 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Revisit to the Decoder for Camouflaged Object Detection
Mar 18, 2025

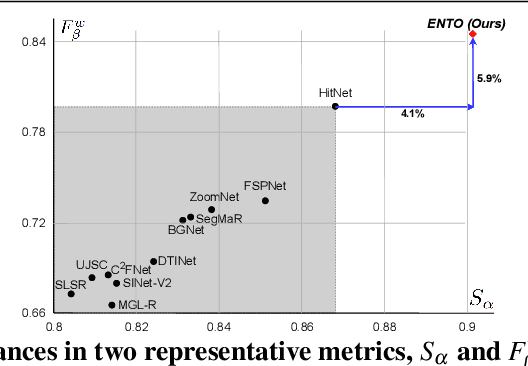
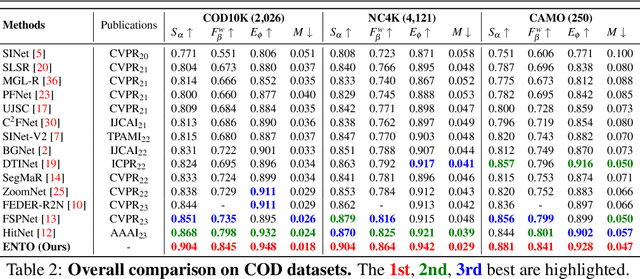
Camouflaged object detection (COD) aims to generate a fine-grained segmentation map of camouflaged objects hidden in their background. Due to the hidden nature of camouflaged objects, it is essential for the decoder to be tailored to effectively extract proper features of camouflaged objects and extra-carefully generate their complex boundaries. In this paper, we propose a novel architecture that augments the prevalent decoding strategy in COD with Enrich Decoder and Retouch Decoder, which help to generate a fine-grained segmentation map. Specifically, the Enrich Decoder amplifies the channels of features that are important for COD using channel-wise attention. Retouch Decoder further refines the segmentation maps by spatially attending to important pixels, such as the boundary regions. With extensive experiments, we demonstrate that ENTO shows superior performance using various encoders, with the two novel components playing their unique roles that are mutually complementary.
* Published in BMVC 2024, 13 pages, 7 figures (Appendix: 5 pages, 2 figures)
Scalable Frame Sampling for Video Classification: A Semi-Optimal Policy Approach with Reduced Search Space
Sep 09, 2024Given a video with $T$ frames, frame sampling is a task to select $N \ll T$ frames, so as to maximize the performance of a fixed video classifier. Not just brute-force search, but most existing methods suffer from its vast search space of $\binom{T}{N}$, especially when $N$ gets large. To address this challenge, we introduce a novel perspective of reducing the search space from $O(T^N)$ to $O(T)$. Instead of exploring the entire $O(T^N)$ space, our proposed semi-optimal policy selects the top $N$ frames based on the independently estimated value of each frame using per-frame confidence, significantly reducing the computational complexity. We verify that our semi-optimal policy can efficiently approximate the optimal policy, particularly under practical settings. Additionally, through extensive experiments on various datasets and model architectures, we demonstrate that learning our semi-optimal policy ensures stable and high performance regardless of the size of $N$ and $T$.