 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVI-Bench: A Dynamic Microworld for Strategic Video Intelligence
May 29, 2026True video intelligence demands more than recognizing what is visible: it requires reasoning about why events unfold, predicting what would change under different conditions, and deciding what to do next. We refer to this progression, from perception through causal reasoning and simulation to strategic planning, as Strategic Video Intelligence (SVI). No existing benchmark evaluates this capability stack: in-the-wild videos lack verifiable ground truth for causal and strategic questions, while synthetic environments sacrifice the complexity of real multi-agent systems. To bridge this gap, we introduce SVI-Bench, a large-scale benchmark that leverages team sports as a dynamic microworld, combining the complexity of real-world multi-agent interaction (10-22 agents making coordinated decisions under adversarial pressure) with the verifiability of explicit rules and definitive outcomes. SVI-Bench comprises approximately 35K hours of broadcast video, 15M annotated actions, 15K hours of expert commentary, 23K game reports, and 103K structured statistical records across basketball, soccer, and hockey, all constructed via a data engine that transforms raw game data into a dense, cross-referenced corpus. We organize evaluation into 9 tasks spanning a progressive four-pillar hierarchy: Dynamic Scene Understanding, Causal Reasoning, Strategic Simulation, and Agentic Synthesis. Evaluating strong multimodal and agentic baselines, we find a capability cliff: models perform competently on perceptual tasks, achieving approximately 73% on fine-grained action QA, but degrade sharply at each successive cognitive level. Agentic tasks prove hardest: the strongest model achieves only 5% accuracy when required to autonomously gather and integrate evidence across a corpus of 1.8M clips.
Video Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Sep 09, 2025



Video Large Language Models (VideoLLMs) face a critical bottleneck: increasing the number of input frames to capture fine-grained temporal detail leads to prohibitive computational costs and performance degradation from long context lengths. We introduce Video Parallel Scaling (VPS), an inference-time method that expands a model's perceptual bandwidth without increasing its context window. VPS operates by running multiple parallel inference streams, each processing a unique, disjoint subset of the video's frames. By aggregating the output probabilities from these complementary streams, VPS integrates a richer set of visual information than is possible with a single pass. We theoretically show that this approach effectively contracts the Chinchilla scaling law by leveraging uncorrelated visual evidence, thereby improving performance without additional training. Extensive experiments across various model architectures and scales (2B-32B) on benchmarks such as Video-MME and EventHallusion demonstrate that VPS consistently and significantly improves performance. It scales more favorably than other parallel alternatives (e.g. Self-consistency) and is complementary to other decoding strategies, offering a memory-efficient and robust framework for enhancing the temporal reasoning capabilities of VideoLLMs.
Finding NeMo: Negative-mined Mosaic Augmentation for Referring Image Segmentation
Nov 03, 2024



Referring Image Segmentation is a comprehensive task to segment an object referred by a textual query from an image. In nature, the level of difficulty in this task is affected by the existence of similar objects and the complexity of the referring expression. Recent RIS models still show a significant performance gap between easy and hard scenarios. We pose that the bottleneck exists in the data, and propose a simple but powerful data augmentation method, Negative-mined Mosaic Augmentation (NeMo). This method augments a training image into a mosaic with three other negative images carefully curated by a pretrained multimodal alignment model, e.g., CLIP, to make the sample more challenging. We discover that it is critical to properly adjust the difficulty level, neither too ambiguous nor too trivial. The augmented training data encourages the RIS model to recognize subtle differences and relationships between similar visual entities and to concretely understand the whole expression to locate the right target better. Our approach shows consistent improvements on various datasets and models, verified by extensive experiments.
Scalable Frame Sampling for Video Classification: A Semi-Optimal Policy Approach with Reduced Search Space
Sep 09, 2024Given a video with $T$ frames, frame sampling is a task to select $N \ll T$ frames, so as to maximize the performance of a fixed video classifier. Not just brute-force search, but most existing methods suffer from its vast search space of $\binom{T}{N}$, especially when $N$ gets large. To address this challenge, we introduce a novel perspective of reducing the search space from $O(T^N)$ to $O(T)$. Instead of exploring the entire $O(T^N)$ space, our proposed semi-optimal policy selects the top $N$ frames based on the independently estimated value of each frame using per-frame confidence, significantly reducing the computational complexity. We verify that our semi-optimal policy can efficiently approximate the optimal policy, particularly under practical settings. Additionally, through extensive experiments on various datasets and model architectures, we demonstrate that learning our semi-optimal policy ensures stable and high performance regardless of the size of $N$ and $T$.
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
Boundary-aware Self-supervised Learning for Video Scene Segmentation
Jan 14, 2022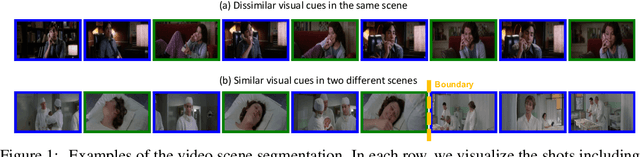
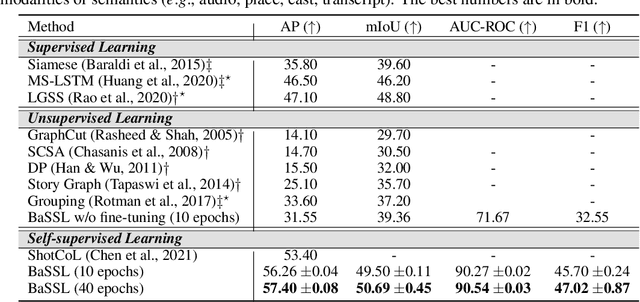
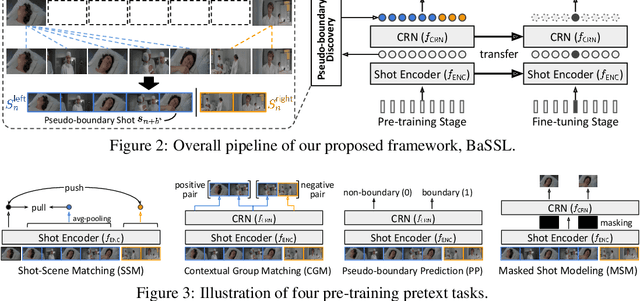
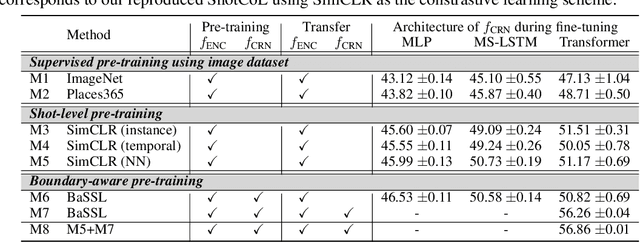
Self-supervised learning has drawn attention through its effectiveness in learning in-domain representations with no ground-truth annotations; in particular, it is shown that properly designed pretext tasks (e.g., contrastive prediction task) bring significant performance gains for downstream tasks (e.g., classification task). Inspired from this, we tackle video scene segmentation, which is a task of temporally localizing scene boundaries in a video, with a self-supervised learning framework where we mainly focus on designing effective pretext tasks. In our framework, we discover a pseudo-boundary from a sequence of shots by splitting it into two continuous, non-overlapping sub-sequences and leverage the pseudo-boundary to facilitate the pre-training. Based on this, we introduce three novel boundary-aware pretext tasks: 1) Shot-Scene Matching (SSM), 2) Contextual Group Matching (CGM) and 3) Pseudo-boundary Prediction (PP); SSM and CGM guide the model to maximize intra-scene similarity and inter-scene discrimination while PP encourages the model to identify transitional moments. Through comprehensive analysis, we empirically show that pre-training and transferring contextual representation are both critical to improving the video scene segmentation performance. Lastly, we achieve the new state-of-the-art on the MovieNet-SSeg benchmark. The code is available at https://github.com/kakaobrain/bassl.