 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-RPN: Hard Example Learning for Region Proposal Networks
Aug 03, 2022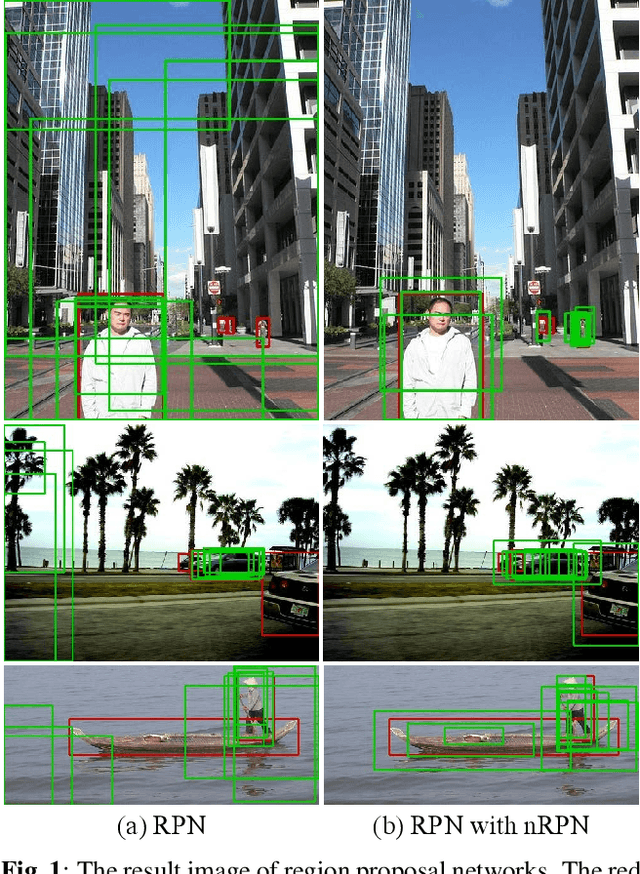

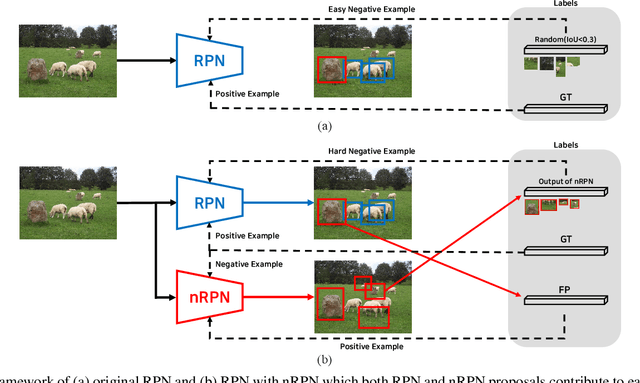
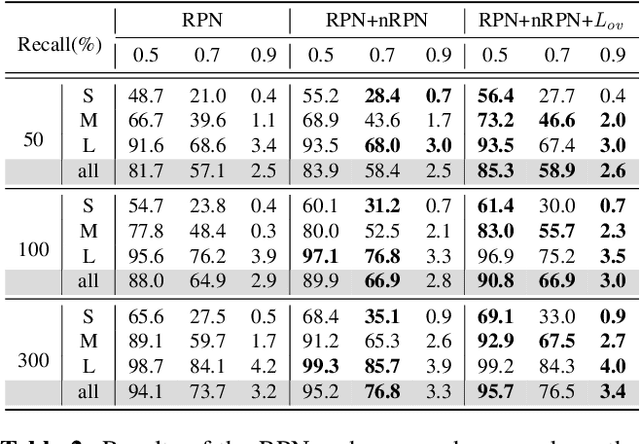
The region proposal task is to generate a set of candidate regions that contain an object. In this task, it is most important to propose as many candidates of ground-truth as possible in a fixed number of proposals. In a typical image, however, there are too few hard negative examples compared to the vast number of easy negatives, so region proposal networks struggle to train on hard negatives. Because of this problem, networks tend to propose hard negatives as candidates, while failing to propose ground-truth candidates, which leads to poor performance. In this paper, we propose a Negative Region Proposal Network(nRPN) to improve Region Proposal Network(RPN). The nRPN learns from the RPN's false positives and provide hard negative examples to the RPN. Our proposed nRPN leads to a reduction in false positives and better RPN performance. An RPN trained with an nRPN achieves performance improvements on the PASCAL VOC 2007 dataset.
Multi-object tracking with self-supervised associating network
Oct 26, 2020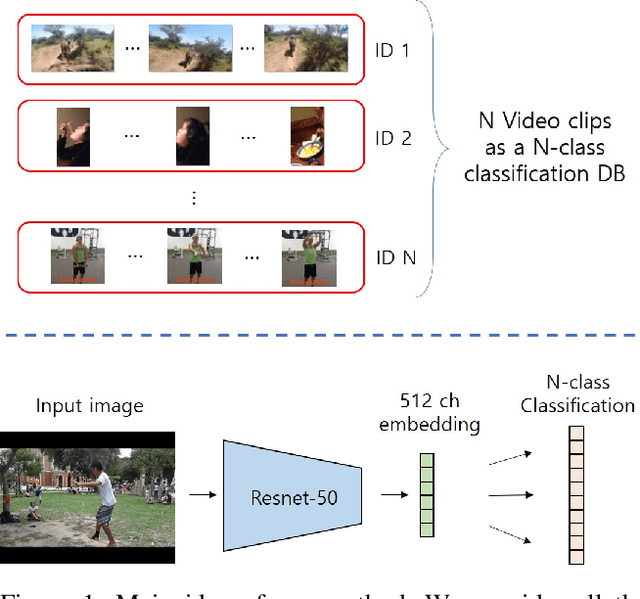
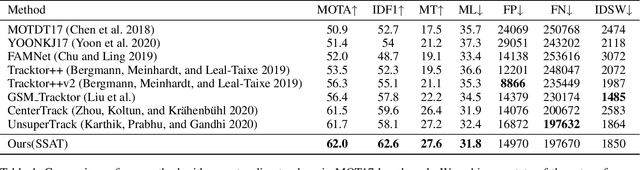
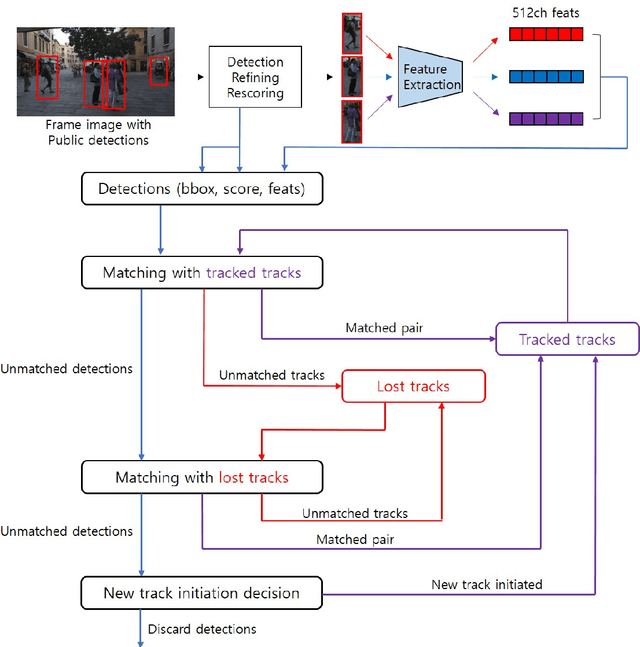
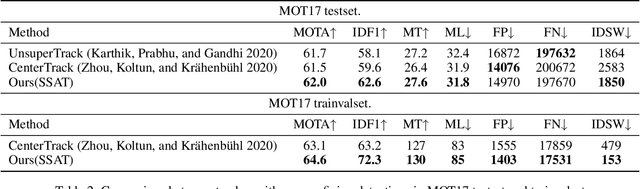
Multi-Object Tracking (MOT) is the task that has a lot of potential for development, and there are still many problems to be solved. In the traditional tracking by detection paradigm, There has been a lot of work on feature based object re-identification methods. However, this method has a lack of training data problem. For labeling multi-object tracking dataset, every detection in a video sequence need its location and IDs. Since assigning consecutive IDs to each detection in every sequence is a very labor-intensive task, current multi-object tracking dataset is not sufficient enough to train re-identification network. So in this paper, we propose a novel self-supervised learning method using a lot of short videos which has no human labeling, and improve the tracking performance through the re-identification network trained in the self-supervised manner to solve the lack of training data problem. Despite the re-identification network is trained in a self-supervised manner, it achieves the state-of-the-art performance of MOTA 62.0\% and IDF1 62.6\% on the MOT17 test benchmark. Furthermore, the performance is improved as much as learned with a large amount of data, it shows the potential of self-supervised method.
CRVOS: Clue Refining Network for Video Object Segmentation
Feb 10, 2020
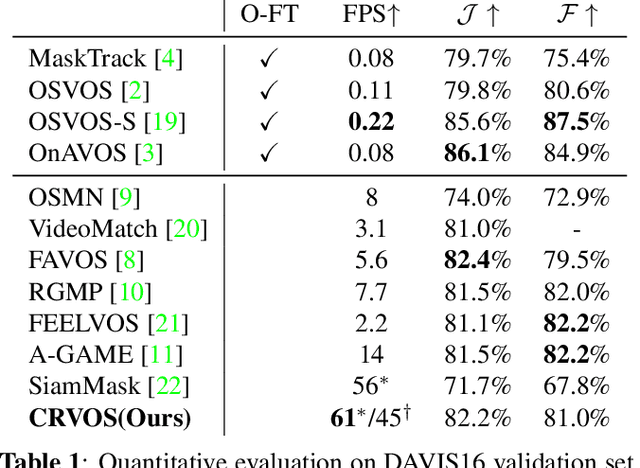
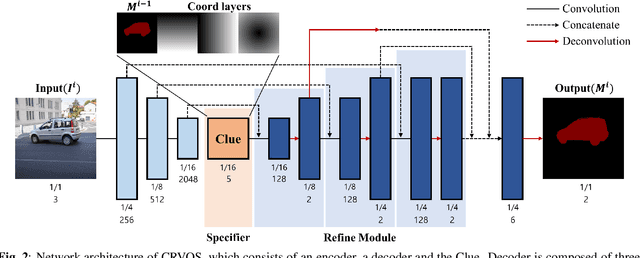
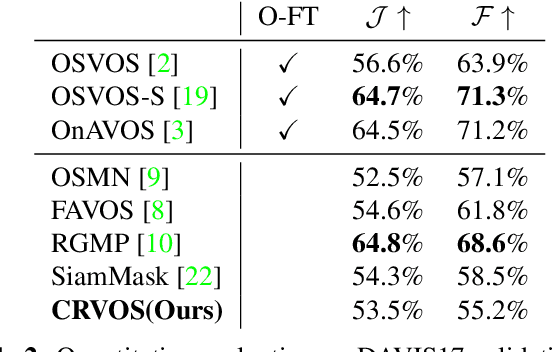
The encoder-decoder based methods for semi-supervised video object segmentation (Semi-VOS) have received extensive attentions due to their superior performances. However, most of them have complex intermediate networks which generate strong specifiers, to be robust against challenging scenarios, and this is quite inefficient when dealing with relatively simple scenarios. To solve this problem, we propose a real-time Clue Refining Network for Video Object Segmentation (CRVOS) which does not have complex intermediate network. In this work, we propose a simple specifier, referred to as the Clue, which consists of the previous frame's coarse mask and coordinates information. We also propose a novel refine module which shows higher performance than general ones by using deconvolution layer instead of bilinear upsampling. Our proposed network, CRVOS, is the fastest method with the competitive performance. On DAVIS16 validation set, CRVOS achieves 61 FPS and J&F score of 81.6%.
AD-VO: Scale-Resilient Visual Odometry Using Attentive Disparity Map
Jan 07, 2020

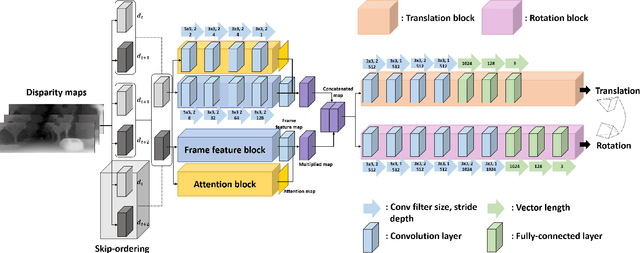
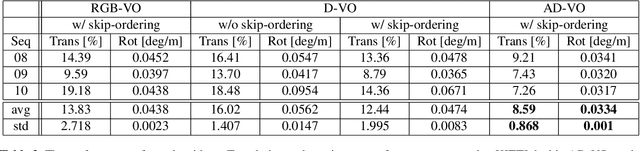
Visual odometry is an essential key for a localization module in SLAM systems. However, previous methods require tuning the system to adapt environment changes. In this paper, we propose a learning-based approach for frame-to-frame monocular visual odometry estimation. The proposed network is only learned by disparity maps for not only covering the environment changes but also solving the scale problem. Furthermore, attention block and skip-ordering scheme are introduced to achieve robust performance in various driving environment. Our network is compared with the conventional methods which use common domain such as color or optical flow. Experimental results confirm that the proposed network shows better performance than other approaches with higher and more stable results.
Learning Spatial Transform for Video Frame Interpolation
Jul 24, 2019
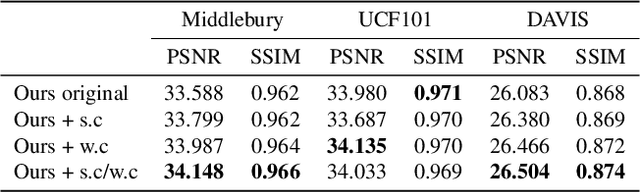
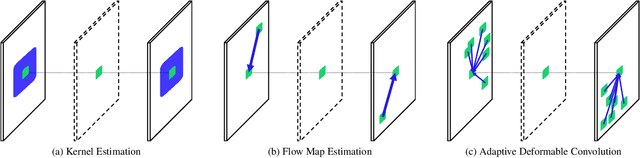
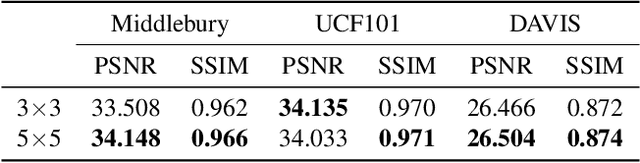
Video frame interpolation is one of the most challenging tasks in the video processing area. Recently, many related studies based on deep learning have been suggested, which can be categorized into kernel estimation and flow map estimation approaches. Most of the methods focus on finding the locations with useful information to estimate each output pixel since the information needed to estimate an intermediate frame is fully contained in the two adjacent frames. However, we redefine the task as finding the spatial transform between adjacent frames and propose a new neural network architecture that combines the two abovementioned approaches, namely Adaptive Deformable Convolution. Our method is able to estimate both kernel weights and offset vectors for each output pixel, and the output frame is synthesized by the deformable convolution operation. The experimental results show that our method outperforms the state-of-the-art methods on several datasets and that our proposed approach contributes to performance enhancement.