 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
CLIPtone: Unsupervised Learning for Text-based Image Tone Adjustment
Apr 01, 2024Recent image tone adjustment (or enhancement) approaches have predominantly adopted supervised learning for learning human-centric perceptual assessment. However, these approaches are constrained by intrinsic challenges of supervised learning. Primarily, the requirement for expertly-curated or retouched images escalates the data acquisition expenses. Moreover, their coverage of target style is confined to stylistic variants inferred from the training data. To surmount the above challenges, we propose an unsupervised learning-based approach for text-based image tone adjustment method, CLIPtone, that extends an existing image enhancement method to accommodate natural language descriptions. Specifically, we design a hyper-network to adaptively modulate the pretrained parameters of the backbone model based on text description. To assess whether the adjusted image aligns with the text description without ground truth image, we utilize CLIP, which is trained on a vast set of language-image pairs and thus encompasses knowledge of human perception. The major advantages of our approach are three fold: (i) minimal data collection expenses, (ii) support for a range of adjustments, and (iii) the ability to handle novel text descriptions unseen in training. Our approach's efficacy is demonstrated through comprehensive experiments, including a user study.
UGPNet: Universal Generative Prior for Image Restoration
Dec 31, 2023



Recent image restoration methods can be broadly categorized into two classes: (1) regression methods that recover the rough structure of the original image without synthesizing high-frequency details and (2) generative methods that synthesize perceptually-realistic high-frequency details even though the resulting image deviates from the original structure of the input. While both directions have been extensively studied in isolation, merging their benefits with a single framework has been rarely studied. In this paper, we propose UGPNet, a universal image restoration framework that can effectively achieve the benefits of both approaches by simply adopting a pair of an existing regression model and a generative model. UGPNet first restores the image structure of a degraded input using a regression model and synthesizes a perceptually-realistic image with a generative model on top of the regressed output. UGPNet then combines the regressed output and the synthesized output, resulting in a final result that faithfully reconstructs the structure of the original image in addition to perceptually-realistic textures. Our extensive experiments on deblurring, denoising, and super-resolution demonstrate that UGPNet can successfully exploit both regression and generative methods for high-fidelity image restoration.
Expanded Adaptive Scaling Normalization for End to End Image Compression
Aug 05, 2022Recently, learning-based image compression methods that utilize convolutional neural layers have been developed rapidly. Rescaling modules such as batch normalization which are often used in convolutional neural networks do not operate adaptively for the various inputs. Therefore, Generalized Divisible Normalization(GDN) has been widely used in image compression to rescale the input features adaptively across both spatial and channel axes. However, the representation power or degree of freedom of GDN is severely limited. Additionally, GDN cannot consider the spatial correlation of an image. To handle the limitations of GDN, we construct an expanded form of the adaptive scaling module, named Expanded Adaptive Scaling Normalization(EASN). First, we exploit the swish function to increase the representation ability. Then, we increase the receptive field to make the adaptive rescaling module consider the spatial correlation. Furthermore, we introduce an input mapping function to give the module a higher degree of freedom. We demonstrate how our EASN works in an image compression network using the visualization results of the feature map, and we conduct extensive experiments to show that our EASN increases the rate-distortion performance remarkably, and even outperforms the VVC intra at a high bit rate.
N-RPN: Hard Example Learning for Region Proposal Networks
Aug 03, 2022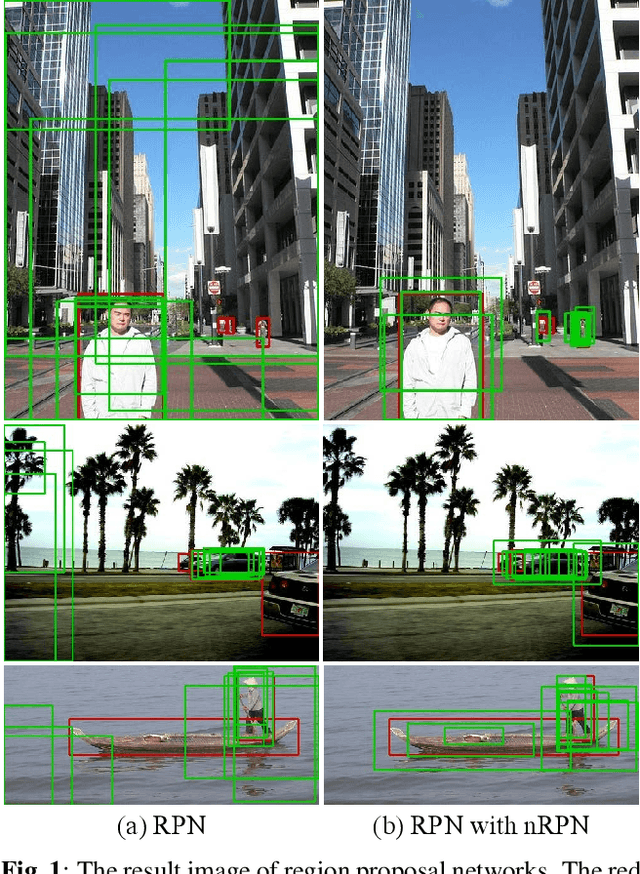

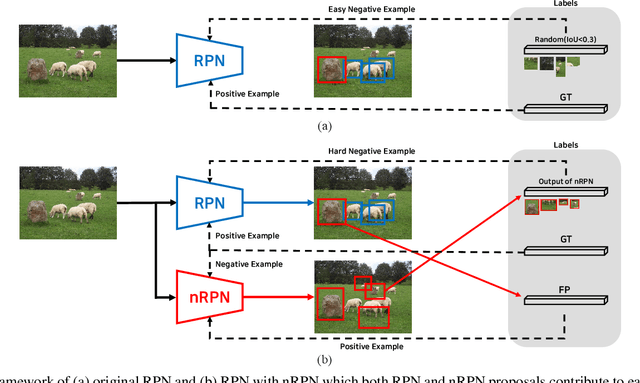
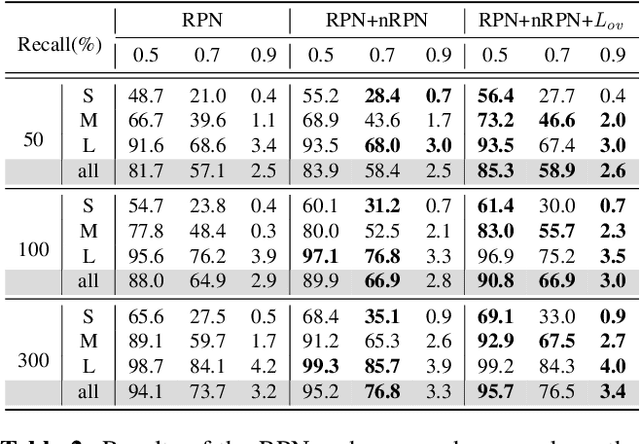
The region proposal task is to generate a set of candidate regions that contain an object. In this task, it is most important to propose as many candidates of ground-truth as possible in a fixed number of proposals. In a typical image, however, there are too few hard negative examples compared to the vast number of easy negatives, so region proposal networks struggle to train on hard negatives. Because of this problem, networks tend to propose hard negatives as candidates, while failing to propose ground-truth candidates, which leads to poor performance. In this paper, we propose a Negative Region Proposal Network(nRPN) to improve Region Proposal Network(RPN). The nRPN learns from the RPN's false positives and provide hard negative examples to the RPN. Our proposed nRPN leads to a reduction in false positives and better RPN performance. An RPN trained with an nRPN achieves performance improvements on the PASCAL VOC 2007 dataset.
Beyond Natural Motion: Exploring Discontinuity for Video Frame Interpolation
Feb 17, 2022



Video interpolation is the task that synthesizes the intermediate frame given two consecutive frames. Most of the previous studies have focused on appropriate frame warping operations and refinement modules for the warped frames. These studies have been conducted on natural videos having only continuous motions. However, many practical videos contain a lot of discontinuous motions, such as chat windows, watermarks, GUI elements, or subtitles. We propose three techniques to expand the concept of transition between two consecutive frames to address these issues. First is a new architecture that can separate continuous and discontinuous motion areas. We also propose a novel data augmentation strategy called figure-text mixing (FTM) to make our model learn more general scenarios. Finally, we propose loss functions to give supervisions of the discontinuous motion areas with the data augmentation. We collected a special dataset consisting of some mobile games and chatting videos. We show that our method significantly improves the interpolation qualities of the videos on the special dataset. Moreover, our model outperforms the state-of-the-art methods for natural video datasets containing only continuous motions, such as DAVIS and UCF101.
Regularization Strategy for Point Cloud via Rigidly Mixed Sample
Feb 03, 2021

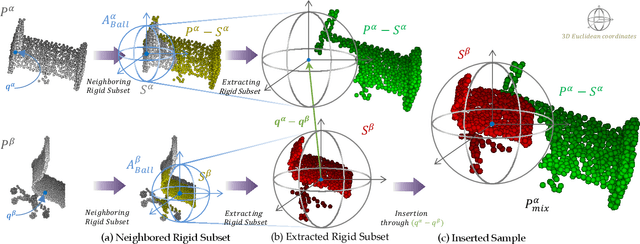
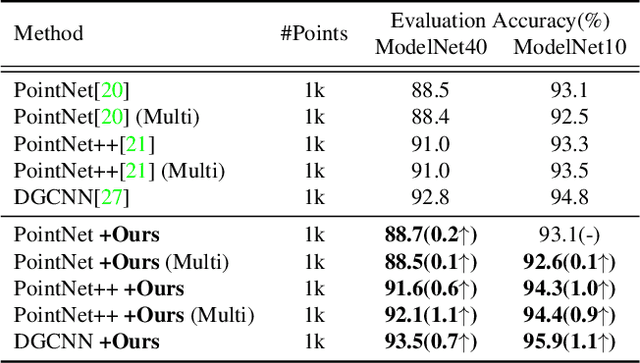
Data augmentation is an effective regularization strategy to alleviate the overfitting, which is an inherent drawback of the deep neural networks. However, data augmentation is rarely considered for point cloud processing despite many studies proposing various augmentation methods for image data. Actually, regularization is essential for point clouds since lack of generality is more likely to occur in point cloud due to small datasets. This paper proposes a Rigid Subset Mix (RSMix), a novel data augmentation method for point clouds that generates a virtual mixed sample by replacing part of the sample with shape-preserved subsets from another sample. RSMix preserves structural information of the point cloud sample by extracting subsets from each sample without deformation using a neighboring function. The neighboring function was carefully designed considering unique properties of point cloud, unordered structure and non-grid. Experiments verified that RSMix successfully regularized the deep neural networks with remarkable improvement for shape classification. We also analyzed various combinations of data augmentations including RSMix with single and multi-view evaluations, based on abundant ablation studies.
Smoother Network Tuning and Interpolation for Continuous-level Image Processing
Oct 05, 2020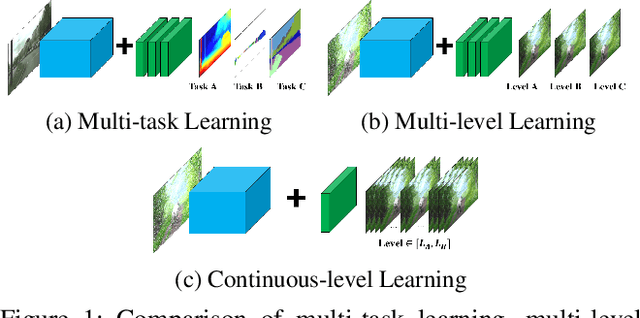
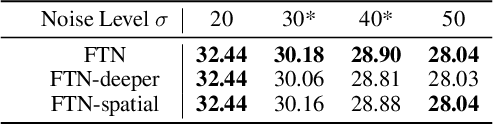
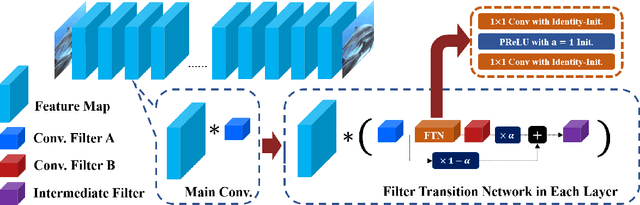
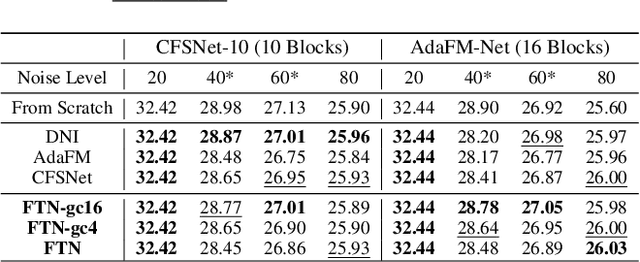
In Convolutional Neural Network (CNN) based image processing, most studies propose networks that are optimized to single-level (or single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train networks on two different levels and propose their own interpolation methods to enable arbitrary intermediate levels. However, many of them fail to generalize or have certain side effects in practical usage. In this paper, we define these frameworks as network tuning and interpolation and propose a novel module for continuous-level learning, called Filter Transition Network (FTN). This module is a structurally smoother module than existing ones. Therefore, the frameworks with FTN generalize well across various tasks and networks and cause fewer undesirable side effects. For stable learning of FTN, we additionally propose a method to initialize non-linear neural network layers with identity mappings. Extensive results for various image processing tasks indicate that the performance of FTN is comparable in multiple continuous levels, and is significantly smoother and lighter than that of other frameworks.
Enhanced Standard Compatible Image Compression Framework based on Auxiliary Codec Networks
Sep 30, 2020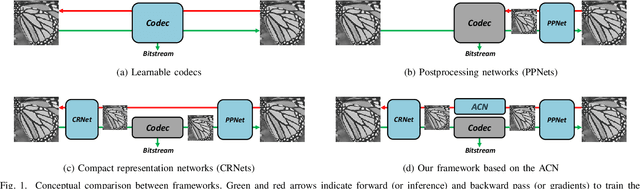
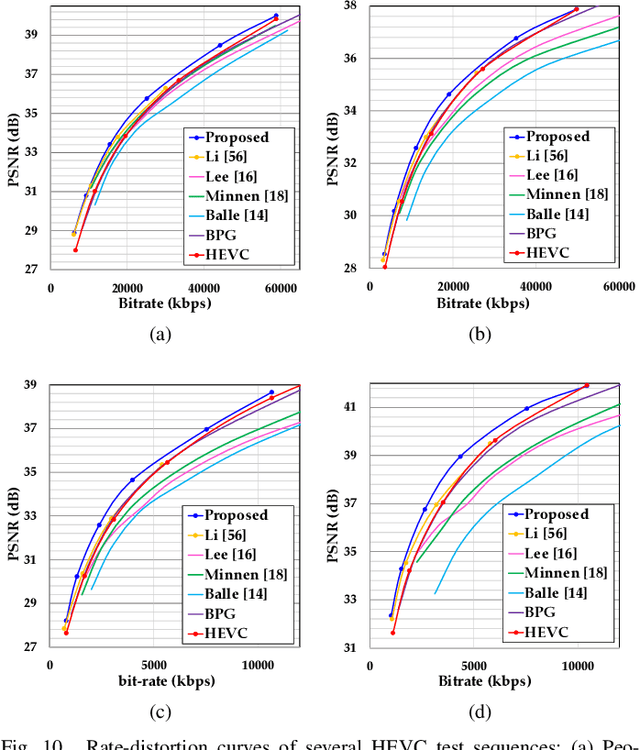
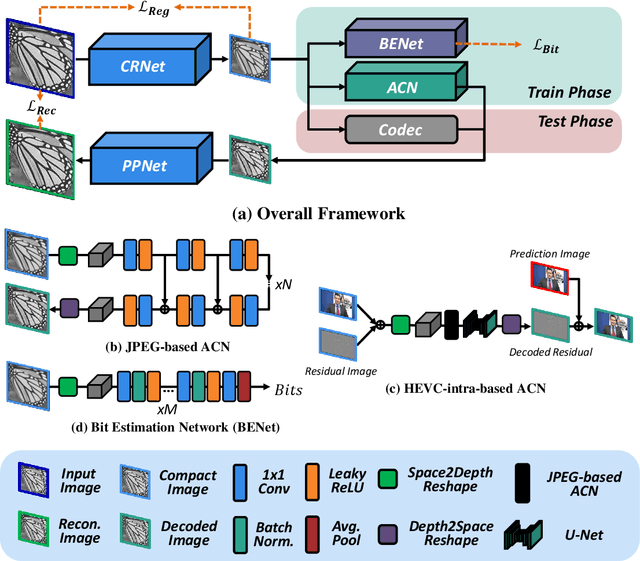
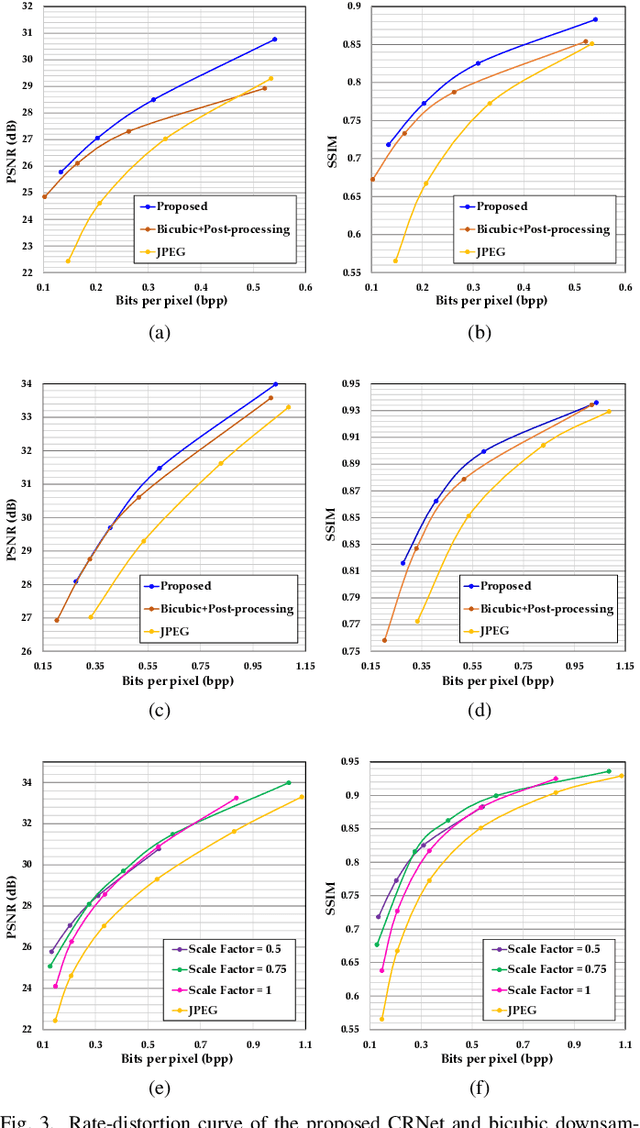
To enhance image compression performance, recent deep neural network-based research can be divided into three categories: a learnable codec, a postprocessing network, and a compact representation network. The learnable codec has been designed for an end-to-end learning beyond the conventional compression modules. The postprocessing network increases the quality of decoded images using an example-based learning. The compact representation network is learned to reduce the capacity of an input image to reduce the bitrate while keeping the quality of the decoded image. However, these approaches are not compatible with the existing codecs or not optimal to increase the coding efficiency. Specifically, it is difficult to achieve optimal learning in the previous studies using the compact representation network, due to the inaccurate consideration of the codecs. In this paper, we propose a novel standard compatible image compression framework based on Auxiliary Codec Networks (ACNs). ACNs are designed to imitate image degradation operations of the existing codec, which delivers more accurate gradients to the compact representation network. Therefore, the compact representation and the postprocessing networks can be learned effectively and optimally. We demonstrate that our proposed framework based on JPEG and High Efficiency Video Coding (HEVC) standard substantially outperforms existing image compression algorithms in a standard compatible manner.
Learning Temporally Invariant and Localizable Features via Data Augmentation for Video Recognition
Aug 13, 2020



Deep-Learning-based video recognition has shown promising improvements along with the development of large-scale datasets and spatiotemporal network architectures. In image recognition, learning spatially invariant features is a key factor in improving recognition performance and robustness. Data augmentation based on visual inductive priors, such as cropping, flipping, rotating, or photometric jittering, is a representative approach to achieve these features. Recent state-of-the-art recognition solutions have relied on modern data augmentation strategies that exploit a mixture of augmentation operations. In this study, we extend these strategies to the temporal dimension for videos to learn temporally invariant or temporally localizable features to cover temporal perturbations or complex actions in videos. Based on our novel temporal data augmentation algorithms, video recognition performances are improved using only a limited amount of training data compared to the spatial-only data augmentation algorithms, including the 1st Visual Inductive Priors (VIPriors) for data-efficient action recognition challenge. Furthermore, learned features are temporally localizable that cannot be achieved using spatial augmentation algorithms. Our source code is available at https://github.com/taeoh-kim/temporal_data_augmentation.