 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Dataset Distillation Based on Deep Support Vectors
May 01, 2024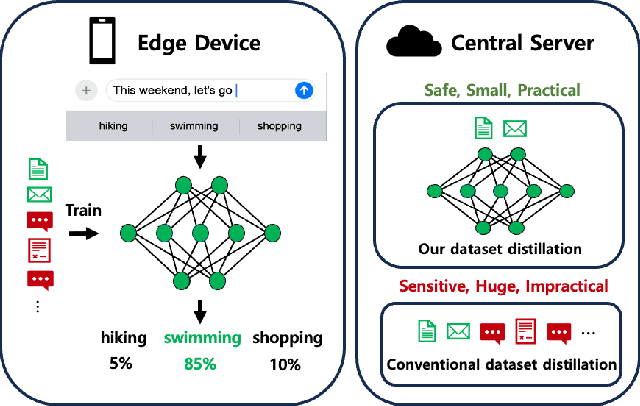
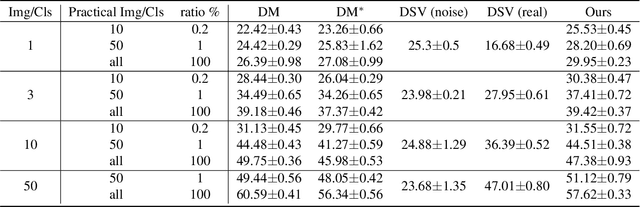


Conventional dataset distillation requires significant computational resources and assumes access to the entire dataset, an assumption impractical as it presumes all data resides on a central server. In this paper, we focus on dataset distillation in practical scenarios with access to only a fraction of the entire dataset. We introduce a novel distillation method that augments the conventional process by incorporating general model knowledge via the addition of Deep KKT (DKKT) loss. In practical settings, our approach showed improved performance compared to the baseline distribution matching distillation method on the CIFAR-10 dataset. Additionally, we present experimental evidence that Deep Support Vectors (DSVs) offer unique information to the original distillation, and their integration results in enhanced performance.
Coreset Selection for Object Detection
Apr 14, 2024



Coreset selection is a method for selecting a small, representative subset of an entire dataset. It has been primarily researched in image classification, assuming there is only one object per image. However, coreset selection for object detection is more challenging as an image can contain multiple objects. As a result, much research has yet to be done on this topic. Therefore, we introduce a new approach, Coreset Selection for Object Detection (CSOD). CSOD generates imagewise and classwise representative feature vectors for multiple objects of the same class within each image. Subsequently, we adopt submodular optimization for considering both representativeness and diversity and utilize the representative vectors in the submodular optimization process to select a subset. When we evaluated CSOD on the Pascal VOC dataset, CSOD outperformed random selection by +6.4%p in AP$_{50}$ when selecting 200 images.
Deep Support Vectors
Mar 26, 2024
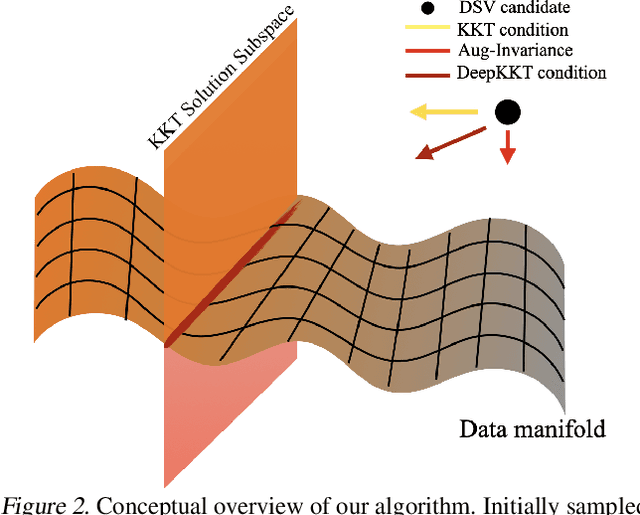
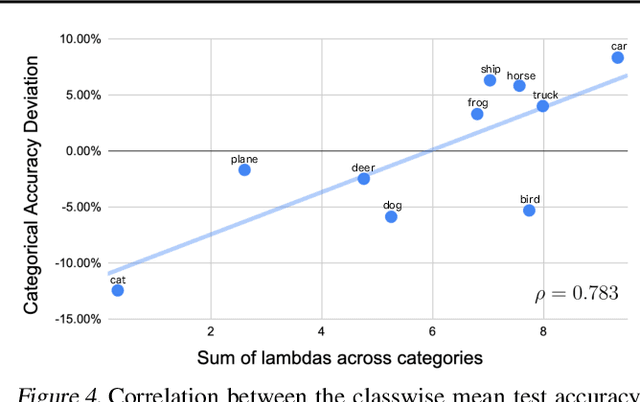
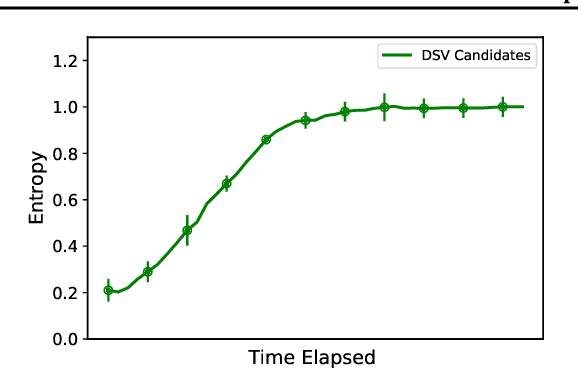
While the success of deep learning is commonly attributed to its theoretical equivalence with Support Vector Machines (SVM), the practical implications of this relationship have not been thoroughly explored. This paper pioneers an exploration in this domain, specifically focusing on the identification of Deep Support Vectors (DSVs) within deep learning models. We introduce the concept of DeepKKT conditions, an adaptation of the traditional Karush-Kuhn-Tucker (KKT) conditions tailored for deep learning. Through empirical investigations, we illustrate that DSVs exhibit similarities to support vectors in SVM, offering a tangible method to interpret the decision-making criteria of models. Additionally, our findings demonstrate that models can be effectively reconstructed using DSVs, resembling the process in SVM. The code will be available.
Any-Way Meta Learning
Jan 10, 2024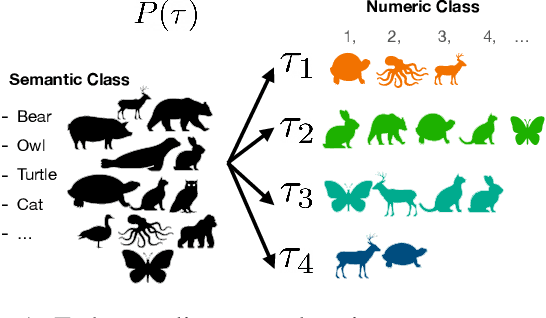
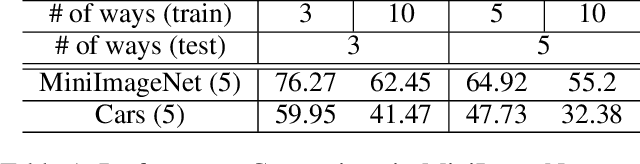
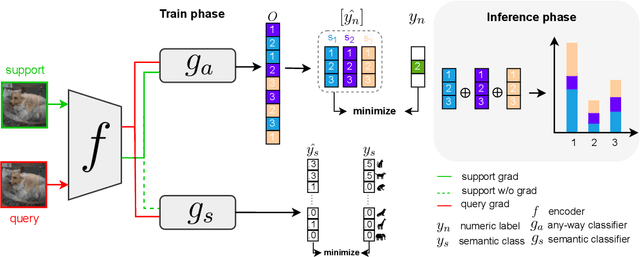
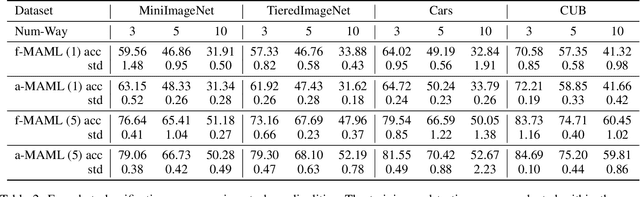
Although meta-learning seems promising performance in the realm of rapid adaptability, it is constrained by fixed cardinality. When faced with tasks of varying cardinalities that were unseen during training, the model lacks its ability. In this paper, we address and resolve this challenge by harnessing `label equivalence' emerged from stochastic numeric label assignments during episodic task sampling. Questioning what defines ``true" meta-learning, we introduce the ``any-way" learning paradigm, an innovative model training approach that liberates model from fixed cardinality constraints. Surprisingly, this model not only matches but often outperforms traditional fixed-way models in terms of performance, convergence speed, and stability. This disrupts established notions about domain generalization. Furthermore, we argue that the inherent label equivalence naturally lacks semantic information. To bridge this semantic information gap arising from label equivalence, we further propose a mechanism for infusing semantic class information into the model. This would enhance the model's comprehension and functionality. Experiments conducted on renowned architectures like MAML and ProtoNet affirm the effectiveness of our method.