 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace Residual Rotation Approximation
Apr 13, 2026Rotation-based Post-Training Quantization (PTQ) has emerged as a promising solution for mitigating activation outliers in the quantization of Large Language Models (LLMs). Global rotation methods achieve inference efficiency by fusing activation rotations into attention and FFN blocks, but suffer from limited expressivity as they are constrained to use a single learnable rotation matrix across all layers. To tackle this, layer-wise transformation methods emerged, achieving superior accuracy through localized adaptation. However, layer-wise methods cannot fuse activation rotation matrices into weights, requiring online computations and causing significant overhead. In this paper, we propose ReSpinQuant, a quantization framework that resolves such overhead by leveraging offline activation rotation fusion and matching basis using efficient residual subspace rotation. This design reconciles the high expressivity of layer-wise adaptation with only negligible inference overhead. Extensive experiments on W4A4 and W3A3 quantization demonstrate that ReSpinQuant achieves state-of-the-art performance, outperforming global rotation methods and matching the accuracy of computationally expensive layer-wise methods with minimal overhead.
Alignment-Aware Quantization for LLM Safety
Nov 11, 2025Safety and efficiency are both important factors when deploying large language models(LLMs). LLMs are trained to follow human alignment for safety, and post training quantization(PTQ) is applied afterward for efficiency. However, these two objectives are often in conflict, revealing a fundamental flaw in the conventional PTQ paradigm: quantization can turn into a safety vulnerability if it only aims to achieve low perplexity. Models can demonstrate low perplexity yet exhibit significant degradation in alignment with the safety policy, highlighting that perplexity alone is an insufficient and often misleading proxy for model safety. To address this, we propose Alignment-Aware Quantization(AAQ), a novel approach that integrates Alignment-Preserving Contrastive(APC) loss into the PTQ pipeline. Compared to simple reconstruction loss, ours explicitly preserves alignment by encouraging the quantized model to mimic its safe, instruction-tuned model while diverging from the unaligned, pre-trained counterpart. Our method achieves this robust safety alignment without resorting to specialized safety-focused calibration datasets, highlighting its practical utility and broad applicability. AAQ is compatible with standard PTQ techniques and enables robust 4-bit (W4A4) quantization across diverse model families such as LLaMA, Qwen, and Mistral while maintaining safety where previous methods fail. Our work resolves the critical trade-off between efficiency and safety, paving the way toward LLMs that are both efficient and trustworthy. Anonymized code is available in the supplementary material.
A Revisit to the Decoder for Camouflaged Object Detection
Mar 18, 2025

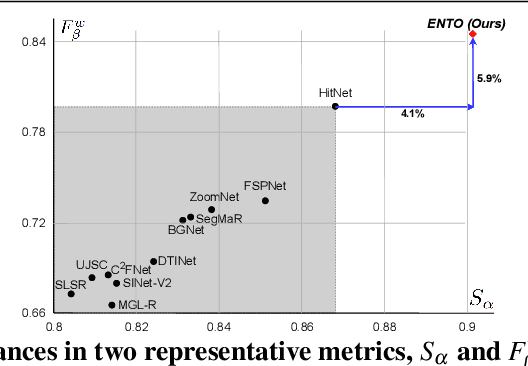
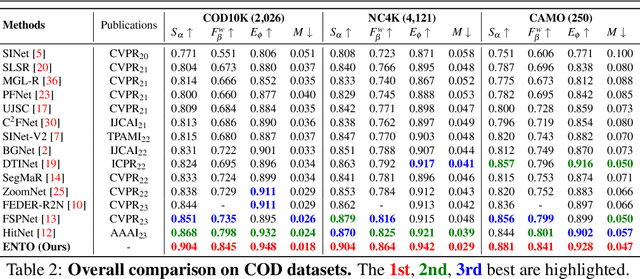
Camouflaged object detection (COD) aims to generate a fine-grained segmentation map of camouflaged objects hidden in their background. Due to the hidden nature of camouflaged objects, it is essential for the decoder to be tailored to effectively extract proper features of camouflaged objects and extra-carefully generate their complex boundaries. In this paper, we propose a novel architecture that augments the prevalent decoding strategy in COD with Enrich Decoder and Retouch Decoder, which help to generate a fine-grained segmentation map. Specifically, the Enrich Decoder amplifies the channels of features that are important for COD using channel-wise attention. Retouch Decoder further refines the segmentation maps by spatially attending to important pixels, such as the boundary regions. With extensive experiments, we demonstrate that ENTO shows superior performance using various encoders, with the two novel components playing their unique roles that are mutually complementary.
* Published in BMVC 2024, 13 pages, 7 figures (Appendix: 5 pages, 2 figures)
Contrastive and Consistency Learning for Neural Noisy-Channel Model in Spoken Language Understanding
May 23, 2024



Recently, deep end-to-end learning has been studied for intent classification in Spoken Language Understanding (SLU). However, end-to-end models require a large amount of speech data with intent labels, and highly optimized models are generally sensitive to the inconsistency between the training and evaluation conditions. Therefore, a natural language understanding approach based on Automatic Speech Recognition (ASR) remains attractive because it can utilize a pre-trained general language model and adapt to the mismatch of the speech input environment. Using this module-based approach, we improve a noisy-channel model to handle transcription inconsistencies caused by ASR errors. We propose a two-stage method, Contrastive and Consistency Learning (CCL), that correlates error patterns between clean and noisy ASR transcripts and emphasizes the consistency of the latent features of the two transcripts. Experiments on four benchmark datasets show that CCL outperforms existing methods and improves the ASR robustness in various noisy environments. Code is available at https://github.com/syoung7388/CCL.
Do not think pink elephant!
Apr 22, 2024Large Models (LMs) have heightened expectations for the potential of general AI as they are akin to human intelligence. This paper shows that recent large models such as Stable Diffusion and DALL-E3 also share the vulnerability of human intelligence, namely the "white bear phenomenon". We investigate the causes of the white bear phenomenon by analyzing their representation space. Based on this analysis, we propose a simple prompt-based attack method, which generates figures prohibited by the LM provider's policy. To counter these attacks, we introduce prompt-based defense strategies inspired by cognitive therapy techniques, successfully mitigating attacks by up to 48.22\%.
Coreset Selection for Object Detection
Apr 14, 2024



Coreset selection is a method for selecting a small, representative subset of an entire dataset. It has been primarily researched in image classification, assuming there is only one object per image. However, coreset selection for object detection is more challenging as an image can contain multiple objects. As a result, much research has yet to be done on this topic. Therefore, we introduce a new approach, Coreset Selection for Object Detection (CSOD). CSOD generates imagewise and classwise representative feature vectors for multiple objects of the same class within each image. Subsequently, we adopt submodular optimization for considering both representativeness and diversity and utilize the representative vectors in the submodular optimization process to select a subset. When we evaluated CSOD on the Pascal VOC dataset, CSOD outperformed random selection by +6.4%p in AP$_{50}$ when selecting 200 images.