 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoreset Selection for Object Detection
Apr 14, 2024



Coreset selection is a method for selecting a small, representative subset of an entire dataset. It has been primarily researched in image classification, assuming there is only one object per image. However, coreset selection for object detection is more challenging as an image can contain multiple objects. As a result, much research has yet to be done on this topic. Therefore, we introduce a new approach, Coreset Selection for Object Detection (CSOD). CSOD generates imagewise and classwise representative feature vectors for multiple objects of the same class within each image. Subsequently, we adopt submodular optimization for considering both representativeness and diversity and utilize the representative vectors in the submodular optimization process to select a subset. When we evaluated CSOD on the Pascal VOC dataset, CSOD outperformed random selection by +6.4%p in AP$_{50}$ when selecting 200 images.
MDPose: Real-Time Multi-Person Pose Estimation via Mixture Density Model
Feb 17, 2023One of the major challenges in multi-person pose estimation is instance-aware keypoint estimation. Previous methods address this problem by leveraging an off-the-shelf detector, heuristic post-grouping process or explicit instance identification process, hindering further improvements in the inference speed which is an important factor for practical applications. From the statistical point of view, those additional processes for identifying instances are necessary to bypass learning the high-dimensional joint distribution of human keypoints, which is a critical factor for another major challenge, the occlusion scenario. In this work, we propose a novel framework of single-stage instance-aware pose estimation by modeling the joint distribution of human keypoints with a mixture density model, termed as MDPose. Our MDPose estimates the distribution of human keypoints' coordinates using a mixture density model with an instance-aware keypoint head consisting simply of 8 convolutional layers. It is trained by minimizing the negative log-likelihood of the ground truth keypoints. Also, we propose a simple yet effective training strategy, Random Keypoint Grouping (RKG), which significantly alleviates the underflow problem leading to successful learning of relations between keypoints. On OCHuman dataset, which consists of images with highly occluded people, our MDPose achieves state-of-the-art performance by successfully learning the high-dimensional joint distribution of human keypoints. Furthermore, our MDPose shows significant improvement in inference speed with a competitive accuracy on MS COCO, a widely-used human keypoint dataset, thanks to the proposed much simpler single-stage pipeline.
Sparse MDOD: Training End-to-End Multi-Object Detector without Bipartite Matching
May 18, 2022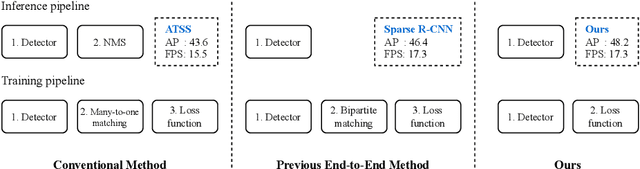
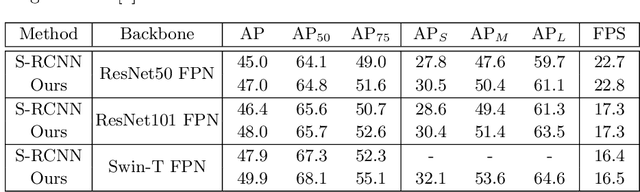
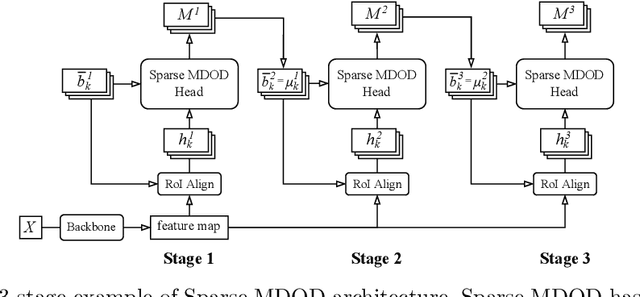
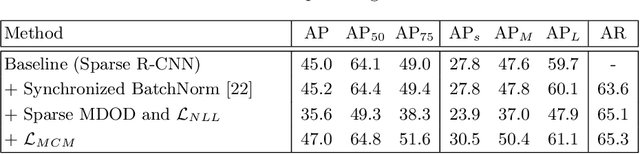
Recent end-to-end multi-object detectors simplify the inference pipeline by removing the hand-crafted process such as the duplicate bounding box removal using non-maximum suppression (NMS). However, in the training, they require bipartite matching to calculate the loss from the output of the detector. Contrary to the directivity of the end-to-end method, the bipartite matching makes the training of the end-to-end detector complex, heuristic, and reliant. In this paper, we aim to propose a method to train the end-to-end multi-object detector without bipartite matching. To this end, we approach end-to-end multi-object detection as a density estimation using a mixture model. Our proposed detector, called Sparse Mixture Density Object Detector (Sparse MDOD) estimates the distribution of bounding boxes using a mixture model. Sparse MDOD is trained by minimizing the negative log-likelihood and our proposed regularization term, maximum component maximization (MCM) loss that prevents duplicated predictions. During training, no additional procedure such as bipartite matching is needed, and the loss is directly computed from the network outputs. Moreover, our Sparse MDOD outperforms the existing detectors on MS-COCO, a renowned multi-object detection benchmark.
KL-Divergence-Based Region Proposal Network for Object Detection
May 22, 2020

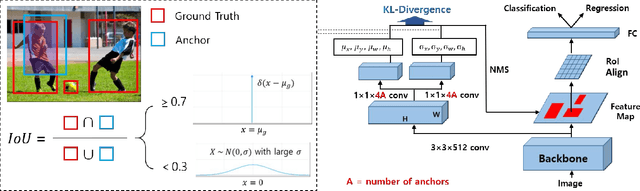

The learning of the region proposal in object detection using the deep neural networks (DNN) is divided into two tasks: binary classification and bounding box regression task. However, traditional RPN (Region Proposal Network) defines these two tasks as different problems, and they are trained independently. In this paper, we propose a new region proposal learning method that considers the bounding box offset's uncertainty in the objectness score. Our method redefines RPN to a problem of minimizing the KL-divergence, difference between the two probability distributions. We applied KL-RPN, which performs region proposal using KL-Divergence, to the existing two-stage object detection framework and showed that it can improve the performance of the existing method. Experiments show that it achieves 2.6% and 2.0% AP improvements on MS COCO test-dev in Faster R-CNN with VGG-16 and R-FCN with ResNet-101 backbone, respectively.
Mixture-Model-based Bounding Box Density Estimation for Object Detection
Nov 28, 2019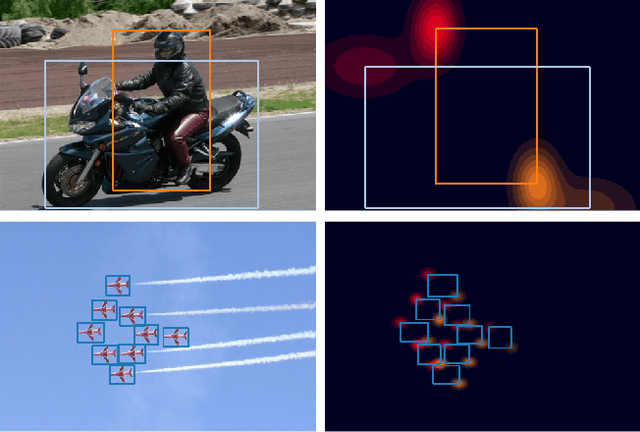
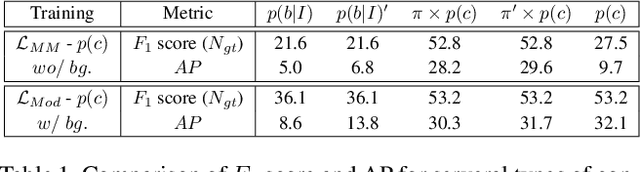
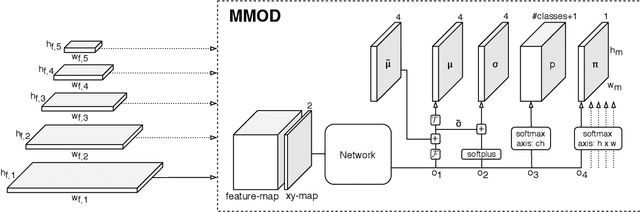
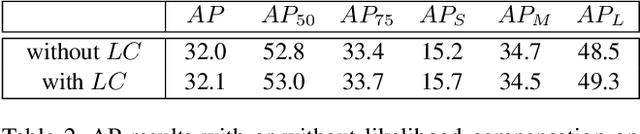
In this paper, we propose a new object detection model, Mixture-Model-based Object Detector (MMOD), that performs multi-object detection using a mixture model. Unlike previous studies, we use density estimation to deal with the multi-object detection task. MMOD captures the conditional distribution of bounding boxes for a given input image using a mixture model consisting of Gaussian and categorical distributions. For this purpose, we propose a method to extract object bounding boxes from a trained mixture model. In doing so, we also propose a new network structure and objective function for the MMOD. Our proposed method is not trained by assigning a ground truth bounding box to a specific location on the network's output. Instead, the mixture components are automatically learned to represent the distribution of the bounding box through density estimation. Therefore, MMOD does not require a large number of anchors and does not incur the positive-negative imbalance problem. This not only benefits the detection performance but also enhances the inference speed without requiring additional processing. We applied MMOD to Pascal VOC and MS COCO datasets, and outperform the detection performance with inference speed of other state-of-the-art fast object detection methods. (38.7 AP with 39ms per image on MS COCO without bells and whistles.) Code will be available.
Density Estimation and Incremental Learning of Latent Vector for Generative Autoencoders
Feb 12, 2019
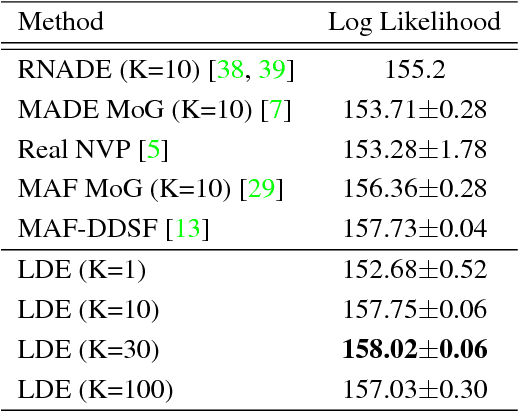
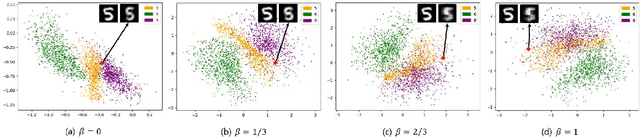
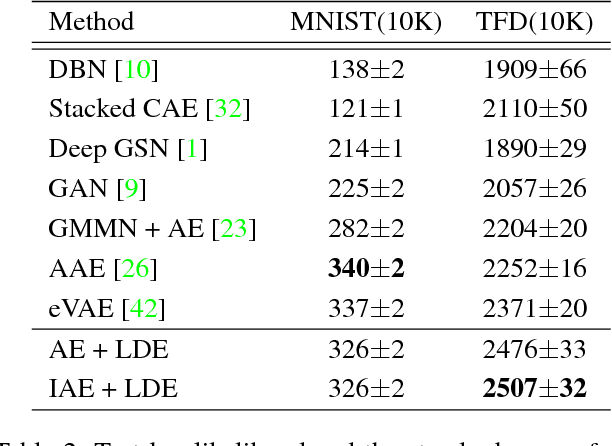
In this paper, we treat the image generation task using the autoencoder, a representative latent model. Unlike many studies regularizing the latent variable's distribution by assuming a manually specified prior, we approach the image generation task using an autoencoder by directly estimating the latent distribution. To do this, we introduce 'latent density estimator' which captures latent distribution explicitly and propose its structure. In addition, we propose an incremental learning strategy of latent variables so that the autoencoder learns important features of data by using the structural characteristics of under-complete autoencoder without an explicit regularization term in the objective function. Through experiments, we show the effectiveness of the proposed latent density estimator and the incremental learning strategy of latent variables. We also show that our generative model generates images with improved visual quality compared to previous generative models based on autoencoders.
Generating objects going well with the surroundings
Jul 09, 2018
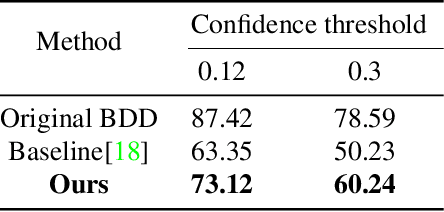


Since the generative adversarial network has made a breakthrough in the image generation problem, lots of researches on its applications have been studied such as image restoration, style transfer and image completion. However, there have been few researches generating objects in uncontrolled real-world environments. In this paper, we propose a novel approach for image generation in real-world scenes. The overall architecture consists of two different networks each of which completes the shape of the generating object and paints the context on it respectively. Using a subnetwork proposed in a precedent work of image completion, our model make the shape of an object. Unlike the approaches used in the image completion problem, details of trained objects are encoded into a latent variable by an additional subnetwork, resulting in a better quality of the generated objects. We evaluated our method using KITTI and City-scape datasets, which are widely used for object detection and image segmentation problems. The adequacy of the generated images by the proposed method has also been evaluated using a widely utilized object detection algorithm.
Image Restoration by Estimating Frequency Distribution of Local Patches
May 23, 2018
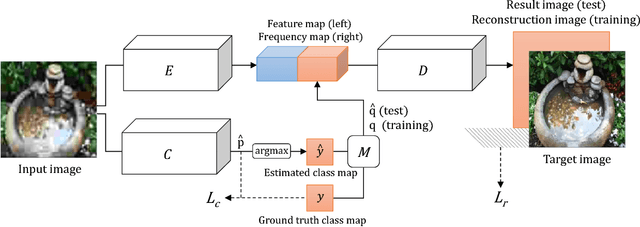
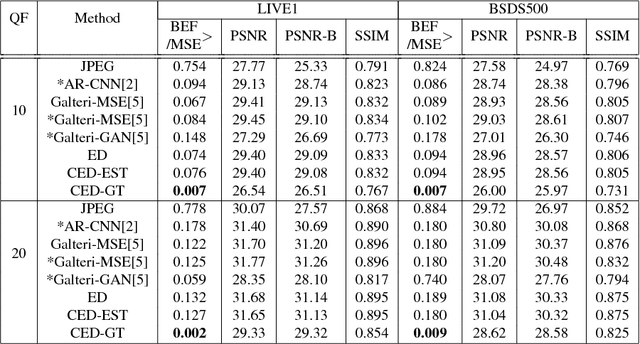
In this paper, we propose a method to solve the image restoration problem, which tries to restore the details of a corrupted image, especially due to the loss caused by JPEG compression. We have treated an image in the frequency domain to explicitly restore the frequency components lost during image compression. In doing so, the distribution in the frequency domain is learned using the cross entropy loss. Unlike recent approaches, we have reconstructed the details of an image without using the scheme of adversarial training. Rather, the image restoration problem is treated as a classification problem to determine the frequency coefficient for each frequency band in an image patch. In this paper, we show that the proposed method effectively restores a JPEG-compressed image with more detailed high frequency components, making the restored image more vivid.