contains background distractors that look similar to the target object. To mitigate this concern, we introduce a bijective matching mechanism to find the best matches from the query frame to the reference frame and vice versa. Before finding the best matches for the query frame pixels, the optimal matches for the reference frame pixels are first considered to prevent each reference frame pixel from being overly referenced. As this mechanism operates in a strict manner, i.e., pixels are connected if and only if they are the sure matches for each other, it can effectively eliminate background distractors. In addition, we propose a mask embedding module to improve the existing mask propagation method. By embedding multiple historic masks with coordinate information, it can effectively capture the position information of a target object.
Multi-object tracking with self-supervised associating network
Oct 26, 2020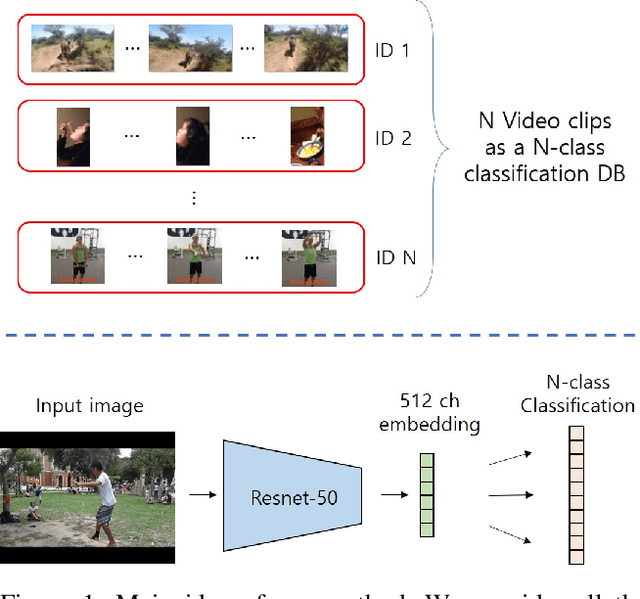
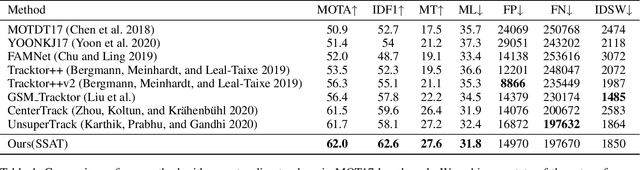
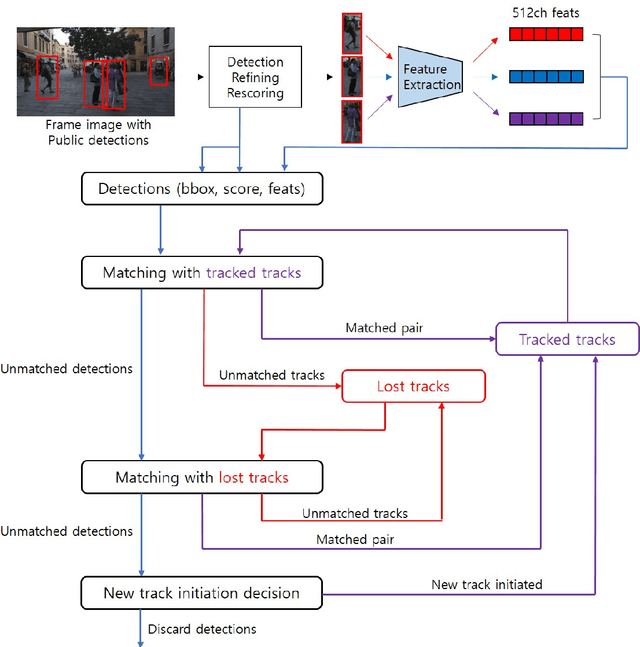
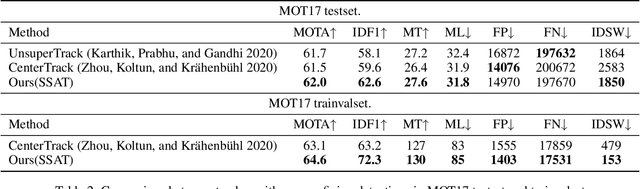
Multi-Object Tracking (MOT) is the task that has a lot of potential for development, and there are still many problems to be solved. In the traditional tracking by detection paradigm, There has been a lot of work on feature based object re-identification methods. However, this method has a lack of training data problem. For labeling multi-object tracking dataset, every detection in a video sequence need its location and IDs. Since assigning consecutive IDs to each detection in every sequence is a very labor-intensive task, current multi-object tracking dataset is not sufficient enough to train re-identification network. So in this paper, we propose a novel self-supervised learning method using a lot of short videos which has no human labeling, and improve the tracking performance through the re-identification network trained in the self-supervised manner to solve the lack of training data problem. Despite the re-identification network is trained in a self-supervised manner, it achieves the state-of-the-art performance of MOTA 62.0\% and IDF1 62.6\% on the MOT17 test benchmark. Furthermore, the performance is improved as much as learned with a large amount of data, it shows the potential of self-supervised method.
PMVOS: Pixel-Level Matching-Based Video Object Segmentation
Sep 18, 2020Semi-supervised video object segmentation (VOS) aims to segment arbitrary target objects in video when the ground truth segmentation mask of the initial frame is provided. Due to this limitation of using prior knowledge about the target object, feature matching, which compares template features representing the target object with input features, is an essential step. Recently, pixel-level matching (PM), which matches every pixel in template features and input features, has been widely used for feature matching because of its high performance. However, despite its effectiveness, the information used to build the template features is limited to the initial and previous frames. We address this issue by proposing a novel method-PM-based video object segmentation (PMVOS)-that constructs strong template features containing the information of all past frames. Furthermore, we apply self-attention to the similarity maps generated from PM to capture global dependencies. On the DAVIS 2016 validation set, we achieve new state-of-the-art performance among real-time methods (> 30 fps), with a J&F score of 85.6%. Performance on the DAVIS 2017 and YouTube-VOS validation sets is also impressive, with J&F scores of 74.0% and 68.2%, respectively.
CRVOS: Clue Refining Network for Video Object Segmentation
Feb 10, 2020
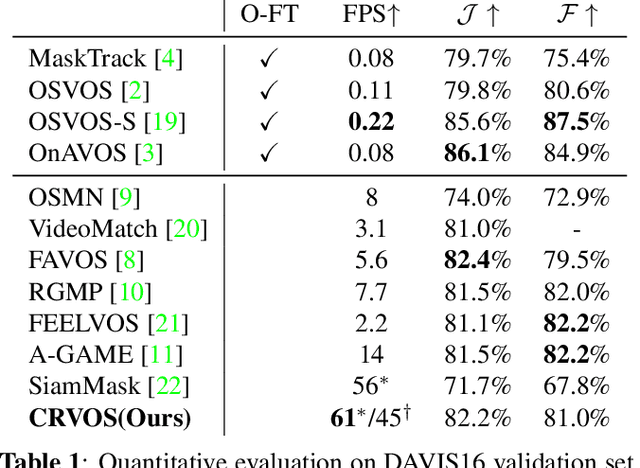
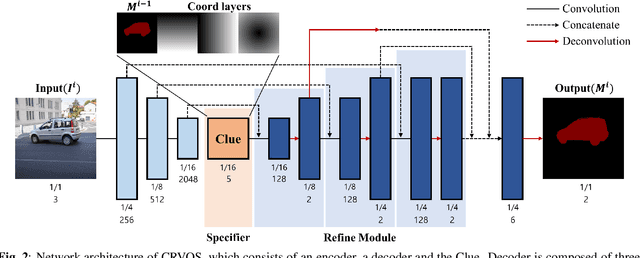
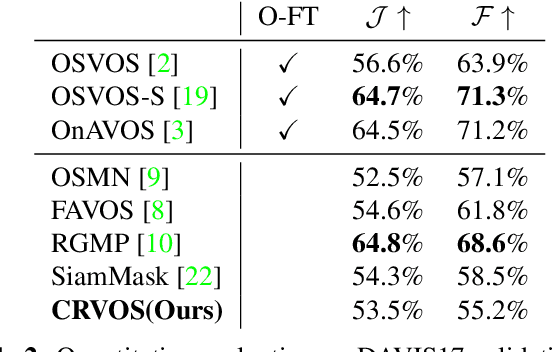
The encoder-decoder based methods for semi-supervised video object segmentation (Semi-VOS) have received extensive attentions due to their superior performances. However, most of them have complex intermediate networks which generate strong specifiers, to be robust against challenging scenarios, and this is quite inefficient when dealing with relatively simple scenarios. To solve this problem, we propose a real-time Clue Refining Network for Video Object Segmentation (CRVOS) which does not have complex intermediate network. In this work, we propose a simple specifier, referred to as the Clue, which consists of the previous frame's coarse mask and coordinates information. We also propose a novel refine module which shows higher performance than general ones by using deconvolution layer instead of bilinear upsampling. Our proposed network, CRVOS, is the fastest method with the competitive performance. On DAVIS16 validation set, CRVOS achieves 61 FPS and J&F score of 81.6%.