 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefineVAD: Semantic-Guided Feature Recalibration for Weakly Supervised Video Anomaly Detection
Nov 17, 2025



Weakly-Supervised Video Anomaly Detection aims to identify anomalous events using only video-level labels, balancing annotation efficiency with practical applicability. However, existing methods often oversimplify the anomaly space by treating all abnormal events as a single category, overlooking the diverse semantic and temporal characteristics intrinsic to real-world anomalies. Inspired by how humans perceive anomalies, by jointly interpreting temporal motion patterns and semantic structures underlying different anomaly types, we propose RefineVAD, a novel framework that mimics this dual-process reasoning. Our framework integrates two core modules. The first, Motion-aware Temporal Attention and Recalibration (MoTAR), estimates motion salience and dynamically adjusts temporal focus via shift-based attention and global Transformer-based modeling. The second, Category-Oriented Refinement (CORE), injects soft anomaly category priors into the representation space by aligning segment-level features with learnable category prototypes through cross-attention. By jointly leveraging temporal dynamics and semantic structure, explicitly models both "how" motion evolves and "what" semantic category it resembles. Extensive experiments on WVAD benchmark validate the effectiveness of RefineVAD and highlight the importance of integrating semantic context to guide feature refinement toward anomaly-relevant patterns.
PlugTrack: Multi-Perceptive Motion Analysis for Adaptive Fusion in Multi-Object Tracking
Nov 17, 2025Multi-object tracking (MOT) predominantly follows the tracking-by-detection paradigm, where Kalman filters serve as the standard motion predictor due to computational efficiency but inherently fail on non-linear motion patterns. Conversely, recent data-driven motion predictors capture complex non-linear dynamics but suffer from limited domain generalization and computational overhead. Through extensive analysis, we reveal that even in datasets dominated by non-linear motion, Kalman filter outperforms data-driven predictors in up to 34\% of cases, demonstrating that real-world tracking scenarios inherently involve both linear and non-linear patterns. To leverage this complementarity, we propose PlugTrack, a novel framework that adaptively fuses Kalman filter and data-driven motion predictors through multi-perceptive motion understanding. Our approach employs multi-perceptive motion analysis to generate adaptive blending factors. PlugTrack achieves significant performance gains on MOT17/MOT20 and state-of-the-art on DanceTrack without modifying existing motion predictors. To the best of our knowledge, PlugTrack is the first framework to bridge classical and modern motion prediction paradigms through adaptive fusion in MOT.
Treating Motion as Option with Output Selection for Unsupervised Video Object Segmentation
Sep 26, 2023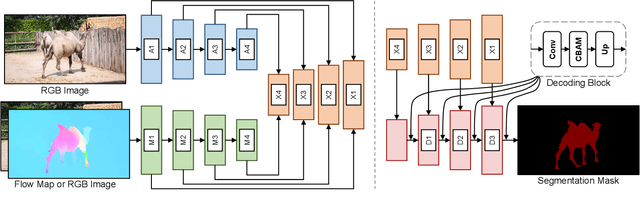



Unsupervised video object segmentation (VOS) is a task that aims to detect the most salient object in a video without external guidance about the object. To leverage the property that salient objects usually have distinctive movements compared to the background, recent methods collaboratively use motion cues extracted from optical flow maps with appearance cues extracted from RGB images. However, as optical flow maps are usually very relevant to segmentation masks, the network is easy to be learned overly dependent on the motion cues during network training. As a result, such two-stream approaches are vulnerable to confusing motion cues, making their prediction unstable. To relieve this issue, we design a novel motion-as-option network by treating motion cues as optional. During network training, RGB images are randomly provided to the motion encoder instead of optical flow maps, to implicitly reduce motion dependency of the network. As the learned motion encoder can deal with both RGB images and optical flow maps, two different predictions can be generated depending on which source information is used as motion input. In order to fully exploit this property, we also propose an adaptive output selection algorithm to adopt optimal prediction result at test time. Our proposed approach affords state-of-the-art performance on all public benchmark datasets, even maintaining real-time inference speed.
Feature Disentanglement Learning with Switching and Aggregation for Video-based Person Re-Identification
Dec 16, 2022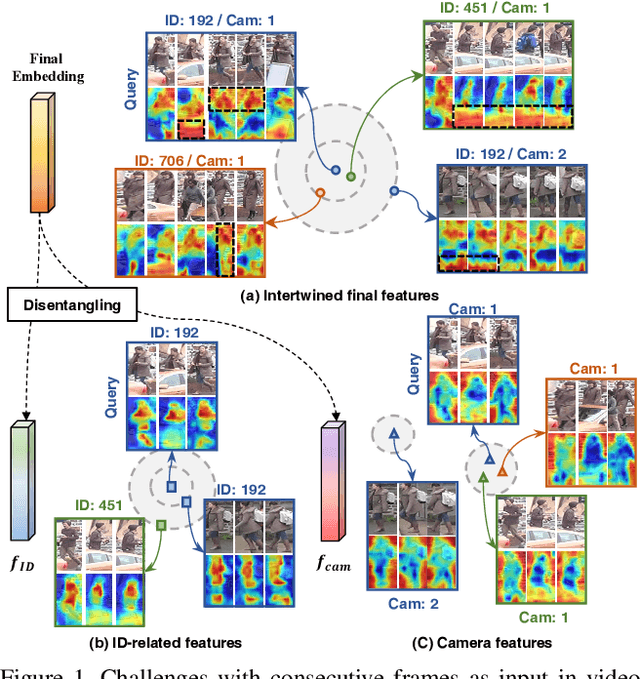
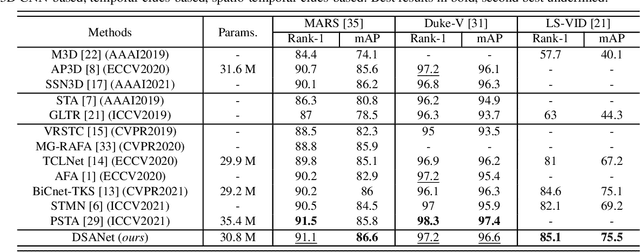
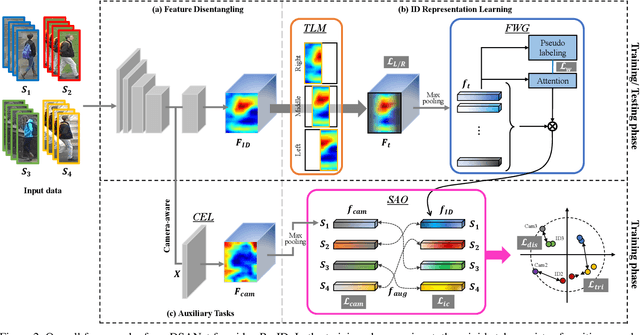
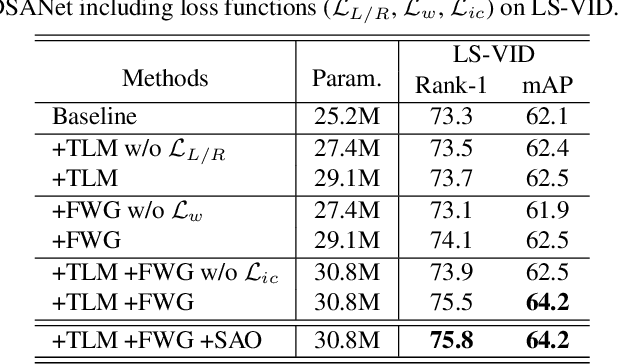
In video person re-identification (Re-ID), the network must consistently extract features of the target person from successive frames. Existing methods tend to focus only on how to use temporal information, which often leads to networks being fooled by similar appearances and same backgrounds. In this paper, we propose a Disentanglement and Switching and Aggregation Network (DSANet), which segregates the features representing identity and features based on camera characteristics, and pays more attention to ID information. We also introduce an auxiliary task that utilizes a new pair of features created through switching and aggregation to increase the network's capability for various camera scenarios. Furthermore, we devise a Target Localization Module (TLM) that extracts robust features against a change in the position of the target according to the frame flow and a Frame Weight Generation (FWG) that reflects temporal information in the final representation. Various loss functions for disentanglement learning are designed so that each component of the network can cooperate while satisfactorily performing its own role. Quantitative and qualitative results from extensive experiments demonstrate the superiority of DSANet over state-of-the-art methods on three benchmark datasets.
Occluded Person Re-Identification via Relational Adaptive Feature Correction Learning
Dec 09, 2022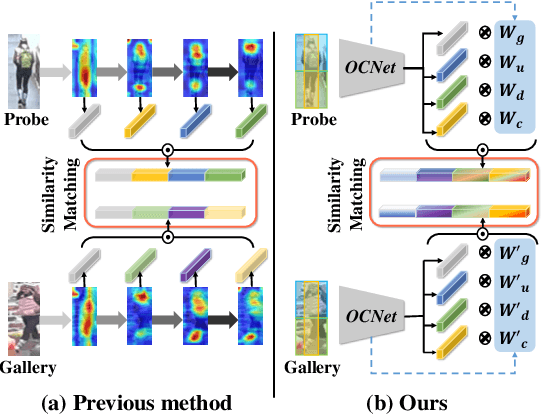
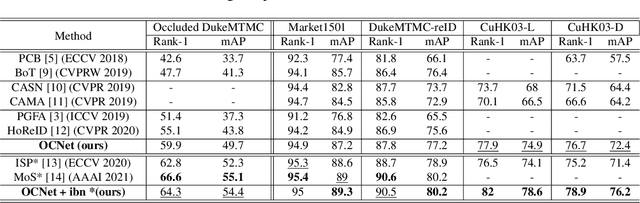
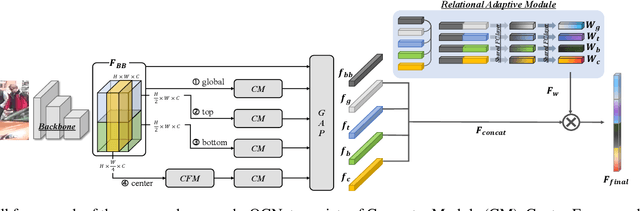

Occluded person re-identification (Re-ID) in images captured by multiple cameras is challenging because the target person is occluded by pedestrians or objects, especially in crowded scenes. In addition to the processes performed during holistic person Re-ID, occluded person Re-ID involves the removal of obstacles and the detection of partially visible body parts. Most existing methods utilize the off-the-shelf pose or parsing networks as pseudo labels, which are prone to error. To address these issues, we propose a novel Occlusion Correction Network (OCNet) that corrects features through relational-weight learning and obtains diverse and representative features without using external networks. In addition, we present a simple concept of a center feature in order to provide an intuitive solution to pedestrian occlusion scenarios. Furthermore, we suggest the idea of Separation Loss (SL) for focusing on different parts between global features and part features. We conduct extensive experiments on five challenging benchmark datasets for occluded and holistic Re-ID tasks to demonstrate that our method achieves superior performance to state-of-the-art methods especially on occluded scene.
Pixel-Level Equalized Matching for Video Object Segmentation
Sep 04, 2022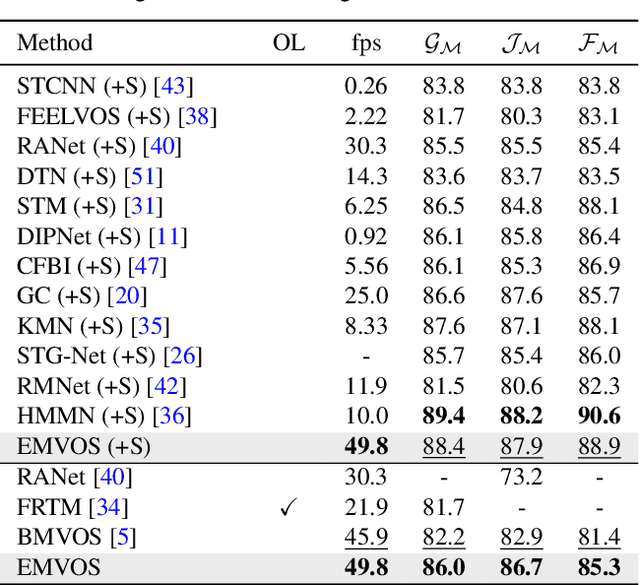
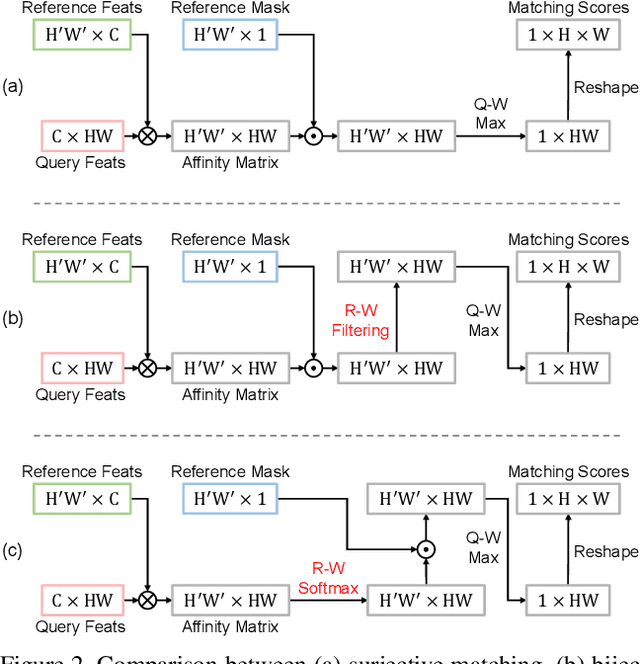
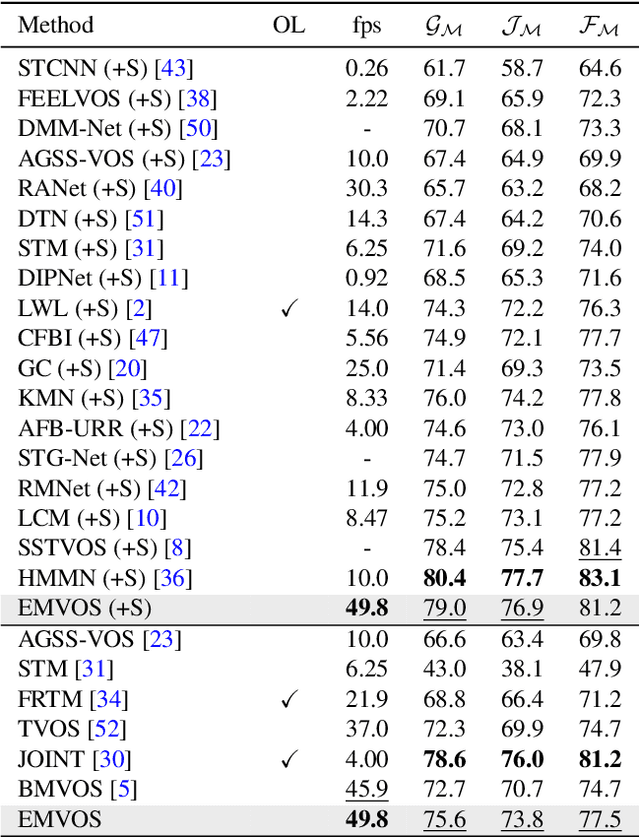
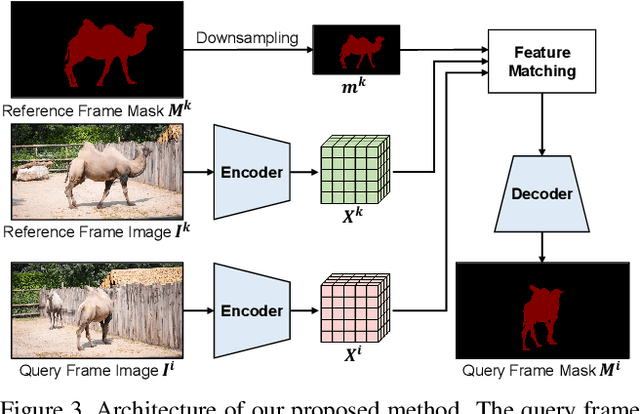
Feature similarity matching, which transfers the information of the reference frame to the query frame, is a key component in semi-supervised video object segmentation. If surjective matching is adopted, background distractors can easily occur and degrade the performance. Bijective matching mechanisms try to prevent this by restricting the amount of information being transferred to the query frame, but have two limitations: 1) surjective matching cannot be fully leveraged as it is transformed to bijective matching at test time; and 2) test-time manual tuning is required for searching the optimal hyper-parameters. To overcome these limitations while ensuring reliable information transfer, we introduce an equalized matching mechanism. To prevent the reference frame information from being overly referenced, the potential contribution to the query frame is equalized by simply applying a softmax operation along with the query. On public benchmark datasets, our proposed approach achieves a comparable performance to state-of-the-art methods.
NIR-to-VIS Face Recognition via Embedding Relations and Coordinates of the Pairwise Features
Aug 04, 2022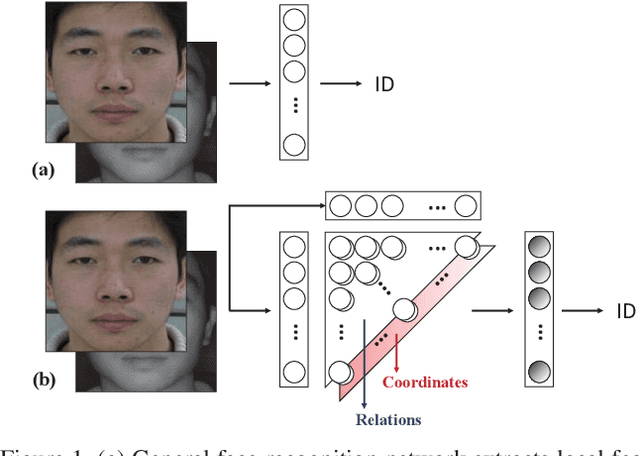

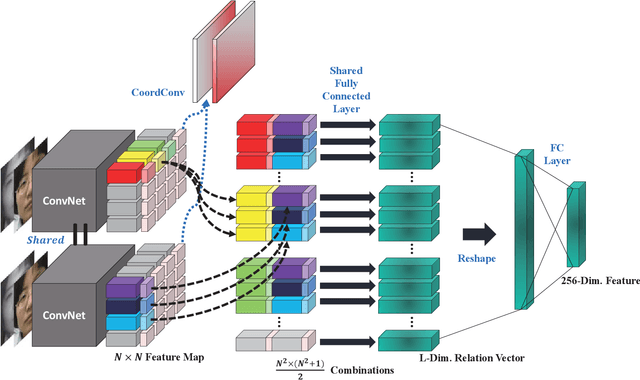
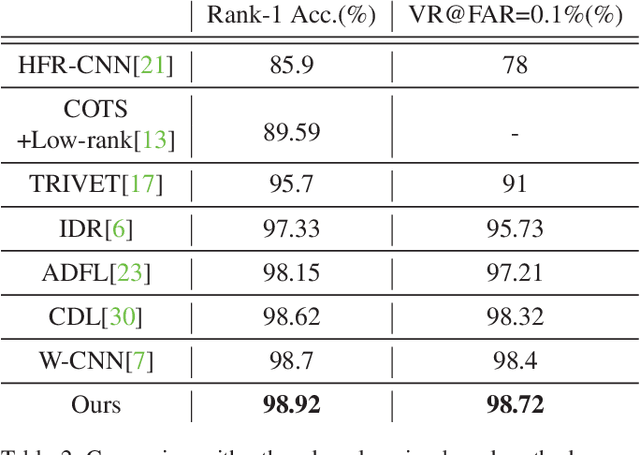
NIR-to-VIS face recognition is identifying faces of two different domains by extracting domain-invariant features. However, this is a challenging problem due to the two different domain characteristics, and the lack of NIR face dataset. In order to reduce domain discrepancy while using the existing face recognition models, we propose a 'Relation Module' which can simply add-on to any face recognition models. The local features extracted from face image contain information of each component of the face. Based on two different domain characteristics, to use the relationships between local features is more domain-invariant than to use it as it is. In addition to these relationships, positional information such as distance from lips to chin or eye to eye, also provides domain-invariant information. In our Relation Module, Relation Layer implicitly captures relationships, and Coordinates Layer models the positional information. Also, our proposed Triplet loss with conditional margin reduces intra-class variation in training, and resulting in additional performance improvements. Different from the general face recognition models, our add-on module does not need to pre-train with the large scale dataset. The proposed module fine-tuned only with CASIA NIR-VIS 2.0 database. With the proposed module, we achieve 14.81% rank-1 accuracy and 15.47% verification rate of 0.1% FAR improvements compare to two baseline models.
N-RPN: Hard Example Learning for Region Proposal Networks
Aug 03, 2022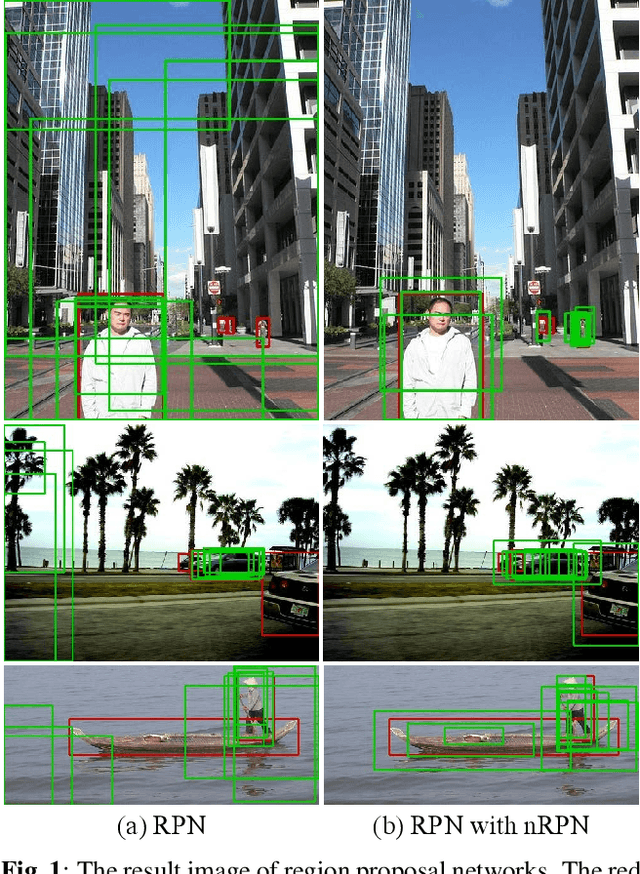

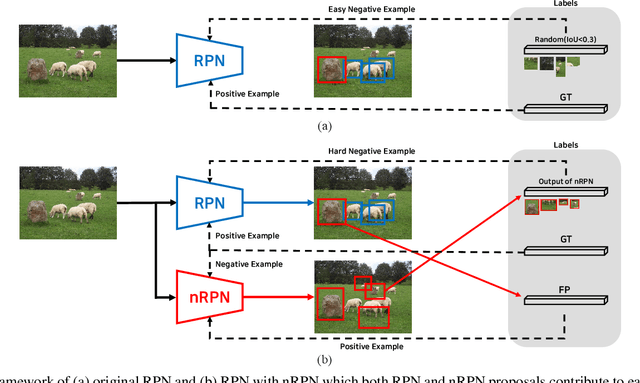
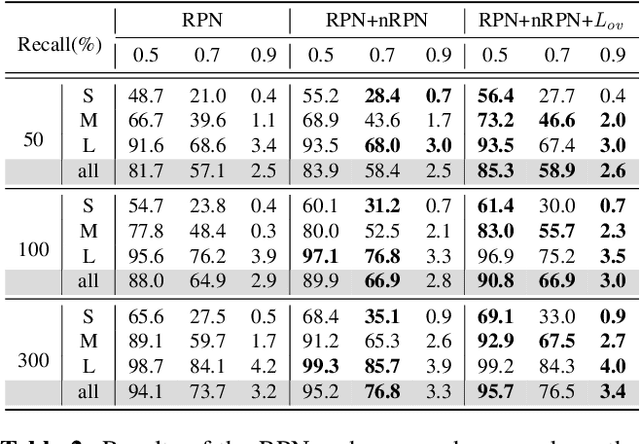
The region proposal task is to generate a set of candidate regions that contain an object. In this task, it is most important to propose as many candidates of ground-truth as possible in a fixed number of proposals. In a typical image, however, there are too few hard negative examples compared to the vast number of easy negatives, so region proposal networks struggle to train on hard negatives. Because of this problem, networks tend to propose hard negatives as candidates, while failing to propose ground-truth candidates, which leads to poor performance. In this paper, we propose a Negative Region Proposal Network(nRPN) to improve Region Proposal Network(RPN). The nRPN learns from the RPN's false positives and provide hard negative examples to the RPN. Our proposed nRPN leads to a reduction in false positives and better RPN performance. An RPN trained with an nRPN achieves performance improvements on the PASCAL VOC 2007 dataset.
RandomSEMO: Normality Learning Of Moving Objects For Video Anomaly Detection
Feb 13, 2022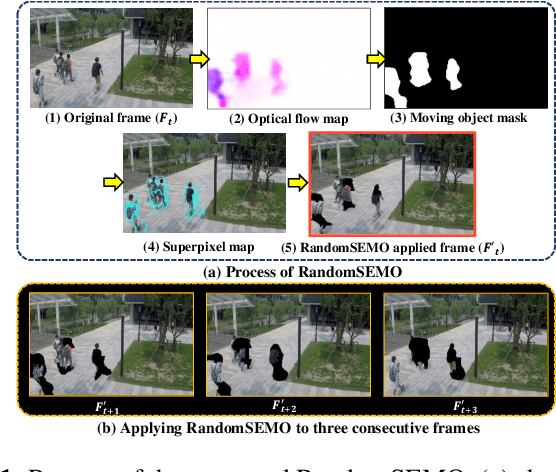

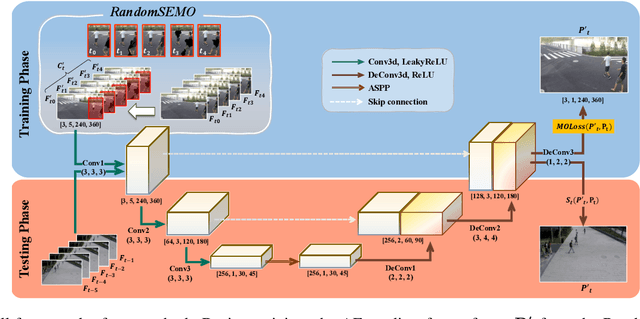
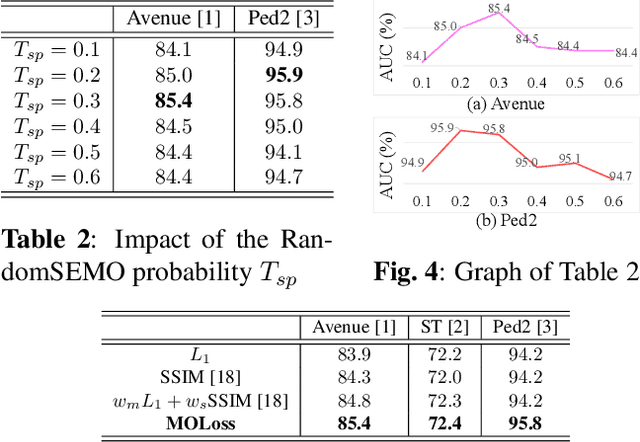
Recent anomaly detection algorithms have shown powerful performance by adopting frame predicting autoencoders. However, these methods face two challenging circumstances. First, they are likely to be trained to be excessively powerful, generating even abnormal frames well, which leads to failure in detecting anomalies. Second, they are distracted by the large number of objects captured in both foreground and background. To solve these problems, we propose a novel superpixel-based video data transformation technique named Random Superpixel Erasing on Moving Objects (RandomSEMO) and Moving Object Loss (MOLoss), built on top of a simple lightweight autoencoder. RandomSEMO is applied to the moving object regions by randomly erasing their superpixels. It enforces the network to pay attention to the foreground objects and learn the normal features more effectively, rather than simply predicting the future frame. Moreover, MOLoss urges the model to focus on learning normal objects captured within RandomSEMO by amplifying the loss on the pixels near the moving objects. The experimental results show that our model outperforms state-of-the-arts on three benchmarks.
Saliency Detection via Global Context Enhanced Feature Fusion and Edge Weighted Loss
Oct 13, 2021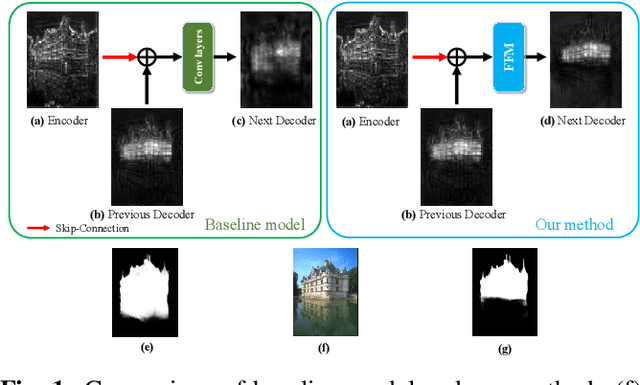
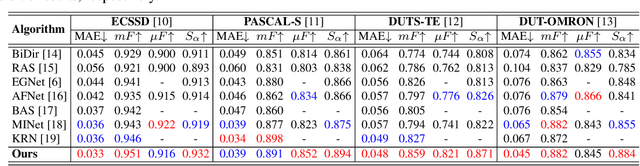


UNet-based methods have shown outstanding performance in salient object detection (SOD), but are problematic in two aspects. 1) Indiscriminately integrating the encoder feature, which contains spatial information for multiple objects, and the decoder feature, which contains global information of the salient object, is likely to convey unnecessary details of non-salient objects to the decoder, hindering saliency detection. 2) To deal with ambiguous object boundaries and generate accurate saliency maps, the model needs additional branches, such as edge reconstructions, which leads to increasing computational cost. To address the problems, we propose a context fusion decoder network (CFDN) and near edge weighted loss (NEWLoss) function. The CFDN creates an accurate saliency map by integrating global context information and thus suppressing the influence of the unnecessary spatial information. NEWLoss accelerates learning of obscure boundaries without additional modules by generating weight maps on object boundaries. Our method is evaluated on four benchmarks and achieves state-of-the-art performance. We prove the effectiveness of the proposed method through comparative experiments.