 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Aware Quantization for LLM Safety
Nov 11, 2025Safety and efficiency are both important factors when deploying large language models(LLMs). LLMs are trained to follow human alignment for safety, and post training quantization(PTQ) is applied afterward for efficiency. However, these two objectives are often in conflict, revealing a fundamental flaw in the conventional PTQ paradigm: quantization can turn into a safety vulnerability if it only aims to achieve low perplexity. Models can demonstrate low perplexity yet exhibit significant degradation in alignment with the safety policy, highlighting that perplexity alone is an insufficient and often misleading proxy for model safety. To address this, we propose Alignment-Aware Quantization(AAQ), a novel approach that integrates Alignment-Preserving Contrastive(APC) loss into the PTQ pipeline. Compared to simple reconstruction loss, ours explicitly preserves alignment by encouraging the quantized model to mimic its safe, instruction-tuned model while diverging from the unaligned, pre-trained counterpart. Our method achieves this robust safety alignment without resorting to specialized safety-focused calibration datasets, highlighting its practical utility and broad applicability. AAQ is compatible with standard PTQ techniques and enables robust 4-bit (W4A4) quantization across diverse model families such as LLaMA, Qwen, and Mistral while maintaining safety where previous methods fail. Our work resolves the critical trade-off between efficiency and safety, paving the way toward LLMs that are both efficient and trustworthy. Anonymized code is available in the supplementary material.
Unlocking the Potential of Unlabeled Data in Semi-Supervised Domain Generalization
Mar 18, 2025We address the problem of semi-supervised domain generalization (SSDG), where the distributions of train and test data differ, and only a small amount of labeled data along with a larger amount of unlabeled data are available during training. Existing SSDG methods that leverage only the unlabeled samples for which the model's predictions are highly confident (confident-unlabeled samples), limit the full utilization of the available unlabeled data. To the best of our knowledge, we are the first to explore a method for incorporating the unconfident-unlabeled samples that were previously disregarded in SSDG setting. To this end, we propose UPCSC to utilize these unconfident-unlabeled samples in SSDG that consists of two modules: 1) Unlabeled Proxy-based Contrastive learning (UPC) module, treating unconfident-unlabeled samples as additional negative pairs and 2) Surrogate Class learning (SC) module, generating positive pairs for unconfident-unlabeled samples using their confusing class set. These modules are plug-and-play and do not require any domain labels, which can be easily integrated into existing approaches. Experiments on four widely used SSDG benchmarks demonstrate that our approach consistently improves performance when attached to baselines and outperforms competing plug-and-play methods. We also analyze the role of our method in SSDG, showing that it enhances class-level discriminability and mitigates domain gaps. The code is available at https://github.com/dongkwani/UPCSC.
Do not think pink elephant!
Apr 22, 2024Large Models (LMs) have heightened expectations for the potential of general AI as they are akin to human intelligence. This paper shows that recent large models such as Stable Diffusion and DALL-E3 also share the vulnerability of human intelligence, namely the "white bear phenomenon". We investigate the causes of the white bear phenomenon by analyzing their representation space. Based on this analysis, we propose a simple prompt-based attack method, which generates figures prohibited by the LM provider's policy. To counter these attacks, we introduce prompt-based defense strategies inspired by cognitive therapy techniques, successfully mitigating attacks by up to 48.22\%.
Deep Support Vectors
Mar 26, 2024
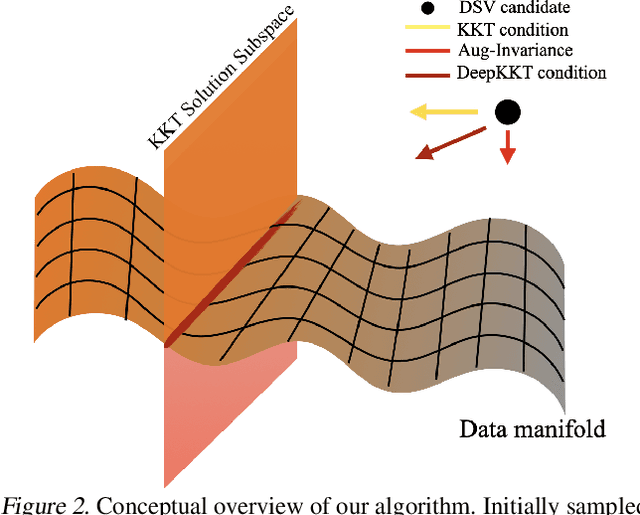
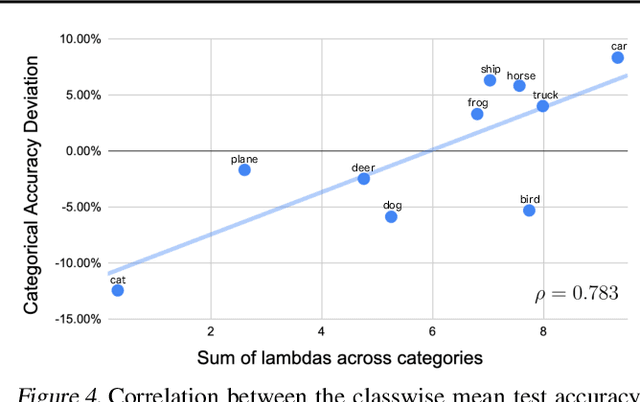
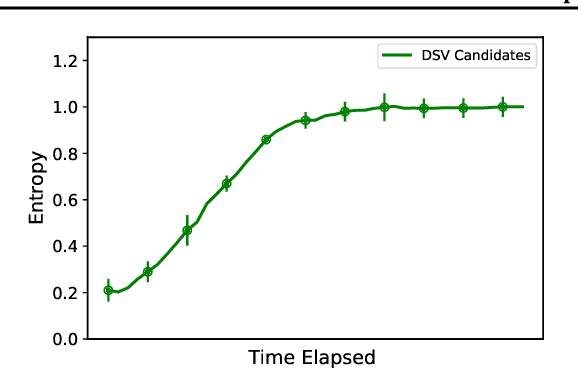
While the success of deep learning is commonly attributed to its theoretical equivalence with Support Vector Machines (SVM), the practical implications of this relationship have not been thoroughly explored. This paper pioneers an exploration in this domain, specifically focusing on the identification of Deep Support Vectors (DSVs) within deep learning models. We introduce the concept of DeepKKT conditions, an adaptation of the traditional Karush-Kuhn-Tucker (KKT) conditions tailored for deep learning. Through empirical investigations, we illustrate that DSVs exhibit similarities to support vectors in SVM, offering a tangible method to interpret the decision-making criteria of models. Additionally, our findings demonstrate that models can be effectively reconstructed using DSVs, resembling the process in SVM. The code will be available.
Mitigating the Bias in the Model for Continual Test-Time Adaptation
Mar 02, 2024
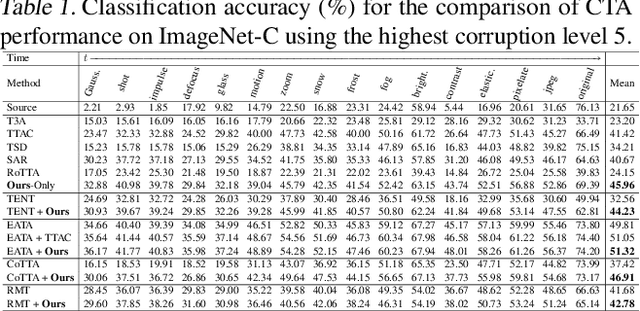
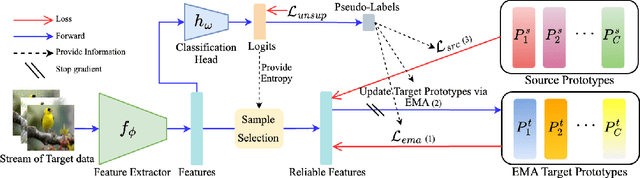
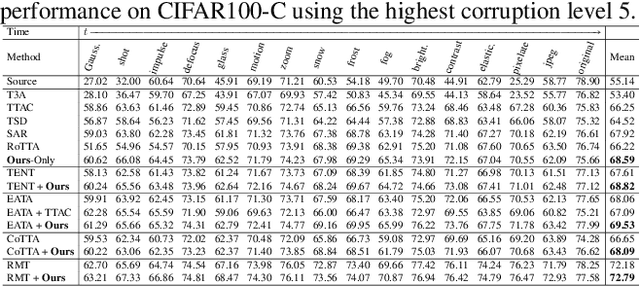
Continual Test-Time Adaptation (CTA) is a challenging task that aims to adapt a source pre-trained model to continually changing target domains. In the CTA setting, a model does not know when the target domain changes, thus facing a drastic change in the distribution of streaming inputs during the test-time. The key challenge is to keep adapting the model to the continually changing target domains in an online manner. We find that a model shows highly biased predictions as it constantly adapts to the chaining distribution of the target data. It predicts certain classes more often than other classes, making inaccurate over-confident predictions. This paper mitigates this issue to improve performance in the CTA scenario. To alleviate the bias issue, we make class-wise exponential moving average target prototypes with reliable target samples and exploit them to cluster the target features class-wisely. Moreover, we aim to align the target distributions to the source distribution by anchoring the target feature to its corresponding source prototype. With extensive experiments, our proposed method achieves noteworthy performance gain when applied on top of existing CTA methods without substantial adaptation time overhead.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.