 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProDepth: Boosting Self-Supervised Multi-Frame Monocular Depth with Probabilistic Fusion
Jul 12, 2024



Self-supervised multi-frame monocular depth estimation relies on the geometric consistency between successive frames under the assumption of a static scene. However, the presence of moving objects in dynamic scenes introduces inevitable inconsistencies, causing misaligned multi-frame feature matching and misleading self-supervision during training. In this paper, we propose a novel framework called ProDepth, which effectively addresses the mismatch problem caused by dynamic objects using a probabilistic approach. We initially deduce the uncertainty associated with static scene assumption by adopting an auxiliary decoder. This decoder analyzes inconsistencies embedded in the cost volume, inferring the probability of areas being dynamic. We then directly rectify the erroneous cost volume for dynamic areas through a Probabilistic Cost Volume Modulation (PCVM) module. Specifically, we derive probability distributions of depth candidates from both single-frame and multi-frame cues, modulating the cost volume by adaptively fusing those distributions based on the inferred uncertainty. Additionally, we present a self-supervision loss reweighting strategy that not only masks out incorrect supervision with high uncertainty but also mitigates the risks in remaining possible dynamic areas in accordance with the probability. Our proposed method excels over state-of-the-art approaches in all metrics on both Cityscapes and KITTI datasets, and demonstrates superior generalization ability on the Waymo Open dataset.
Pixel-Level Equalized Matching for Video Object Segmentation
Sep 04, 2022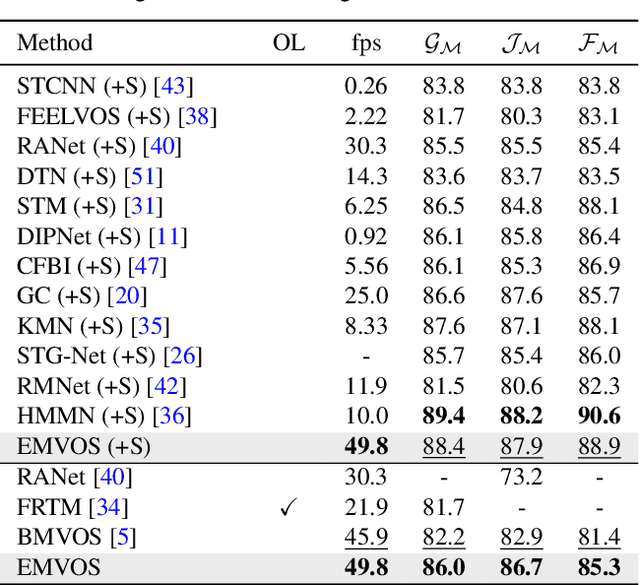
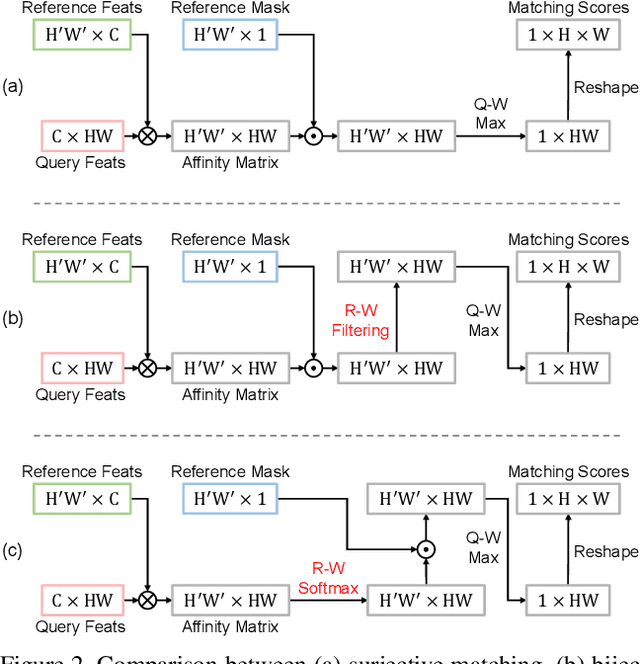
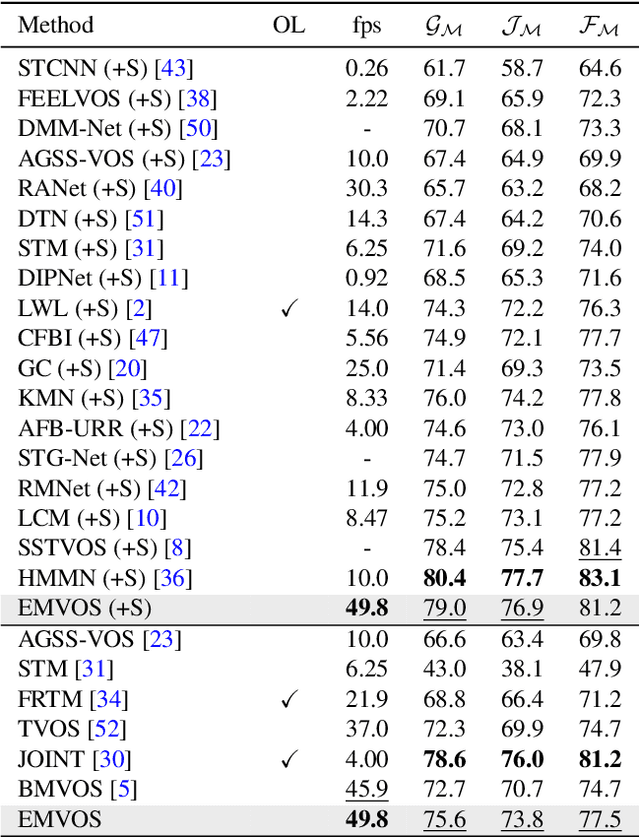
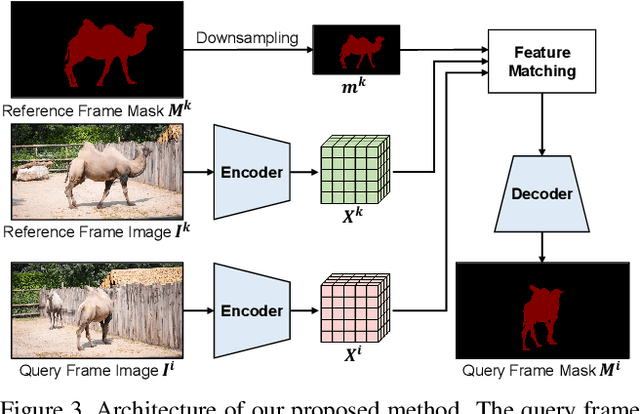
Feature similarity matching, which transfers the information of the reference frame to the query frame, is a key component in semi-supervised video object segmentation. If surjective matching is adopted, background distractors can easily occur and degrade the performance. Bijective matching mechanisms try to prevent this by restricting the amount of information being transferred to the query frame, but have two limitations: 1) surjective matching cannot be fully leveraged as it is transformed to bijective matching at test time; and 2) test-time manual tuning is required for searching the optimal hyper-parameters. To overcome these limitations while ensuring reliable information transfer, we introduce an equalized matching mechanism. To prevent the reference frame information from being overly referenced, the potential contribution to the query frame is equalized by simply applying a softmax operation along with the query. On public benchmark datasets, our proposed approach achieves a comparable performance to state-of-the-art methods.
AD-VO: Scale-Resilient Visual Odometry Using Attentive Disparity Map
Jan 07, 2020

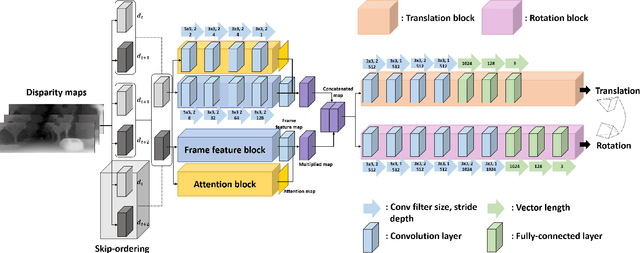
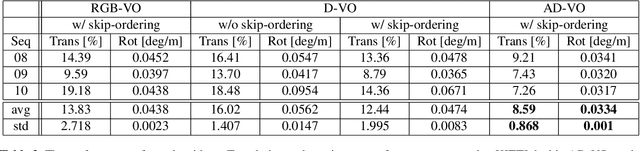
Visual odometry is an essential key for a localization module in SLAM systems. However, previous methods require tuning the system to adapt environment changes. In this paper, we propose a learning-based approach for frame-to-frame monocular visual odometry estimation. The proposed network is only learned by disparity maps for not only covering the environment changes but also solving the scale problem. Furthermore, attention block and skip-ordering scheme are introduced to achieve robust performance in various driving environment. Our network is compared with the conventional methods which use common domain such as color or optical flow. Experimental results confirm that the proposed network shows better performance than other approaches with higher and more stable results.